здЖЏДцДЂЗжВуКЭNetApp ащФтДцДЂВу
Paul Feresten&Rajesh Sundaram ЗЂБэгкЃК11Фъ06дТ03Ше 11:42 [РДИх] ДцДЂдкЯп
вдЯТМИИівђЫиЛсгАЯь AST НтОіЗНАИЪЕЯжЩЯЪіФПБъЕФФмСІЃК
·Ъ§ОнДцДЂЕФСЃЖШШчКЮЃПДІРэЕФЪ§ОнПщдНаЁЃЌгУгкДцДЂЪ§ОнЕФЯЕЭГКЭ HDD зЪдДЕФаЇТЪОЭдНИпЃЌВЂЧвРфЪ§Он“ИњЫц”ШШЪ§ОнвЦЖЏВЂКСЮовцДІЕиКФгУАКЙѓНщжЪЕФПЩФмадвВдНаЁЁЃ
·ШчКЮЪЖБ№ШШЪ§ОнвдМАЫйЖШМгПьСЫЖрЩйЃПШШЪ§ОнНјШыЩСДцЕФЫйЖШдНПьЃЌДэЙ§ I/O ЛюЖЏжаЯрЖдЖЬднЕФИпЗхЦкЕФПЩФмадОЭдНаЁЃЌашвЊЕФ HDD I/O ОЭдНЩйЃЌВЂЧвЦНОљбгГйЪБМфЫѕЖЬЕФЗљЖШОЭдНДѓЁЃ
ДгВйзїНЧЖШРДПДЃЌЛЙашвЊПМТЧвдЯТМИИівђЫиЃК
ВПЪ№КЭЙмРэИУНтОіЗНАИЕФФбЖШШчКЮЃПШчЙћВПЪ№ AST НтОіЗНАИашвЊНјаажиДѓЕФжиаТХфжУЃЌЛђашвЊДѓСПЕФМрПиКЭЙмРэЃЌФЧУДПЩФмЛсЕУВЛГЅЪЇЁЃ
ИУНтОіЗНАИШчКЮгыФњЪЙгУЕФЦфЫћДцДЂММЪѕЃЈБИЗнЁЂжиИДЪ§ОнЩОГ§ЁЂОЋМђХфжУЕШЃЉМЏГЩЃПФњвЛЖЈВЛЯЃЭћдкВПЪ№вЛИіНтОіЗНАИжЎКѓЃЌЗЂЯжБИЗнВЛФмжДааЃЌЛђепЫфШЛФмжДааЃЌЕЋШДашвЊДѓСПЕивЦЖЏЪ§ОнЁЃ
ЪЕЯж AST ЕФСНжжВЛЭЌЗНЪНЃКЧЈвЦгыЛКДц
ЪЕЯж AST гаСНжжБОжЪЩЯВЛЭЌЕФЗНЪНЃКЧЈвЦКЭЛКДцЁЃ
ЛљгкЧЈвЦЕФ AST ПЩздЖЏЛЏЪ§ОнЧЈвЦЕФСїГЬЁЃЕБвЛИіЪ§ОнПщБЛШЗЖЈЮЊ“ШШ”Ъ§ОнЪБЃЌЛсНЋИУЪ§ОнПщвЦжСЫйЖШНЯПьЕФНщжЪЃЌЕБИУЪ§ОнПщБф“Рф”ЪБЃЌЛсНЋЦфвЦЛиЫйЖШНЯТ§ЕФНщжЪЁЃвЦШыКЭвЦГіЩСДцЖМашвЊЗУЮЪ HDDЁЃ
ЛљгкЛКДцЕФ AST ЪЙгУЙуЮЊШЫжЊЕФЛКДцЗНЪННЋШШЪ§Он“ЬсЩ§”ЕНИпадФмЕФНщжЪжаЁЃгЩгк HDD ЩЯШдБЃСєгаЪ§ОнЕФИББОЃЌвђДЫЕБЪ§ОнБф“Рф”ЪБЃЌжЛашНЋЦфДгЛКДцжаЪЭЗХМДПЩЃЌЖјВЛашвЊЖюЭтЕФ HDD I/OЁЃ
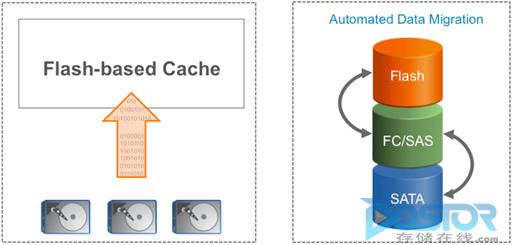
ЭМ 3ЃЉ ЛљгкЛКДцЕФздЖЏДцДЂЗжВугыЛљгкЧЈвЦЕФздЖЏДцДЂЗжВуЁЃ
NetApp ащФтДцДЂВу
ИљОнЮвУЧЧАУцЬжТлЕФЦРМлБъзМЃЌNetApp ПМВьСЫетСНжжЪЕЯж AST ЕФЗНЪНЃЌВЂЕУГівдЯТНсТлЃКЛљгкЛКДцЕФ AST ЗНЪНИќЗћКЯетаЉБъзМЕФвЊЧѓЁЃ



