
【编者按:2025年3月27日,“2025人工智能基础设施峰会”在上海龙之梦万丽酒店盛大召开。本次峰会以“智能基石 创新赋能”为主题,由上海市计算机学会指导,DOIT传媒主办,算力豹、百易存储研究院、CXL技术应用俱乐部、上海市计算机学会存储技术专委会、上海交通大学计算机系支持,汇聚产业链上下游企业、机构及专家学者,共同探讨AI基础设施的前沿趋势、技术创新与应用,推动中国AI产业迈向新高度,会议同期还发布了算力全景图(2025版)分析报告。会场吸引近千名观众参加。

“2025人工智能基础设施峰会”会场
在下午召开的数据智能技术应用论坛上,上海交通大学计算机科学与工程系教授、博士生导师,国家级青年人才、国家重点研发计划首席科学家、CCF体系结构专委会常委,上海市计算机学会存储专委会主任吴晨涛发表主题为“面向大模型应用的内存故障容错技术”的精彩报告,从内存故障预测与检查点等技术入手,介绍他和他的已经研究团队如何通过主被动容错方法,保障大模型系统的可靠性。发表主题为“面向大模型应用的内存故障容错技术”的精彩报告,从内存故障预测与检查点等技术入手,介绍他和他的已经研究团队如何通过主被动容错方法,保障大模型系统的可靠性。

数据智能技术应用分论坛现场
以下内容根据速记整理,未经本人审定。

上海交通大学计算机科学与工程系教授、博士生导师,国家级青年人才、国家重点研发计划首席科学家、CCF体系结构专委会常委,上海市计算机学会存储专委会主任吴晨涛
吴晨涛:
大家好,我是来自上海交通大学的吴晨涛。今天,我将围绕“面向大模型应用的内存故障容错技术”这一主题,与大家分享我们在内存故障预测与容错技术方面的最新研究成果。
研究背景与发现
随着云计算、大数据等系统的快速扩展和规模日益增大,内存系统的可靠性已成为影响整个系统运行的重要因素。京东云的调查表明,内存故障占数据中心硬件故障的37%。在AIGC算力快速部署的当下,内存可靠性面临着更为严峻的挑战。
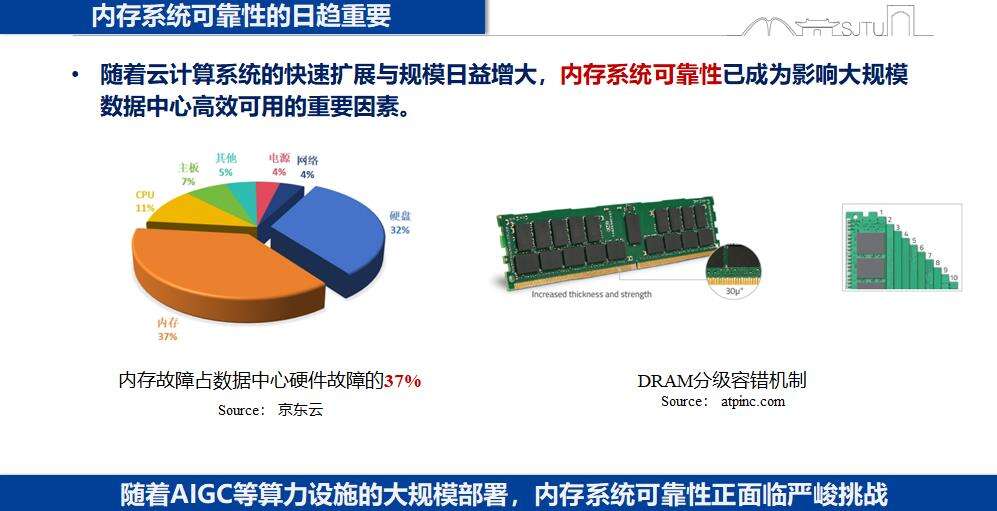
在大模型训练中,内存故障问题尤为突出。以Meta公司为例,其利用992张A100集群训练175B参数模型,在3个月的训练时长中,系统重启超过100次,最长稳定运行时间仅为2.8天,最长中断达2天,平均中断时长12小时,其中硬件故障占50%。若以ETTR(有效训练时间比率)衡量,GPU越多,ETTR值越低,万卡集群平均有效运行时间仅占正常时间的70%。随着DeepSeek等大模型应用的广泛使用,内存可靠性的挑战只会增多,不会减少。
内存故障预测
内存故障预测是智能运维系统(AIOps)的重要组成部分,谷歌、微软、华为、阿里等公司均致力于发展内存故障预测技术。内存故障模式多样,包括单点错误模式、行错误模式、列错误模式和无序错误模式等。内存一般配有ECC编码,若错误在编码容忍范围内,可纠正回来,称为CE(CorrectableError);若错误超出编码容错能力,则称为UC/UCE(UncorrectableError)。
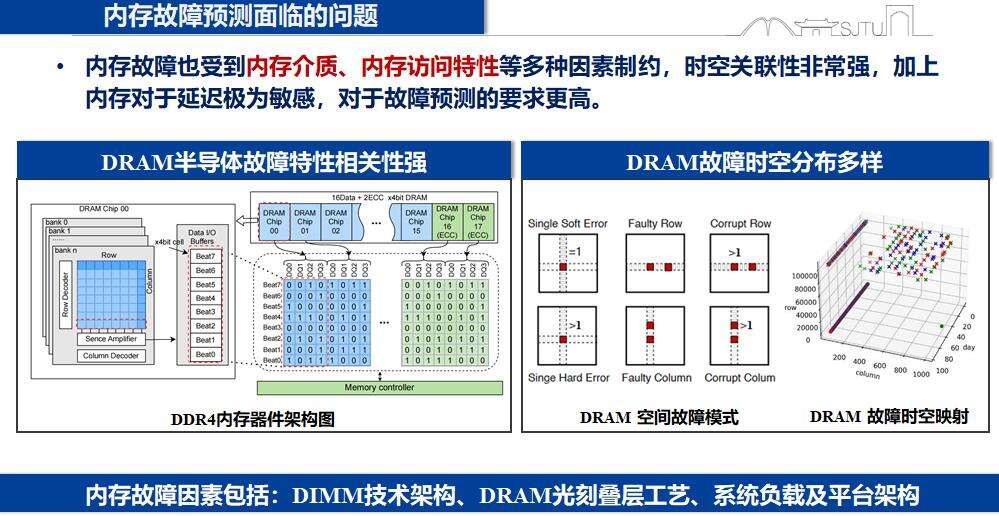
内存故障模式种类繁多,故障原因多样,给故障预测带来了很大难度。我们与华为合作,从row、col、bank三个维度进行三维空间分析,针对发生故障的所有内存单元进行跟踪,分析三维模型。以24小时为周期划分每个bank力度上的UE和CE信息,观察其时间规律,并以红、蓝、绿三色进行标注,发现row、column、bank这三个维度的内存故障均呈现非常明显的时间和空间局部性。
影响内存故障的主要因素包括DIMM架构、DRAM光刻叠层工艺、系统负载和平台架构等。内存故障与内存介质、内存访问特性相关度极高,且内存对延迟要求极为敏感,因此对故障预测的要求更高。
基于以上分析,我们与华为合作,针对大规模华为云集群环境中的内存故障预测展开研究。通过对12万台服务器、近200万条内存故障日志的分析,我们发现不同架构平台的内存故障特性存在显著差异。例如,在x86架构的服务器中,只发生UE的内存比例约为11%,而在Arm架构下则仅为4%,约为x86的1/3。进一步研究发现,Arm服务器在ECC编码中保留了更多的奇偶校验位,使得其在4bit位宽时能达到Chipkill级性能,但在8bit位宽时难以应对大量错误,导致错误率急剧上升。
此外,我们还分析了内存故障的可预测性。研究发现,Arm架构在较短提前时间(如6小时)内,可预测UE的生存函数概率值略高于x86服务器,但在较长提前时间(如24小时)内,x86架构表现出更高比例的可预测UE。同时,x86和Arm平台之间CE与UE的关系也存在差异,x86服务器在出现不可纠正错误前,通常会有大量可纠正错误,而Arm服务器则表现不一致,这可能与其风暴抑制功能有关,该功能虽然增强了系统稳定性,却减少了用于故障预测的错误数据量。
针对内存故障成因复杂的特点,我们采用了特征工程方法,兼顾时间局部性、空间局部性等多方面特征,包括静态特征、空间特征、时间特征、类型特征、故障位特征等,构建了统一的针对大规模异构集群的内存故障预测与分级容错架构。该架构从DIMM级、服务器级、页面级、行级分别进行粗粒度和细粒度的故障预测,并针对故障预测结果设计了相应的容错机制:一是针对服务器的虚拟机或容器进行热迁移;二是对对应内存的页面进行软下线;三是对风险区域进行数据保护和降级使用。
实验结果
我们在系统中提供了针对DIMM级以及行级、页级双视角的内存故障预测方法,结合XGBoost等算法,取得了较好的效果。在x86平台,实现了51%的精准率和81%的覆盖率;而在Arm平台,由于其风暴抑制和奇偶校验位等功能导致缺少细粒度故障信息,内存故障预测性能相对较低。
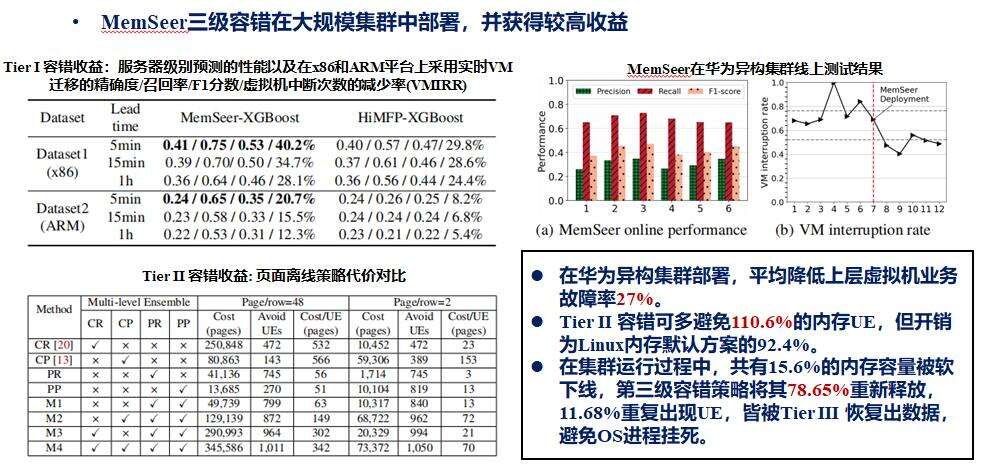
进一步的实验分析了不同提前时间下预测性能的变化,发现无论是提前1秒、5秒、1分钟、5分钟、1小时还是6小时等,均能达到一定的预测效果。这些成果已在华为云中进行了部分落地应用。
针对x86和Arm架构的差异,我们测试了不同因素对这两个平台内存故障预测性能的影响。在x86架构中,bitlevel的CE特征占主导地位,去除该特征会导致性能显著下降;而在Arm架构中,静态特征、局部特征和空间特征等对预测性能均有不同程度的影响,其中空间特征的影响最大。整体而言,在Arm架构上进行内存故障预测更具挑战性。
我们将容错机制在华为云集群中进行了大规模部署,取得了显著收益。部署后,平均降低了上层虚拟机业务故障率27%;采用第二级容错时,可多避免110.6%的内存UE,但开销仅为Linux内存默认方案的92.4%;在集群运行过程中,共有15.6%的内存容量被软下线,通过三级容错策略,重新释放了其中78.65%的容量,剩余11.68%的重复出现UE的区域,皆被TierIII恢复数据,避免了OS进程挂死。
总结与展望
我们针对内存故障预测问题开展了深入研究,特别是针对大规模集群的硬件故障,通过特征工程方法构建了DIMM/行列级分级容错机制,有效降低了上层虚拟机业务的故障率,保障了大规模系统的稳定性,为AIGC技术的发展提供了有力支持。
未来,我们将进一步拓展研究方向。一方面,将故障预测与大模型的Checkpoint机制相结合,构建主被动分级容错技术,以更好地保障AI应用的可靠性;另一方面,深入研究存储子系统容错技术,探讨DRAM、PM、SSD/HDD等设备故障之间的相关性,并进一步探究内存故障对上层应用业务的影响范围。此外,随着CXL等相关技术的实施,我们还将研究针对CXL-DRAM/PM等的故障预测技术,为构建大规模内存池提供技术支持。
以上就是我的报告,谢谢大家!





