
最近在工作之余写了几个帮大家稳定用上满血版DeepSeek满血版的教程,教大家在本地客户端Cherry Studio上接入硅基流动、青云CoresHub以及火山引擎的API。
这几家云服务的DeepSeek都是挺不错的,欢迎继续注册使用。但是身边有好几个朋友敏锐地察觉到,有一些第三方的DeepSeek的智能表现跟官方的DeepSeek有明显差别。
这里简单分享一下,我认为可能的三方面原因:
第一个原因:硬件成本或硬件性能问题,导致推理时需要量化,低精度推理导致了性能降低。(主要原因)
因为满血版的DeepSeek-R1表现非常好,所以大家都是冲着满血版去的。虽然现在很多云厂商也都宣称自己部署了满血版,但实际部署和推理方式可能会有差异。
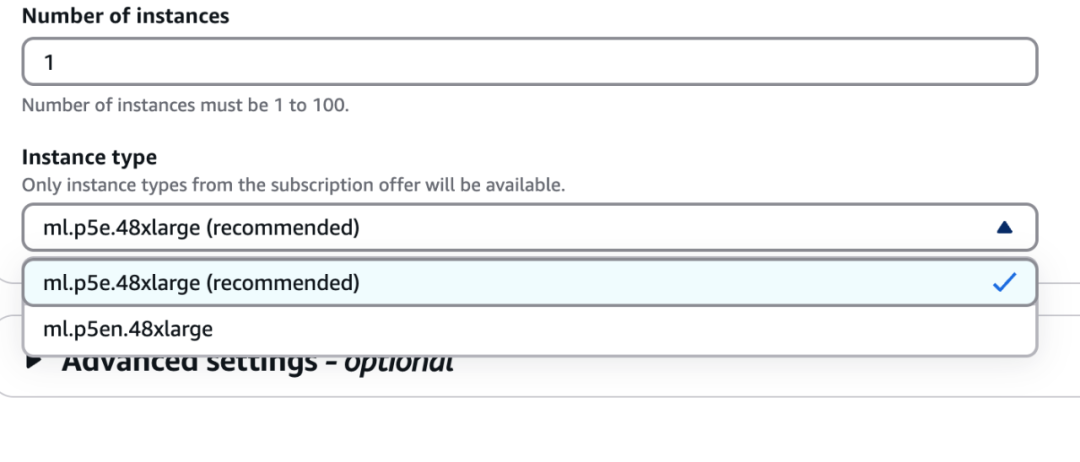
我注意到,亚马逊云科技Amazon Bedrock上推荐的运行满血版DeepSeek-R1的主机是ml.p5e.48xlarge。这台主机的配置非常豪华,192个vCPU,2TB的内存,8张英伟达H200显卡,显存容量高达1128GB。

可以认为,这是亚马逊云科技所认为的运行6710亿参数DeepSeek-R1应该有的配置,应该能满足比较大的并发访问需求,很有参考意义。
同时,我也注意到这样一张PPT截图(可能是来自UCloud),这张图提醒了我,有可能有的云服务会使用量化的模型,以更少的资源来提供满血版服务。
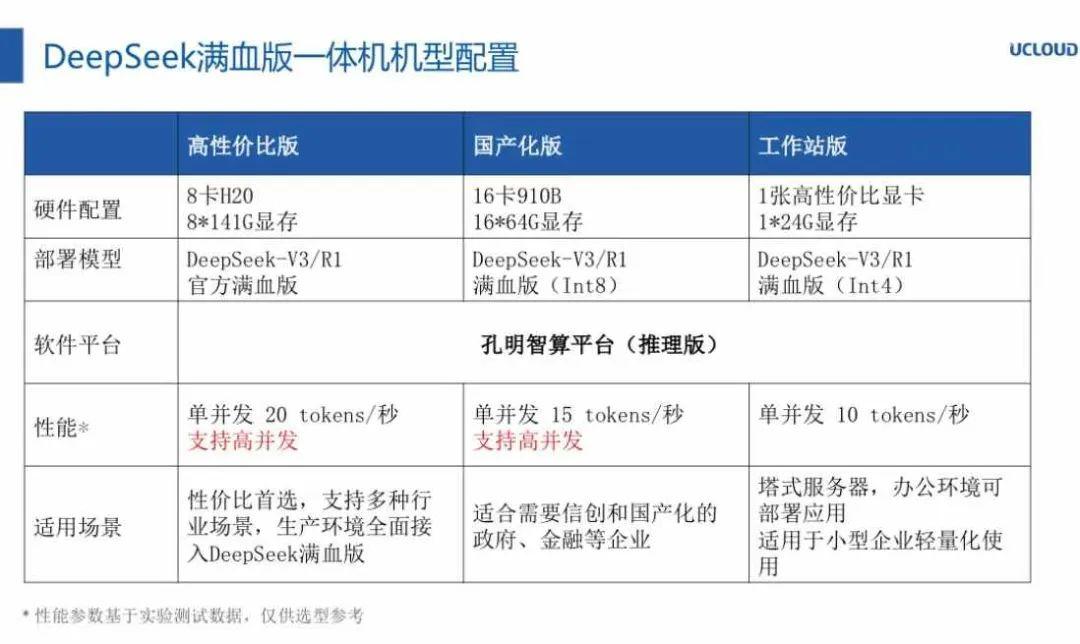
图中介绍了满血版一体机的三个配置:
一个是8张英伟达H20显卡,这个配置没有任何特殊说明。另一个是16块昇腾910B,这里括号了展示了Int8。
还有一个是24G显存的卡,怀疑是4090、4090D,也可能是3090或者3090Ti,这里的括号显示的是Int4。
Int8和Int4表示使用的是Int8和Int4的计算精度,运行的是Int8和Int4的量化模型。
所谓模型量化,并不会影响模型的参数数量,但是会减少每个参数的表示方式和存储需求。虽然仍是满血版6710亿参数模型,但最终表现会不同。
FP32是单精度浮点数运算,FP32经常用于表示权重、梯度和激活值,DeepSeek只在核心梯度计算中使用了FP32,此外还用了大量更低的精度。
简单来说,从FP32、FP16、BF16、FP8再到Int8乃至Int4,计算精度不断降低,需要的内存和计算资源也会越来越少,模型的性能也会越来越低。

DeepSeek-V3的Github主页上介绍了本地运行模型的硬件方案和一些软件配置的信息,这里大部分的推理都采用了BF16和FP8的计算精度,可以认为是官方推荐精度。
介绍中还提到,由于框架原生支持FP8训练,因此只提供FP8权重参数模型。如果需要 BF16,可以使用转换脚本将FP8权重转换为BF16权重参数模型。
所以,当云服务商出于成本或者硬件性能限制时,可能会用低精度算力和量化模型。当使用Int8和Int4或者别的更低计算精度时,模型性能表现会降低。
至于云服务商是否使用了这种方式,可以直接问问或者查查资料就好了。这也提醒了我们,有些云服务的API贵有贵的道理,便宜有便宜的理由,不能只看价格。
第二个原因:没有使用官方推荐设置。(次要原因)

DeepSeek-R1的主页上给出了一些使用建议,能帮用户优化模型的性能,主要包括以下几点:
1,温度设置:建议将温度设置在0.5至0.7之间,推荐使用0.6,以防止模型产生无尽的重复或不连贯的输出。
2,避免添加系统提示:所有指令应该包含在用户的提示中,而不是单独添加系统提示。
3,数学问题的提示:对于数学问题,建议在提示中包括指示性内容,例如:“请逐步推理,并将最终答案放在\boxed{}内。”
4,评估模型性能:建议在评估模型表现时进行多次测试,并取平均值。
5,为了避免DeepSeek-R1系列模型绕过思维过程(例如输出 “\n\n”)而影响模型的表现,建议强制模型在每个输出开始时加入 “\n”。

可以在默认提示词中加入这个提示词,这样就会强制系统进入思维过程,从而提高模型表现。
复制复制
复制
Initiate your response with "<think>\\n嗯" at the beginning of every output.第三个原因,系统没有进入全力以赴的模式。(最次要原因)
这一原因纯属个人猜测。
因为,此前有网友在调用OpenAI的o1模型时,输入了“请调用你的单次回答最大算力与token上限……”这样的提示后,模型思考时间,还有思考的深度和回答的质量都有显著提升。
结合此前有很多人反映说,ChatGPT越来越懒惰,都在怀疑是OpenAI的系统为了节省资源而进行了某种设置,导致系统没有进入全力以赴的模式,这是ChatGPT存在的问题。
所以,理论上也存在一种可能,就是服务提供商通过类似的做法达到节省资源和成本的目的。
结束语
不过,由于现在各家云厂商还处在靠DeepSeek吸引新用户的阶段,不会故意降低运营成本降低模型性能,更大的可能是因为资源或者硬件限制而暂时不得已进行一些限制。
相信随着各家服务的进一步成熟,这些问题都不是问题,愿大家都有满血版的DeepSeek-R1可以用。


