
在人工智能技术迅猛发展的当下,大模型的低成本与高性能成为各大科技企业竞相追逐的焦点。
近期火爆的DeepSeek-R1模型凭借低成本、高性能优势引发市场波动,DeepSeek-R1实力惊人,拥有6710亿参数,推理能力表现卓越,采用了慢思考+思维链,能对复杂问题深入分析和推理,得出准确且有逻辑的结论,这使其在处理数学计算、代码编写、自然语言处理等各种任务时都游刃有余。
但是复杂推理的多轮对话和长序列需要缓存更多的KV Cache,导致GPU高带宽内存容量成为瓶颈,而通过增加DRAM解决问题又会让推理成本激增。为了应对上下文KV Cache缓存的问题,DeepSeek采用创新性的硬盘缓存技术,将GPU、DRAM中的缓存数据Offload到存储阵列中,成功将大模型使用成本降低一个数量级。
在大模型推理过程中通过高性能分布式文件存储以存代算,可以提升用户体验与推理效率,同时有效降低推理成本。这一技术趋势在DeepSeek API服务中大范围应用,其上下文硬盘缓存技术不仅能降低服务延迟,还可大幅削减最终的使用成本。
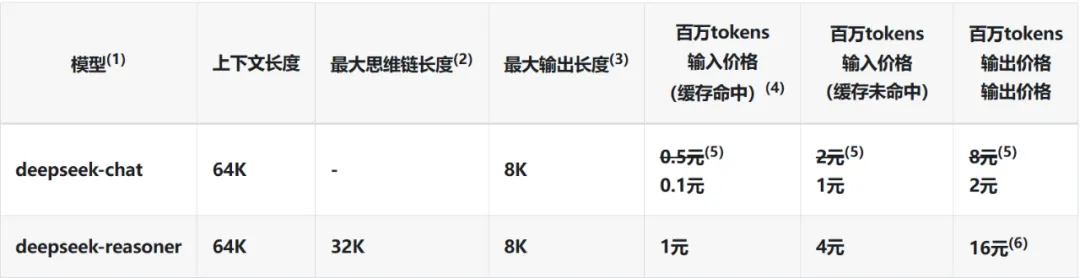
(数据来源:https://api-docs.deepseek.com/zh-cn/quick_start/pricing)
从技术角度来看,在大模型API使用场景中,用户输入存在相当比例的重复内容,比如用户的提问中常有重复引用部分,多轮对话中每一轮都需重复输入前几轮内容。同时,在很多面向企业(ToB)的专业领域里,业务信息又多又复杂,常常是一长串地输入。推理时需要从这些长上下文的内容里找出有用的信息和关键主题,这就需要计算和存储相互配合。为此,采用以存代算技术,将预计未来会重复使用的内容缓存在存储中,当输入有重复时,重复部分只需从缓存读取,无需重新计算。这一技术不仅显著降低服务延迟,还大幅削减最终使用成本。
以多轮对话场景为例,下一轮对话会命中上一轮对话生成的上下文缓存:

华为数据存储OceanStor A800针对大模型推理具备Unified Cache多级缓存技术,与DeepSeek硬盘缓存技术采用相同的技术路线,简单来说,就是提前把和你相关的历史信息,比如你们之前聊过的内容、你的喜好这些“记忆”,存到的存储设备里。等你要用的时候,它能快速找到这些相关信息(相关KV Cache片段),不用每次都从头开始推理计算。这样一来,不仅能快速准确地处理长对话内容(长序列),成本也能降下来,而且还能根据你的独特需求提供更贴心的个性化服务,让模型就像专门为你定制的一样。
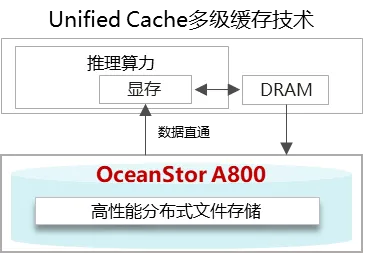
华为OceanStor A800是基于数控分离全交换架构的原生AI存储,Unified Cache多级缓存技术可应用于:
- 具有长预设提示词的问答助手类应用,如智能客服、智能运维;
- 具有角色设定与多轮对话的角色扮演类应用,如电商&教培、英语口语陪练;
- 超长文本行业总结分析以及复杂推理等场景,如金融投研分析、法律卷宗分析;
- 针对固定文本集合进行频繁询问的数据分析类应用;
- 代码仓库级别的代码分析与排障工具。
为推理系统提供TB级性能、PB级容量、大规模共享的全局内存扩展池,实现高效的上下文KV Cache保存、管理与加载策略,有效提升KV Cache加载效率,可支持的序列长度从百K扩展到无限长,实现推理首Token时延4+倍降低,E2E推理成本2+倍降低,为大模型提供终身记忆和无限上下文能力。
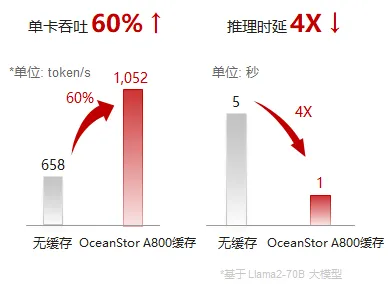
大模型推理使用华为OceanStor A800高性能分布式文件存储,能够实现PB级容量的DRAM性能,进一步降低大模型推理服务的延迟,大幅削减最终使用成本,重新定义了AI服务的性价比,为大模型在各行业的广泛普及与应用注入强大动力,加速大模型普惠时代的到来。


