
VAST Data 联合创始人 Jeff Denworth 在 X上发文表示:
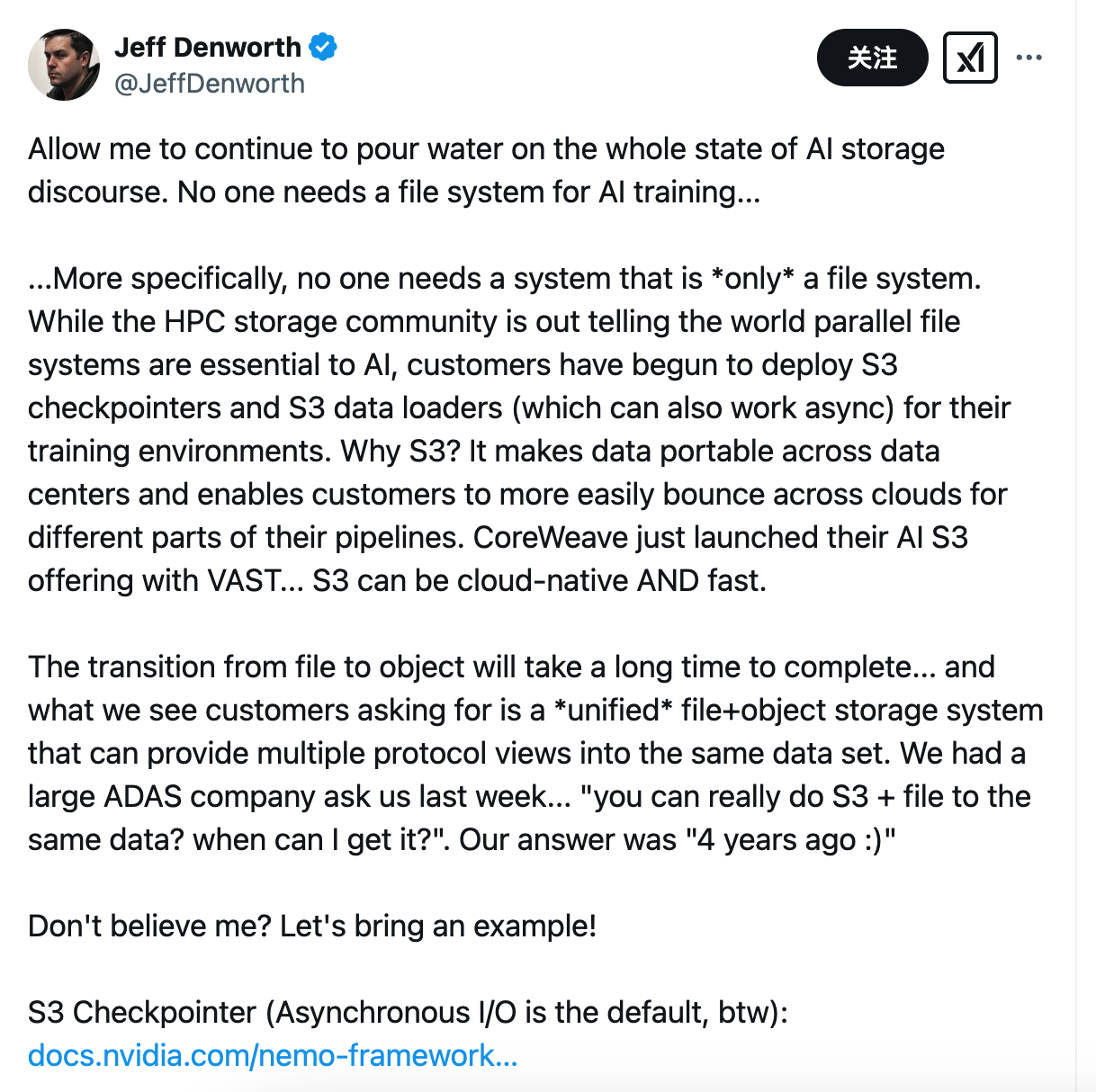
“AI 训练根本不需要文件系统……更具体地说,没有人需要一个仅仅是文件系统的系统。当 HPC 存储行业向世界宣称并行文件系统对 AI 至关重要时,客户实际上已经开始在训练环境中部署 S3 检查点和 S3 数据加载器(这些也可以异步工作)。”
随后,Blocks & Files的Chris Mellor撰文,分享了向 Denworth 提出的一些问题。
Blocks & Files:请问为什么英伟达、 X.ai都在用DDN的文件存储?在 AI 训练中使用文件系统?
Jeff Denworth:这不是“非此即彼”的问题,而是一个进化的过程。过去,所有 AI 训练框架都需要 POSIX/文件接口。只有那些开发自己框架的公司才会考虑使用对象存储,而这些公司都是行业顶尖的佼佼者。
并不是说文件系统已经被淘汰,而是说如今需要多协议支持,否则单一文件系统将导致极差的投资回报。框架的演进速度比客户的投资决策更快。如今,客户正在开始过渡,我们经常听到他们表示很喜欢在同一数据上同时支持多种访问模式的能力。
别忘了,英伟达也收购了一家对象存储公司(SwiftStack),这已经说明了很多问题。
Blocks & Files:有没有大模型完全基于对象存储系统中的数据进行训练?
Jeff Denworth:是的。据我所知,VAST S3 被 CoreWeave 独家用于训练一个非常重要的模型,此外我们还有一些顶级客户正在进行实验。Azure Blob 也被用于训练某个重要模型。英伟达正在使用 S3 兼容存储来训练一个重要模型。
Blocks & Files:VAST 构建了一个专注于 AI 的软件栈——VAST Data Platform,但 OpenAI和其他生成式 AI公司已经证明,你只需要一个向量数据库和文件系统,就可以构建出智能聊天机器人。这是否意味着 VAST 的软件栈是多余的?
Jeff Denworth:集成一个解决方案是可行的,但这并不意味着它是“实际可行或高效的”。
VAST 通过打破传统存储的权衡,提供了最佳的 AI 数据检索方式。大多数企业处理的只是GB 级数据,而我们设想的是AI 嵌入式模型能够实时理解所有数据的时间性和相关性,数据被分块并向量化,达到万亿级向量规模,且无论向量空间大小,搜索时间始终保持恒定——这只有我们的架构能做到。
一个每秒可处理数十万到百万级文件,并实时索引数据的系统,所有数据更新即时传播到索引,确保企业永远不会看到陈旧数据。而且,该系统不需要昂贵的基于内存的索引,要实现这一切,你需要DASE(解耦存储架构,Disaggregated Storage Architecture)。
最后,底层数据源必须既可扩展,又符合企业级需求。目前除了 VAST,我不确定还有其他选择。
Blocks & Files:ChatGPT 这样的技术是否让 VAST 的软件栈变得不再必要?
Jeff Denworth:完全相反!“智能体应用”的崛起——即企业将计算放入 GPU 运行时间中——进一步增加了对我们技术的需求。我希望你们在思考这个问题时,不要只把 AI 和 RAG(检索增强生成)看作是聊天机器人。
未来的商业速度不会取决于人类处理数据的速度。英伟达计划在未来几年内部署 1 亿个 AI 代理,来增强 5 万名员工的能力,这些代理将共同协作,处理复杂的业务任务。你不认为这会突破传统存储和数据库系统的极限吗?
我看到的未来与你所看到的可能完全不同。一切都会围绕规模、GPU 计算时间,以及处理前所未有数据量的能力展开。Anthropic 的 Dario Amodei 也曾表示,未来计算需求将扩大100 倍。
Blocks & Files:VAST 近年来一直处于高度创新期,从零开始开发存储技术,并构建了类似“思考机器”的软件栈。这一创新期是否已经结束,未来是否只剩下渐进式的技术改进和业务流程优化?
Jeff Denworth:我可以自信地说,我们拥有业内最具创造力、最具雄心的团队。每一次客户交流都会给我们带来未来 10 年的新灵感……而且,我们很幸运,能与全球最聪明的客户合作。
如果有人认为我们已经满足现状、失去进取心,那将是一个危险的假设。我不会在邮件中详述我们的愿景,因为这对我们双方都没有帮助。但下次见面时,我们可以聊更多关于未来的事情。
