
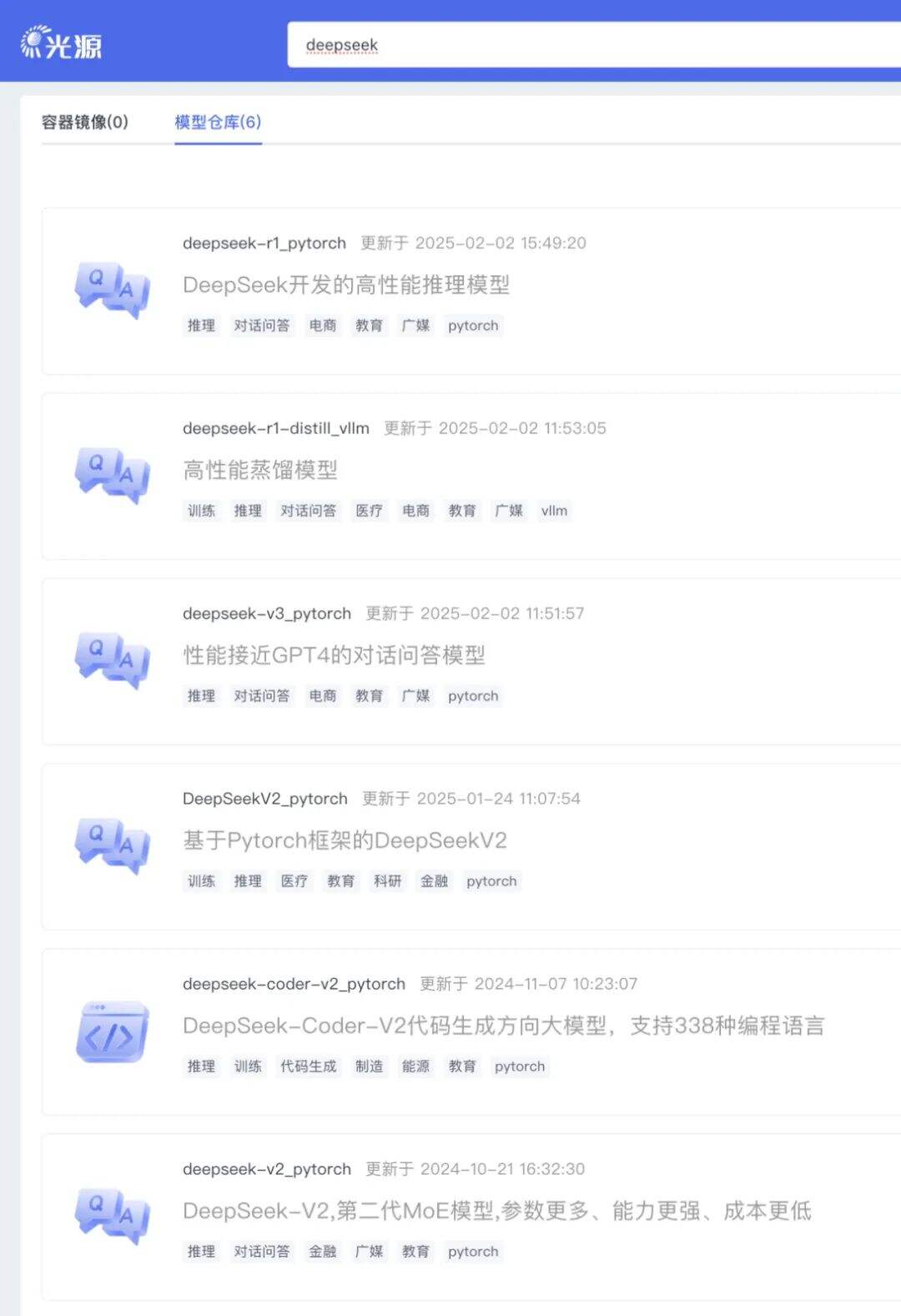
近日,海光信息技术团队成功完成DeepSeek V3和R1模型与海光DCU(深度计算单元)的国产化适配,并正式上线!
用户现可通过“光合开发者社区”中的“光源”板块访问并下载相关模型,或直接登录[www.sourcefind.cn]搜索“DeepSeek”,即可基于DCU平台快速部署和使用相关模型。
DeepSeek V3和R1模型基于Transformer架构,采用了Multi-Head Latent Attention(MLA)和DeepSeek MoE两大核心技术。MLA通过减少KV缓存显著降低了内存占用,提升了推理效率;DeepSeek MoE则通过辅助损失(auxiliary loss)实现了专家负载的智能平衡,进一步优化了模型性能。
此外,DeepSeek还引入了多令牌预测、FP8混合精度训练等创新技术,显著提升了模型的训练效率和推理性能。DeepSeek R1还引入了强化学习技术,进一步增强了模型的思考能力和决策效率,使其在复杂任务处理中表现出色,尤其适用于需要高智能决策的场景。
DCU是海光信息推出的高性能GPGPU架构AI加速卡,致力于为行业客户提供自主可控的全精度通用AI加速计算解决方案。凭借卓越的算力性能和完备的软件生态,DCU已在科教、金融、医疗、政务、智算中心等多个领域实现规模化应用。
海光DCU技术团队表示,将持续推动大模型迭代适配与优化更新,携手更多优秀大模型企业为行业客户提供更高效、更经济、更安全的AI解决方案。同时,团队也将积极探索更多应用场景,推动AI技术在更多行业的落地与普及。


