
对于存储供应商而言,MLCommons协会2023年发布的MLPerf Storage v1.0 AI存储基准性能测试,无疑是一个市场推广的制高点。该测试是由图灵奖得主David Patterson联手顶尖学术机构推动的标准,通过建模机器学习等AI工作负载,对存储系统I/O模式和性能进行评测,为ML/AI模型存储选型提供权威参考依据。
如能在测试中斩获佳绩,一定会帮助厂商拓展市场,创造有利条件。
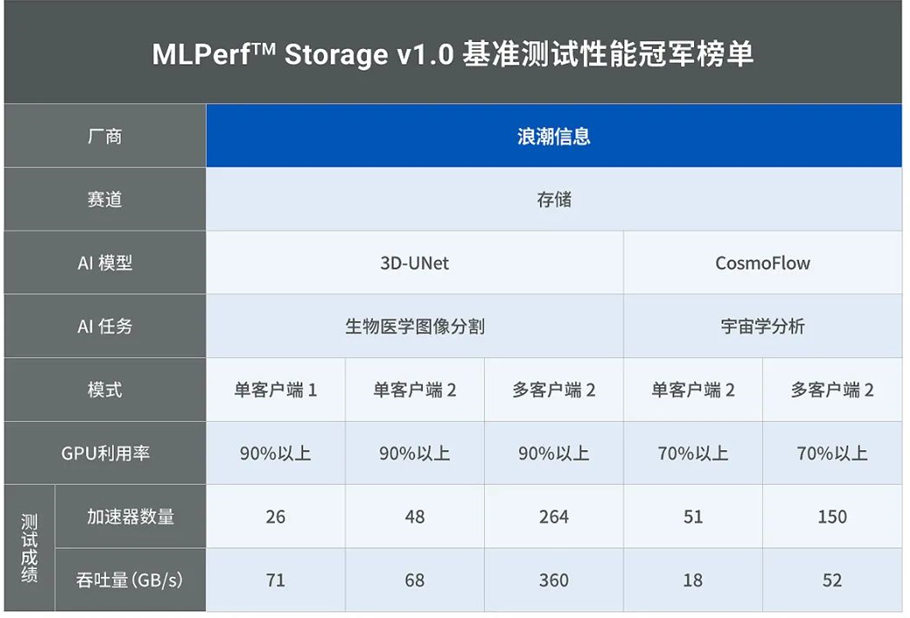
在最新披露的MLPerf Storage v1.0测试中,浪潮信息AS13000G7分布式存储平台表现出众,在3D-UNet和CosmoFlow两个模型共计8项测试中,斩获5项最佳成绩。
浪潮信息AS13000G7做对了什么?有哪些心得体会分享?
10月18日,浪潮信息存储产品线副总经理刘希猛、浪潮信息分布式存储研发部总经理张在贵、浪潮信息分布式存储产品线副总经理安祥文、浪潮信息分布式存储方案架构师Lance SUN接受媒体采访,分享了MLPerf Storage v1.0测试的经验。
据了解,本次MLPerf存储基准评测(v1.0)吸引了全球13家存储厂商和研究机构参与,围绕医学影像分割、图像分类、宇宙学参数预测垂直领域内的 3D-Unet 、 ResNet50、 CosmoFlow三个典型算法,重点考察与之匹配的存储系统的总带宽/每节点带宽,以及存算配比指标的能力。
这些指标对于AI至关重要,原因很简单,如今承担算力的GPU资源非常昂贵,万卡集群所能提供的算力惊人,资金投入同样惊人,在这种情况下,高效利用GPU资源意义重大。众所周知的“木桶效应”表明,木桶盛水的多寡是由短板而非长版决定的,AI系统也是一样,不论决定模型训练数据加载,还是模型训练过程中断点续训,其加载速度不能拖GPU的后腿,加载时间越短越好,不要让GPU资源出现闲置、等待的状态。
有鉴于此, MLPerf存储基准评测(v1.0)对GPU利用率设置了门槛,其中,3D-UNet的要求是90%以上,Resnet50、CosmoFlow的要求是70%以上,换句话说,留给存储数据加载的时间,最苛刻的只有10%,在满足这个前提下,对于存储系统的吞吐能力,以及所能够支持GPU数量进行考察,也就是上面图标中所说的加速器数量,这里的数据越大越好。
顺带提一句,在这次参加测试产品中,Resnet50始终达不到70%利用率的指标,后来MLCommons协会对MLPerf Storage v1.0软件进行了调整。因此,此次测试,3D-UNet、CosmoFlow更能够说明问题。
要想在MLPerf存储基准评测(v1.0)中取得佳绩,采取NVMe SSD全闪集群架构设计是一定,SATA SSD以及混闪架构设计达不到性能的需要。此外,网络带宽也是必须满足的条件,有专业人士指出,“网络400G连接完全是被GenAI催生出来的需求,其技术本身没有那么成熟,类似性能抖动是必须要解决的工程上的难题。”
刘希猛透露,浪潮信息在这次测试中,采用了InfiniBand网络方案,但浪潮信息也准备了以太网络方案,能够帮助用户更好控制成本。
然而,仅有硬件还是远远不够的,软件的作用更为关键。
对于参测的存储系统而言,必须要一致性分布式管理系统进行组织协调,以浪潮信息的方案为例,其控制层面采用有针对的管理和调度,对节点间流转的数据流进行管控,减少东西向(节点间)数据转发量,因为频繁的节点间数据转发,必然拖累存储系统的整体效能;再有就是频繁的IO中断以及上下文切换,也是需要极力避免的问题。为此,浪潮信息分布式存储平台AS13000G7采用了多路并发透传技术,将多个 I/O 请求进行整合和批处理,使得系统可以一次性处理多个请求,而不是逐个处理,从而减少了上下文切换的次数;该系统允许多个 IO通道同时传输数据,充分利用存储系统的硬件资源和网络带宽。
此外,在数据传输过程中,还要注意减少格式转换、数据校验等中间处理环节,采用数据直通传输的方式。还要注意增强文件系统与计算节点亲和性,确保负载均衡。从浪潮信息存储的实践看,好的设计能够将数据移动与多核CPU之间的访问效率提升400%。
这些先进技术的是AS13000G7斩获佳绩的重要保证。
从表现看,在3D-UNet测试场景中,AS13000G7三节点存储实现了1430个高并发读线程,每个线程单次I/O时延均在0.005秒以内,AI端到端训练I/O占比低于10%,计算节点带宽利用率达到了72%,实现了单存储节点120 GB/s的超高性能。在单客户端2和多客户端2 CosmoFlow宇宙学分析应用的评测任务中,AS13000G7也分别提供了18 GB/s和52 GB/s的带宽最佳成绩。

这是一份令人相当满意的答卷,也帮助浪潮信息在评测中独占鳌头。
刘希猛指出,人工智能赋能千行百业,背后离不开数据这个关键生产要素,数据连接了物理世界和数字世界,而数据存储作为数据的载体,是人工智能落地的关键支撑之一。
如今,舆论的焦点都集中在大模型AI创造的神奇,但是对于创造奇迹的过程缺乏必要的了解。在存储配套方面也存在类似问题,舆论更多关注模型训练的数据加载、过程中的断点续训,青睐TB级、万卡算力等指标,但是忽视了数据归集、清洗的重要性,大模型AI要行业落地,势必牵涉到要将分散在终端、地域,跨协议、跨地域数据进行处理,涉及到大数据组件Spark、以及Clip等工具的使用,这也需要适合的存储系统提供支撑。这也是存储系统选型重要的考察内容。
对此,浪潮信息AS13000G7同样表现出色,凭借非结构化协议融合、富元数据管理等技术支撑,AS13000G7能够实现文件、对象、大数据、视频协议互通,语义无损、性能一致,仅保存一份存储池数据,就可以支撑多种协议访问,避免了数据拷贝,实现最高50%数据存储空间的节省。此外,其系统可靠性以及韧性同样出色。试想,如果存储系统韧性不足,导致训练中断,则任何努力都将付之东流。对此,要求存储系统提供主动管理技术能力,对硬件、网络、系统等进行检测,在系统亚健康就采取措施,进行免数据迁移的快速微重构,而这些都离不开AI技术的加持。
刘希猛指出,无论采用什么样的进阶路线和方法,生成式AI对行业的影响将是史无前例的,其中数据成为智能革命的核心动力。围绕着数据归集、训练和推理,应该构建起强大的算力、存力基础设施,会发挥事半功倍的效果,磨刀不误砍柴工。对于浪潮信息而言,参加MLPerf Storage v1.0 AI存储基准测试也不过是小试牛刀,在展示技术水平和能力的同时,也加深了对于生成式AI技术的适配和了解,将继续全力推动AI产业化和产业AI化进程。
浪潮信息已经做好了充分的准备!
万事俱备,不欠东风!
