
一、需求背景
1.1.结构化数据
近年来,随互联网规模的不断扩大,网络安全事件呈现复杂、多样化的趋势,这使得分析监控网络所得到的海量数据成为一种日益重要的应用。这种网络数据具有流的特点:定时采集的流量信息和实时分析数据包是否有木马、蠕虫等安全问题的数据以事件记录的形式实时地进入系统,这种累积的数据可达几到1TB/天。通常分析是对一段时间的海量数据执行随意(ad-hoc)的统计查询,要达到满意的响应时间,必须结合应用特征选择合适的并行处理技术。
通用并行数据库把所有数据组织成一个单一映像,利用专用的硬件结构和昂贵的软件来实现各种并行性。其中,shared-everything结构利用大的共享内存来提高数据的命中率,适合对事务吞吐率要求高的OLTP系统,但对内存总线的竞争限制了系统的扩展性。shared-disk和shared-nothing的结构中,处理节点是分离的,各节点协同地处理被分区的数据,因此适合像DSS这样对大量数据查询的应用,但它们受高度复杂的并发控制和处理节点间协作的影响,也存在扩展性的问题。
网络数据管理中,按内容不同,实时监测的数据通常被分成几个子集,如流量事件、特征事件等。由于没有逻辑上的关系,这些事件表之间不存在相互关联。另一部分重要的数据是描述系统配置和监控规则的配置数据,这部分数据总量小且相对稳定,更新操作不频繁。因此针对应用的这种特点,将事件表水平分布到所有处理单元上,而配置表则全复制到所有节点上,可以将最耗时的数据扫描和局部处理并行化,从而大大提高查询的响应时间。由于各处理单元不需要复杂的并发控制和统一管理,这种方式可以方便地扩充处理节点,来管理非常大量的数据,并具有良好的扩展性。
随着存储器密度提高,每单位价格下降;集群系统已经成为了主流的并行系统,它具有性价比高、扩展性好等诸多优点;DRAC基于集群技术,直接将任意查询分解成操作于分区数据的子查询和汇总中间结果的后处理查询,用成熟的DBMS来实现两种查询的执行,从而避免了一般的分布式查询处理器为了通用而引入的复杂性。配合针对特定应用的分区策略,DRAC的方法能保证查询执行的效率。
1.2.半结构化数据
分析师[Richard Winter]认为,企业应保存最详细的数据,以用于宽广的商业战略决策,一般要保存5~7年。据此推算,企业数据量年增长1.5~2.5倍。更加激烈的竞争环境使得企业更依赖于新颖且更深入的数据分析获取的信息,这也要求纳入更多的数据。
摩尔定律断言CPU的处理速度每18个月增加一倍,同样通过若干年的观察发现网络带宽和存储容量增长也都具有指数增长的规律。图灵奖获得者Jim Gray提出了一个新的经验定律:网络环境下每18个月产生的数据量等于有史以来数据量之和。至少到目前为止,数据量的增长基本满足这个规律。据权威机构国际数据公司IDC统计,至2010年,全球产生的数据达9880亿GB,年复合增长率为57%。下述数字可以佐证数据增长的事实:AT&T的网络每天流动16PB的数据,Google 每天处理20PB的数据,Facebook每天存储1PB的照片,
Youtube存储了31PB的流媒体数据。Cisco公司预计:到2012年每个月网络上视频流大约为5Exabytes(5000PB)。除互联网,呼叫详细记录,天文学,大气科学,基因组学,生物地球化学,生物,和其他复杂和/或跨学科的科研,军事侦察,医疗记录,摄影档案馆视频档案和大规模的电子商务都需要面对急剧增长的大量数据。
这些海量的数据蕴藏了大量给企业带来价值的信息。在它的帮助下,人们可以发现重复的商业模式,更准确地预测商业活动趋势;发现疾病发作的原因和传染的规律,有效地预防疾病的爆发;掌握嫌疑犯人的活动轨迹,有效地打击和违法犯罪活动等。企业用以分析的数据越全面,分析的结果就越接近于真实。大数据分析意味着企业能够从这些新的数据中获取新的洞察力,并将其与已知业务的各个细节相融合。
急剧增长的数据集合也给企业和数据管理能力提出了前所未有的挑战,不再适宜于用当前管理数据库的工具来进行分析处理。这些难点包括:数据的抓取,存储,检索,共享,分析以及可视化等。这种好处和获得的困难的矛盾直接催生了“大数据”这一概念的提出和被快速认同。根据维基本科的定义,大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。大数据来自方方面面,从搜集天气情况的感测器,接入社交媒体网站的指令,数码图片,在线的视频资料,到网络购物的交易记录,手机的全球定位系统信号。
由于大数据问题被业界广泛认识并得到充分关注,目前已出现了相对成熟的大数据平台。这些解决方案中基本分为两大类:互联网企业自建的大数据平台和创新型企业提供的新型的大数据产品。前者代表公司主要有Google、Yahoo、Amazon、Facebook,以及国内的百度、淘宝等,后者则有EMC、IBM、HP(Verica)、Teradata(AsterData)等。这其中深受瞩目的是Hadoop平台,由于它的开源性质和完善的平台方案,吸引了包括Facebook、百度、淘宝在内的国内外互联网厂商来使用这一生态系统构建自己的大数据平台,并参与了这一系统的完善过程。
二、解决方案
2.1.基于大数据平台的大型门户网站
基础设施面临的问题
在互联网大行其道的今天,内容和用户是互联网公司关注的焦点。成功的企业无一不是拥有大量稳定的用户,并以此建立自己的商业模式。而拥有内容,特别是大量原创、优势内容的企业或组织具备了赢得大量、忠实用户的先决条件。
但内容和用户的增多给企业带来了高效基础设施和巨大访问能力的挑战。为了支撑未来不断扩大的业务,基础设施必须预先筹划,充分考虑到扩展性。一方面要求系统保存内容要具备横向扩展的能力,适应不断增多的系统规模和更大的访问量。另一方面,系统中相互关联的业务模块也要求基础设施提供统一、共享的服务能力。从Google、Amazon、淘宝等成功互联网企业披露的事实看,基础设施成为决定互联网企业能否做大做强的重要因素。
典型的大型门户网站的业务类型复杂多样,新闻、图片、论坛、社区、博客,以及音视频分享等都是有相当成熟度的业务。有效支撑这种大型门户网站的基础设施需要解决三方面的问题:数据存储、在线服务和数据分析。具体看来,它符合大数据的V4的标准。但是单一的大数据平台只能解决某一方面的问题,必须综合使用多种技术才能高效实现统一的大数据平台,支撑门户网站的发展要求。举例来看,图片是MB级的文件,Facebook和淘宝的私有系统采用不同的技术手段实现了图片文件的高效存取,但不加修改的HDFS则很难有效管理巨量的小文件。
大数据平台架构
下图给出了支撑大型门户网站的大数据平台架构。它从逻辑上分为硬件层、存储层和计算层,对上支持各种业务模型。
硬件平台统一为整合计算和存储能力的存储服务器,服务器之间通过以太网络互相连接。这种不再需要门类繁多的存储设备和服务器类型的设计可以大大简化管理和建设的复杂程度。
存储层解决各种类型数据的存储问题。上层业务的数据可以分解为:结构化数据、文本(包括网页)、图片、音频、视频、以及索引文件等。结构化程度高、事务性强、需要反复操作的数据仍然保存在关系数据库里,网页信息等可以Key-Value的形式保存在NoSQL存储系统中。大量小图片、音频文件等可以保存在分布式存储系统中。为了提高检索效率,各种索引以特有的格式分散保存。
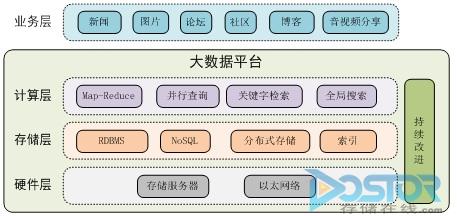
图 支撑大型门户网站的大数据平台
计算层负责将存储层中管理的数据转化成上层应用所需要的数据集。这些转化包括基本的数据存取,如基于唯一性的关键字获取属性值或内容;通过关键字快速检索某一应用的数据,或者整合多个系统的检索结果呈现给用户;使用Map-Reduce和并行查询分别快速从大规模的文件数据或数据库中分析出感兴趣的信息。
从技术选择上来看,数据库存储可以选择横向扩展、支持复杂并行处理模式的MPP数据库系统,NoSQL key-Value存储可以选择Hadoop-HBase系统,分布式存储可以选择业界优秀的集群存储系统,选择支持可以插件形式扩展各种应用的检索系统。
业务实现
大数据平台提供的存储和计算资源都可以实现资源池,以多租户的形式提供给上层应用使用。
以新闻为代表的网页需要将各种文字、图片等信息组织起来呈现给浏览者。Web Server可以快速地以URL为关键字,从HBase中取出对象的内容。进一步将内容标识的图片从分布式文件系统中提取出来。当用户点击音视频时,再从分布式存储中将这些信息提取出来,传给用户。社区、博客、论坛的页面展示都可以采用这种方式生成。
相对于一般的页面、论坛、博客信息更新,或者用户评论、互动更加活跃。例如评论会以较短的文本形式来体现。采用HBase的Key-Value来存取就特别合适。
只要提供类似Key-Value方式的创建索引和检索算法,每个子系统都可以向公共的大数据平台申请专有的检索服务。例如图片可以根据标签进行检索,而文本则根据内容进行模糊检索。系统同时提供跨应用的全局检索,它将关键字按规则转化成各应用的搜索请求,并合并中间结果。
大数据平台还提供通过分析,不断改进业务水平的能力。通过用户行为分析,可以得到用户的使用喜好,向某些人群推送特定内容,提高用户粘性。另外对系统负载、不同国家和区域的特征分析,都可以改进服务质量,也可以对系统的升级、维护提出预警。这些分析一般是通过记录用户访问的日志,以及系统运行、维护过程中产生的日志。可以采用MPP数据库的方式,也可以采用Hadoop-Hive,结合Mahout的分析功能实现信息的抽取。


