
前言
今年3月底,一篇名为“CXL is Dead in the AI Era”的文章在中英文网络开始上流传。文章以其抓人眼球的标题和貌似专业的分析,被不少人转载, 让很多人对Compute Express Link (CXL)的发展产生了疑虑。阿里云作为CXL联盟的创始成员及董事会成员,一直走在CXL发展的最前沿。而从我们经CXL发展历程来看,这篇文章中的观点有失偏颇,论据也有不少纰漏;同时,我们也看到不少同行也不认同该文章的观点,并发表不同意见[3]。在这里,我们将深入地分析原文中的观点和论据,阐明我们的观点和洞察,旨在拨开浮云,为CXL发展之路正本清源。
背景
为了便于展开讨论,我们在这里先简单介绍CXL的历史,基本概念和特点。 关于更多详细的协议原理介绍我们在此不做赘述。
大约在2018年到2019年初,整个云计算行业已经浮现出了几个明显的特征:异构计算的兴起,用来做加速运算的各种设备XPU越来越多,但如何高效的对这些异构设备进行程然内存带宽需求持续增长,但它受到芯片引脚数量的限制越来越突出,如何用更少的引脚数实现内存带宽的持续增长变得业界需要迫切回答的问题;内存和计算资源紧耦合造成的内存碎片和成本高企,因此在计算存储分离后,内存与计算之间的解藕成为提升内存利用率和降低成本的一个重要技术方向 。CXL 就在这样的背景下产生,它旨在构建一个内存语义的开放一致性互连,推动可编排服务器和机柜架构演进,来解决上述业界所面临的挑战。具体来说, CXL在PCIe 5.0+ 的物理层上定义了三个子协议:
○CXL.io: 可以认为是PCIe协议,提供非一致性的I/O访问接口。主要用于设备发现、枚举、错误上报、P2P DMA等。
○CXL.cache:支持缓存语义的子协议。设备可以通过该子协议,访问并缓存Host管理的内存空间,同时协议支持了维护缓存一致性需要的请求和侦听类型。
○CXL.mem:支持内存语义的子协议,提供了通过load/store指令对设备内存进行一致性访问的能力。
通过3个子协议的不同组合,CXL协议定义了三类设备和对应的使用场景,如下图所示:
○Type1设备(CXL.io + CXL.cache):适用于需要缓存一小部分主机内存数据的设备,支持设备缓存的数据一致性。
○Tpye2设备(CXL.io + CXL.cache + CXL.mem):适用于设备自身提供缓存和内存,且需要和主机交数据设备
○Type3设备(CXL.io + CXL.mem):纯内存设备,用于主机扩展内存,内存池化或共享。

CXL三种设备形态
CXL从2019年发布1.0版本以来,到2023年11月已经陆续发布了1.1, 2.0, 3.0和3.1版本,如下图所示。图中没有显示出来的是,在这段时间内,其他的开放一致性互连标准,Gen-Z,OpenCAPI和CCIX,分别于 2021年11月 , 2022年8月和2023年8月将他们的IP纳入到CXL下。整业界朝一个一开一性连

CXL协议发展史
CXL的每个版本都确保后向兼容,但又有其新的特性。这里不对每个特性做详细介绍,但有必要对每个版本中新增特性所覆盖的范围作个简要说明。 如下图所示,CXL 1.0/1.1解决的问题是单个节点内,主机和设备之间的内存一致性互连;而CXL 2.0把一致性互连的范围扩大到了机柜层面,实现了一个机柜上多个节点间内存或其他设备的资源池化;CXL 3.0/3.1进一将一致性连范围大到机柜,通拓展CXL Switch路由能力,构建Switch Fabric,实现机柜内/机柜间资源的分离,池化和共享。

CXL协议发展史
观点辩驳
在简要了解CXL互连的背景之后,我们再来详细分析下Dylan Patel的这篇《CXL is Dead In the AI Era》文章中的观点。文章的整体行文逻辑是从PCIe SerDes IO带宽效率不高和硅片IO Beachfront积受限这点,推演出 “CXL Will Not Be The Interconnect in The AI Era”并此支“CXL is Dead In the AI Era”这样抓眼球的题目。 可以看出这并不是一个严谨的逻辑推演,它有两个大的方面问题:
●首先,偏差性比较。正如前文所述,CXL并非为AI而生,它首要解决的问题是,主机内存与其他设备内存之间一致性内存互访的问题,而不是AI所要求的超大带宽问题。这一目标就决定了CXL协议在设计上的很多选择。比如,它选择兼容PCIe并采用其物理层来充分利用其庞大的PCIe生态,实现对最广泛主机设备的支撑,毕竟绝大部份设备都是通过PCIe接入服务器主机的。也正是因为这样,CXL在业界迅得到广泛认,并陆续统一其他开源致性互协议如GenZ,OpenCAPI以CCIX等。 这种态上绑定意CXL的带宽演进强依赖于PCIe的演进速度。 相比之下,NVIDIA NVLink 专门针对GPU-GPU互连而生,后拓展到GPU-CPU互连(早期的IBM PowerPC及近期的NVIDIA NVLink-C2C)。作为一个私有协议, NVLink可以不必考虑后向兼容以及相应生态成熟的问题,演进速度自然比PCIe更加迅速。 这就好比“一个人走的快,但一群人走的远”一个道理。 非让“一群人”和“一个人”比谁走的快,这就是偏差性的比较。
●其次,以偏概全。AI时代,并非所有应用都是AI的。有大量的应用,譬如数据库事务处理,Web Serving,Java类应用,传统机器学习,搜索,编译,加解压/加解密等等,都需要通用算力来承担。事实上,依据信通院《2023智算力白皮书》[1],到2022年底,全球IDC通用算力规模498EFLOPS,占总算力的76.6%, 而相比之下,智能算力占比为21.9%剩余部份为超算算力,占比1.5%)。相较于前一年,智能算力以25.7%的速度增长,但需要注意到的是,通用算力的增长同样达到了25%。 从国内来看, 2022年底,我国总算力规模180EFLOPS,通用算力137EFLOPS, 智能算力 41 EFLOPS,智能算力占总算力的22.8%。按照工信部的规划[2],2025年算力总规模达到300EFLOPS,其中通用算力达到189EFLOPS,相较2022年增长52EFLOPS,而智算算力增加64EFLOPS。 这些数据清楚的表明,在AI时代,通用算力依然在成长,依然占据了总算力规模的大部分。不能因为AI应用吸引眼球,而认为它就是算力的全部;也不能因为某项技术在AI应用中效果有限,就认为该技术已经死于这个时代。

算力规模比较。 来源:中国信通院《2023智能算力白皮书》
在解释了这两点宏观逻辑链条上的问题之后,我们再来详细的对文中的论据和观点进行深入探讨。这里我们的目的是指出原文论据中的纰漏和缺陷,从而让读者能以更加辩证和批判的角度来看待原文的结论。
●原文论据1: “IO for chips generally must come from the edges of the Chips”,而在GPU上,HBM接口会占掉大量的片上Shoreline资源,致留给他IO的间非常限。
○我们先来分析下该论据的前半段:IO真的只能从Chip边缘出来么?在回答这个问题之前,我们先简单回顾下集成电路中的IO Pad。IO Pad通常可分为Peripheral IO Pad和Area IO Pad。顾名思义,前者是指放在硅片边缘的IO Pad。它通常应用在采用引线键合(Wire Bond)封装的芯片上,如下左图所示。因为需要引线,IO Pad无法利用硅片中间的空间,否则,引线长度过大,强度和电气特性都会存在问题,因此,IO Pad只能放在硅片的边缘;而后者是指可以分布在整个硅片平面上的IO Pad。它广泛应用于Flip-chip Ball Grid Array (FC-BGA)封装中。相较于前者,它可以提供更高的IO密度,更多的IO引脚数目,因此通常被高性能CPU/GPU所采用。但为保电源的均匀分布电源和地线通常过位于硅片中的Pad引入。就造成了于通信的IO都处在片的周围形成了们通常说的“Beachfront或者Shoreline”,其周长和深度了信号IO Pad的可用面积。这么看来,原文论据中的说法,除了“edge”的说法有些模凌两可以外,貌似没有大问题。但这里有一个纰漏,它并没有考虑到3D集成封装所带来的额外IO空间。与传统的2D或2.5D封装不同,通过TSV(Through-Silicon-Via),3D集成可以充分利用硅片的上下两个平面, 提供更为充足的信号引脚。一些典型的3D集成产品包括AMD的3D V-Cache,Intel的Lakefield CPU等,如图6所示。事实上,大家所熟知的HBM就是将多个DRAM硅片通过3D集成构建的。有了3D集成,HBM可以直接堆叠到计算硅片之上, 从而将IO数量消耗巨大的HBM接口移到计算硅片的背部,为计算硅片底部其他IO腾了空间,同时,它可以避免使用昂贵Silicon Interposer作介质来做多硅封装。 当然,如何有效的进行散热是一个主要挑战。虽然我们现在还没看到这样的封装用于实际的产品中,但SK Hynix已经在做这方面的研究,并计划在HBM4上实现HBM和计算硅片的直接堆叠[4]。 所以,我们认为这一论据并不普遍成立,原作者并没有充分考虑到可以通过封装技术进步来缓解IO空间受限这一挑战。
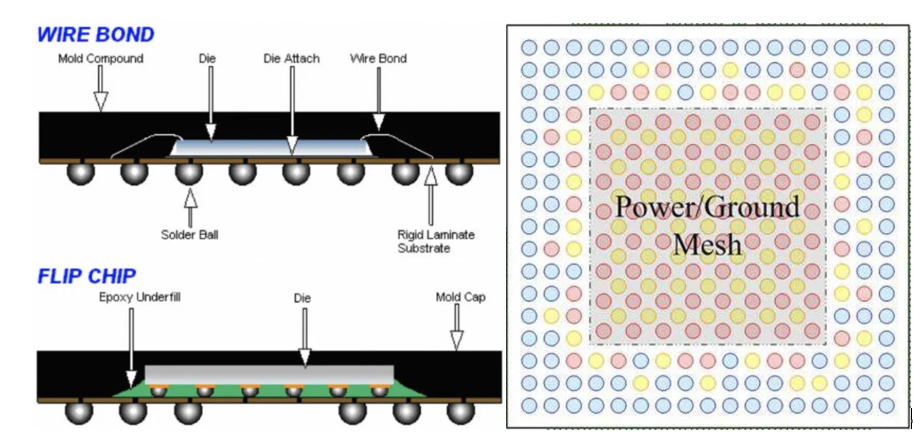
IO 在硅片上的排布。 来源: Ultra Librarian
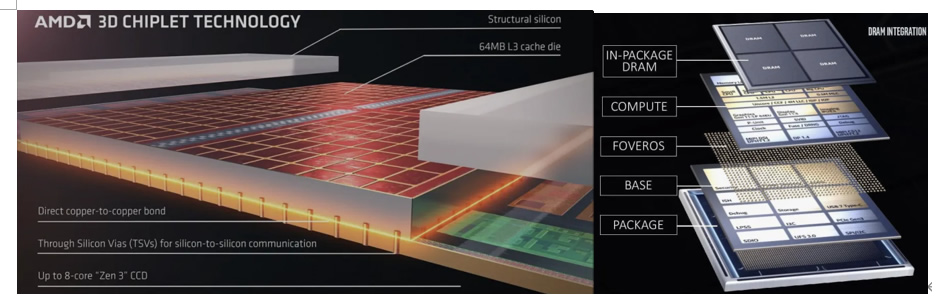
3D V-cache以及Lakefield 3D Foveros集成。 Source:AMD & Intel
●原文论据2:PCIe PHY的单位面积带宽效率没有NVLink的高,所以芯片设计者会选择112G 以太网PHY而不是PCIe PHY。
○首先,我们来看下单位面积的带宽效率这个指标。 严格来说,它可以从两个不同的角度来定义: 一个是从所需的Shoreline面积,也就是引脚数目的角度来看;另一个是从实现PCIe/NVLink PHY所占用的硅片面积的角度来看。 对前者来说,相的指标就是单位引带宽。 为做相应对比, 我们将每一代NVLink和PCIe的体指标总结下表中。 里需要注的是,在NVLink体中,每Link包含了多条lane,而在PCIe体系中1X指条lane, 这就解释了为什么在下表中最后一行,NVLink的单位Link双向带宽(BiDir BW/Llink)看上去远大与PCIe的相应数值。我们认为:合理的指标应该是单条lane上的带宽,因为对lane的定义NVLink和PCIe是一致的, 都是指TX和RX,两对差分信号,共四个引线。折合到单位引脚带宽上,NVLink和PCIe的比较显示在图7上。 在时间轴上,我们对PCIe的数据进行了区分,PCIe-Spec与PCIe协议标准发布的时间对齐,而PCIe-Prod是指新的PCIe标准发布后在市场上可以获得相应产品的时间对齐。通常PCIe-Prod会晚于标准发布时间2-3年左右;而NVLink,因为是私有协议它发布时通常就以产的形态出现。 可以看,NVLink的单位引脚带与同期的PCIe产品相比高大约3倍左。 因此,原中所述的NVLink总带宽比PCIe高7倍并不是一个严谨的说法。那么这3倍左右的带宽密度差距是么来呢?这里面相当一部分来源于PCIe在Gen3上等待了太多时间。 PCIe通常的迭代周期为3~4年,而在PCIe Gen3到Gen4的迭代用了7年。至于为什么花了那么久,江湖上有很多不同的猜测,但都于与技术无关,故这里不再展开。 而正是在这7年中,NVLink完成了1.0的引入和2.0的迭代, 确立了单位引脚带宽比同期PCIe产品高3倍的优势,并一直保持到现在。所以两者的带宽差距是由于迭代演进的时间节奏不同造成的,并不反映协议设计本身的优劣。 我们再来看看按照第二种角度定义的效率。我们没法知道NVLink PHY所占用的面。基于公开信息猜测NVLink4.0采用112G SerDes而NVLink 5.0采用224G SerDes,我可以找到与112G 以太网PHY进行相关比较的文献[5]: Intel 针对PCIe 7.0/CXL 4.0进行了早期PHY实现,其面积带宽密度(GB/s/mm^2)几乎和在同一工艺下的112G以太网PHY相同,且其线性带密度(GB/s/mm)还比112G以太网提高了25%。这表明112G以太网PHY相较于PCIe 7.0 PHY并没有带宽密度上的优势。 那如果是224G以太网PHY呢?Intel观察到了在相同工艺下, 224G比112G提升了30%的单位面积带宽密度和65%的线性带宽密度,而并非是一般认为的两倍提升。 综上所述,PCIe PHY的带宽密度不一定比112G以太网PHY差,与224G以太网PHY相比,差别也没像文中所说的那么大。


单位引脚带宽比较:NVLink vs PCIe。其中PCIe-Spec表示PCIe协议标准发布,PCIe-Prod表示PCIe标准产品化
AI时代的CXL互连:我们的观点
在分析和辩驳完了Dylan那篇文章的观点后,我们也来抛一下自己的观点:我们认为在AI时代CXL和NVLink将共存且协同发展。这个观点是于如下两个方面的原因
1. 在GPU-GPU间的互连领,高带是刚需,NVLink以显著的带宽优势加上其封闭私有协议所带来快速迭代优势短期内没其他方案可以撼动。 作为一个完整的AI智算系统,还包括了GPU-CPU互连,GPU与扩展内存或存储的互连,CPU与其他设备间的互连等等。而这些互连中,CXL的开放生态优势也很显著。GPU-CPU互连在NVIDIA 的生态中可以通过NVLink-C2C来实现(如Grace-Hopper和Grace-Blackwell之间的互连),在更广泛x86和ARM生态中,GPU-CPU的互连大概率将采用CXL互连;同样道理, 在面对有多元供应商的存储时,当前GPU都是通过PCIe来和存储设备进行互连,随着这些存储设备都将支持CXL。也正是由于这样的原因,我们认为在不久的将来,NVIDIA的GPU或将其PCIe接口替换成CXL接口
2. 随着AI大模型应逐步落地,理将占据绝大分的智算力,而成本是AI商模式是否可持续的关键。在GPU上集成更多的HBM,将会使GPU更加昂贵,并不是一个适合推理的低成本解决方案。而使用CXL扩展内存或内存池,将部份HBM/显存需求卸载到这些内存上,可以构建出一个在满足SLA条件下的,更加经济高效的推理解决方案[3]。 我们将这个讨论放眼到更长远和广泛的产业背景下,我们认为GPU间的开放互连标准正在快速崛起并成为主流:针对Scale-up互连,业界正在组建开放的Ultra Accelerator Link (UALink)标准;而针对Scale-out互连,行业正逐渐团结在Ultra Ethernet Consortium (UEC)旗下。尽管UAL和UEC之可能存在一些灰色地带,有一点是可以肯定的,们都不会去做主机和设间的互连,这样CXL作为主机设备间互连的地位更加巩固和聚。下面,我们举几个CXL在AI领域的应用。
a.类GDR和GDS的CXL高效实现
如图8所示,借助与PCIe Switch和NVIDIA 的ConnectX网卡,NVIDIA 可以实现不同主机的GPU与GPU之间的GPUDirect RDMA(GDR)。相比之下,如果GPU支持CXL 3.0接口,我们可以将PCIe Switch换成CXL Switch,并且无需网卡转发,便可以通过CXL Peer2Peer实现不同主机GPU之间显存的互访。而且,它们之间的访问无需通过DMA的producer-consumer语义,而是直接通过load/store语义的互访,极大的降低了软件开发的复杂度。

基于PCIe的NVIDIA GPUDirect RDMA vs 基于CXL的 P2P
类似的,如图9所示,借助与PCIe Switch,NVIDIA GPUDirect Storage(GDS)可以无需通过CPU侧内存上的Bounce Buffer,实现直接从挂载在PCIe Switch上的SSD上读取或写入数据。同样,如果GPU支持CXL 3.0接口,我们可以将PCIe Switch换成CXL Switch,便可以实现GPU到SSD的直接访问。而且,这种模式不单单适用于SSD,还可以用到Storage-Class Memory(SCM)等非易失性介质的内存上,实现内存语义的存储操作。

基于PCIe的NVIDIA GPUDirect Storage vs 基于CXL的Storage方
b.Retrieval-Augumented Generation (RAG)支持
为解决大模型推理受训练数据的时效限制的影响,最新主流的ChatBot服务(如ChatGPT 4, Gemini 1.5)以及主流的LLM推理框架(e.g.,NVIDIA TensorRT-LLM)都支持RAG。 不仅如此,RAG可以将强大的通用LLM能力高效扩展到各个垂直专业领域,而无需重新训练模型。 如下图所示,RAG的基本工作流可大体上分成两部份:首先依据输入查询数据库,从获取与输入相关的最新上文信息。这些信息通常存储在量数据库中,以便高的获取与查询信高度相关的内;然后,这些关信息与原输信息通过提示工程技术构建一新的Prompt输给LLM,从而使模型的输更加准确,专业和具备时效性。可以看到整个RAG流程中,数据库查询需要到CPU,LLM推理要用到GPU,两者缺一不可,且都处在关键路径上。 通过CXL来提升数据库的查询效率,可以有效降低整个RAG链路的时延和总吞吐。 可见,在更大的AI应用系统中,CXL不但没有死,而且还将发挥至关重要的作用。
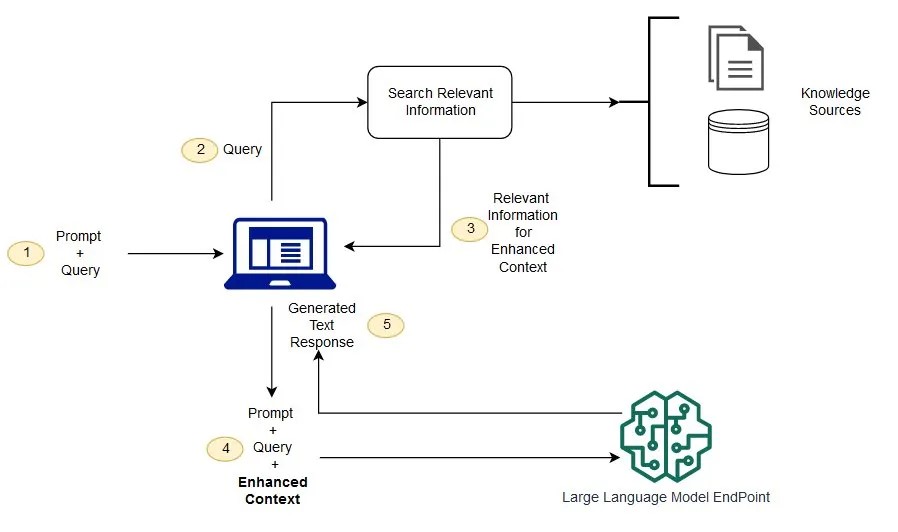
RAG和LLM协同工作示意图. Source: AWS
c.大量的内存扩展
AI型发展的一个趋势是参数的大幅增加,在过去的10年间参数快速增长到GPT4的1.8T MoE型,即使以FP8存,仅模型参数的内存占用量就到达TB以上。同时这种大模型处理过程中,KVcache以及数据预处理的内存占用量也非常大。如果单纯依赖GPU上的HBM或者GDDR来保存这些数据,整个AI系统会变得极其昂贵且效率低下,经济上不可持续。 利用CXL接口的内存扩展,提供低成本、高性能的超大的内存池,其CXL/PCIe接口可以同时满足CPU和GPU的访存模式,助力未来的智算系统降低成本,提高效率。
5、结
我们认为CXL所带来的服务器可编排和软件定义,是对服务器乃至数据中心架构的全面重构,将会对数据中心的成本,性能,运维及稳定性都带来深远的,积极的影响。如上所述,CXL不仅不在AI时代变得无关紧要,相反,它会对包括AI在内的各类云端应用带来更多性能和成本上的红利。 阿里云服务器团队在CXL领域与业界一起进行了多年的技术储备,一直走在业界的前列,我们将在后续的文章中陆续对各项技术进行详细介绍,敬请关注。
参考文献:
[1] 中国信通院,“2023智能算力白皮书”,https://roadshow.h3c.com/zl/pdf/2023zhinengsuanli.pdf
[2] 工信部,“算力基础设施高质量发展行动计划”,https://www.gov.cn/zhengce/zhengceku/202310/P020231009520949915888.pdf
[3] Adam Armstrong, “What role does CXL play in AI? Depends on who you ask”, https://www.techtarget.com/searchstorage/news/366575974/What-role-does-CXL-play-in-AI-Depends-on-who-you-ask
[4] “3D-stacks HBM memory directly on top of the processing cores”, https://www.tomshardware.com/news/sk-hynix-plans-to-stack-hbm4-directly-on-logic-processors
[5]. “CXL Q&A for AI”, https://members.computeexpresslink.org/wg/Board/document/3445
[6]. Dylan Patel and Jeremie Eliahou Ontiveros, “CXL is Dead in the Era of AI”, https://www.semianalysis.com/p/cxl-is-dead-in-the-ai-era


