
阿里云魔搭发起“ModelScope-Sora开源计划”,将为中国类Sora模型开发提供一站式工具链
3月23日,2024全球开发者先锋大会上,阿里云魔搭社区公布“ModelScope-Sora开源计划”,将以开源力量助力中国类Sora模型的探索和创新。该计划将为类Sora模型开发提供一站式工具链,涵盖数据处理工具、多模态数据集、类Sora基础模型、训练推理工具等。现阶段,魔搭发布了业界首个开源的多系统Data-Juicer,包含100多种高效算子,可大幅提升视频数据处理效率和质量。

Sora引发整个技术圈对多模态大模型的关注。除采用DiT模型架构外,学习了大量高质量数据,无疑也是Sora效果惊人的秘诀。阿里通义实验室资深算法专家李雅亮表示,“数据决定了机器学习任务的天花板,只有‘投喂’的数据质量高、颗粒度细、数量多,模型训练才能走出‘垃圾进,垃圾出’的困境。”
不过,类Sora模型的数据处理挑战极大。主流大数据框架并非为多模态数据设计,而视频处理难度较图文又大幅攀升,现有工具难以应对。因此,“ModelScope-Sora开源计划”首先上架了由阿里通义实验室研发的多模态数据处理系统Data-Juicer,它可对庞杂的多模态数据去粗取精,“榨出”更高质量、更丰富、更易“消化”的数据。
Data-Juicer支持文本、图片、音频、视频,内置筛选、映射、去重、格式化输出、美学打分等上百种高效算子,开发者可以像玩乐高一样自由组合。就像精于剪辑的导演,Data-Juicer能根据指定动作自动剪出视频片段,还能增强分辨率、调整宽高比、去除文本段,或通过计算光流判断视频动静,只保留精彩瞬间。此外,它还可自动打标,对线化环氛都精细捕捉并生成文字描述。
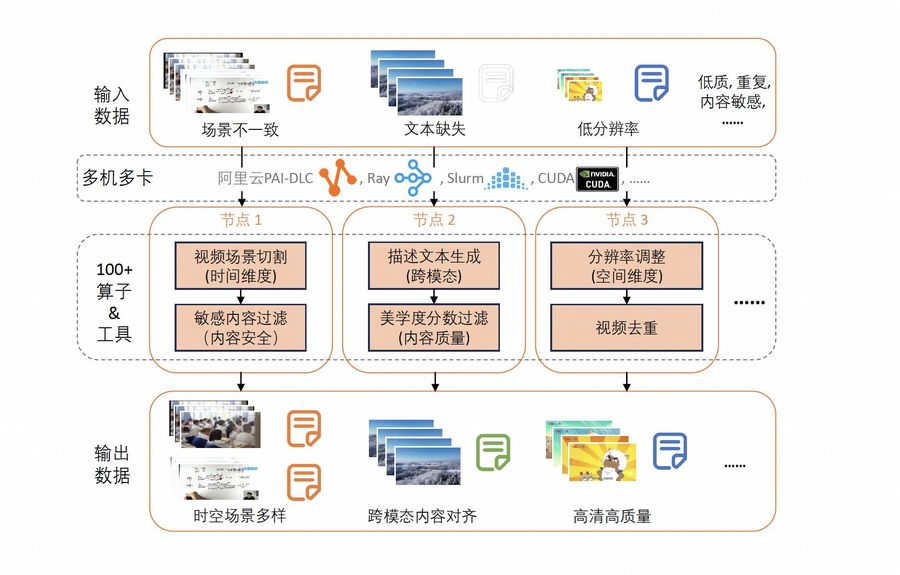
李雅亮介绍,魔搭社区还推出了基于Data-Juicer的沙盒实验室。研发人员可以先在迷你数据集和模型上快速迭代,找到最合适的配方。
然后,在Data-Juicer的数据加工流水线上,开发者可以使用阿里云PAI来调用集群和GPU进行大规模数据处理,后续还可在PAI上一站式完成模型的训、推。
魔搭“ModelScope-Sora计划”同步开源了基础类Sora模型。华东师范大学段忠杰博士联合魔搭社区,实现了DiT架构的视频生成扩散模型lite-Sora,并在小规模数据集上初步训练,得到能生成大幅度运动视频的实验模型。该模型正进一步深度训练,最终目标是完成对Sora的复现。

接下来,魔搭社区还将举办“ModelScope-Sora挑战赛, 鼓励多开发打造开源己的Sora模型,共同加速中国多模态大模型的发展。同时,魔搭将助力构建开放的中文高质量多模态数据集。作为国内规模最大、最活跃的AI开源模型社区,阿里云魔搭目前已汇聚3000多款优质模型及上千数据集,为超过400万开发者提供模型及免费算力服务。
魔搭“ModelScope-Sora开源计划”链接:
https://www.modelscope.cn/brand/view/MultiModality

