
在一年一度的云科技春晚——亚马逊云科技的re:Invent上,在最受关注的CEO主题演讲中,第一个发布的产品居然是一个存储产品,它就是Amazon S3 Express One Zone。
排面拉满的同时,我发现,这是一个违反广告法的存储产品。
亚马逊云科技CEO Adam宣称,Amazon S3 Express One Zone是目前速度最快的云上对象存储解决方案。

加速加速,超低延迟的对象存储来了!
Amazon S3 Express One Zone是一款性能加强版的S3对象存储,性能最多能达到标准版S3的十倍,每秒能够处理数十万次请求(具体数值暂未知),并始终保持几毫秒的延迟。
它主要面向延迟敏型工作负载,比如金融交易分析,实时广告推荐,欺诈检测,机器学习训练等场景,这些场景经常需要在短时间内发起数百万次的数据访问,并且延迟要求还很高。
在以前,为了提供这样的性能,用户需要把数据从S3挪到一些缓存加速解决方案里。然鹅,此时用户就需要管理多个存储基础架构,事情会变复杂。
而现在,有了Amazon S3 Express One Zone。
实际上,它用了专用硬件和软件来加速,它存放在单个可用区里,用户可以手动选择将热数据放在离高性能算力(包括EC2、ECS和EKS)特别近的地方,从而更好地降低延迟。
我记得亚马逊云科技在2019年的时候,收购了全闪存初创公司E8,然后,就再也没听到关于E8的消息了。至于这次是不是用了E8的技术。你猜!?
低延迟提高了小对象的性能表现
得益于低延迟的特性,Amazon S3 Express One Zone处理小对象的性能表现大幅提高。
通常,对象存储在处理大量小文件时的表现可能不如其他存储系统,频繁地读取和写入大量小文件会导致存储系统性能下降。
这是因为,对象存储系统在处理每个对象的时候,要处理元数据时都有一定的延迟开销。另外,读或者写一个象也需要一定的时间。
如果对象的个头比较小,那么,基础的延迟开销占整个过程的比例就更高,系统开销占比会更高,这时候的读写带宽也比较低。
而当对象个头比较大的时候,整个读写过程的大部分时间都在传输数据,开销的比例就更少,读写带宽就会比较高。
所以,当系统延迟比较低的时候,小型对象受益明显,性能相比于标准版的S3,最高能提高十倍。
低延迟的S3能帮助用户降低成本
更高性能层级的S3对象存储通常意味着更高的成本(文末有价格信息),但实际上,亚马逊云科技想说的是,它能省钱!
当用户使用突发实例和按需实例时,如果搭配延迟极低的S3存储,就能更快处理完任务,就能尽早释放这些计算资源,从而降低成本。
没错,这里省的不是存储的成本,而是云主机的成本。

当在面对数据密集型工作负载时,整个系统的运行时间会大幅缩短,特别是那些需要成百上千个机器一起干活儿的时候,效果会更明显,能让成本降低很多。
Adam分享了Pinterest的案例,其中,写速度提高了10倍,而整体成本降低了40%。

始于2006年的Amazon S3改变了人们消费和使用存储的方式,随时随地存取任意数量的数据的能力。
方便是真方便,贵也是真的贵,为了降低成本,亚马逊云科技前后有很多操作。
比如,后来发布成本更低的归档存储Amazon S3 Deep Archive,成本降到了每GB不到1美分的水平。
后来,随着Amazon S3层数的增多,后来又推出了Amazon S3 Intelligent Tiering,智能分层技术,自动帮用户在层与层之间迁移数据。
Adam表示,自发布智能分层以来,已经帮助用户省下了超过20亿美元,数据非常可观。
Amazon S3 Express One Zone的一些特别的地方
Amazon S3 Express One Zone支持常见的S3 API函数,也支持一系列的S3都有的功能。
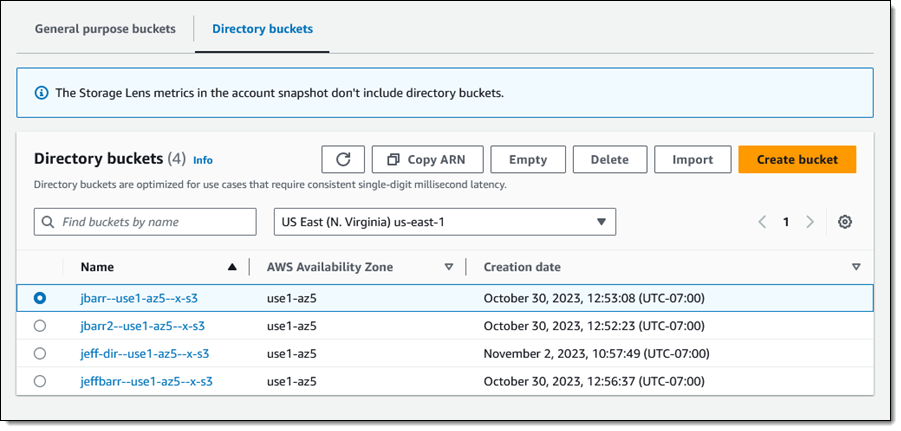
但跟别的S3不同的是,它有全新的桶类型(目录桶-Directory Bucket),全新的认证模型,还有新的桶命名规则。

上图是Jeff Bar在博客里分享的一张图,它能把数据从某个已有的S3桶里放到新创建的,Amazon S3 Express One Zone的目录桶里。
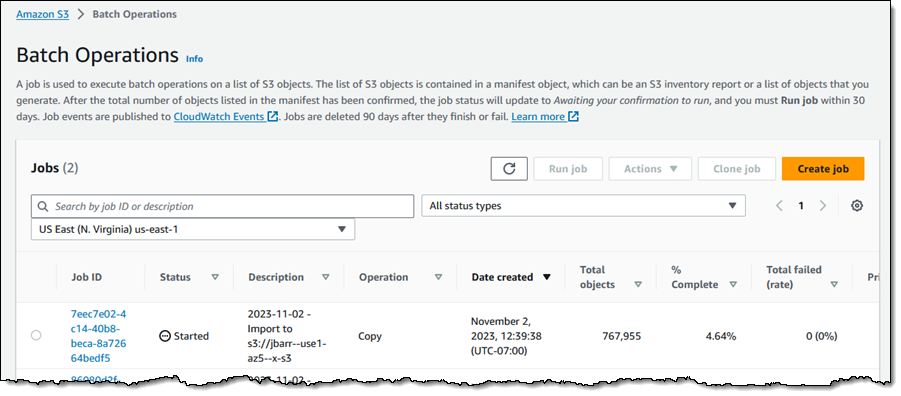
点确定,之后,就会自己进行批处理操作,把数据复制到高性能的桶里。
目前,Amazon SageMaker Model Training, Amazon Athena, Amazon EMR以及AWS Glue Data Catalog 都支持使用Amazon S3 Express One Zone。
目前,US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), 以及 Europe (Stockholm) 这几个区可用,中国区不能用。

价格方面,虽然数据只放在一个可用区里,但是价格却比标准的S3贵了不少(0.16 vs 0.023),毕竟性能高,贵点也行,是不是?
最后要注意,它只在单个可用区里存着,如果单个可用区出问题了,数据可能就丢了。
