
最近,英伟达发布了许多个东西,其中有一个叫GPU-CPU Superchip的东西还是挺让人眼前一亮的,亮到快瞎了的那种亮。

GPU-CPU Superchip把CPU和GPU放到了一块电路板上,上一次CPU和GPU走这么近的时候,还是集成显卡“寄生”在CPU时候。
肉眼可见的是,右侧应该是Hopper GPU芯片,周围几个看着像是显存颗粒。左侧应该是Grace CPU,周围有很多像供电单元一样的东西。
Grace CPU是英伟达的第一个数据中心CPU,拥有最多72个Arm Neoverse V2核心,支持最多512GB的LPDDR5X内存,每个CPU的内存带宽可达546GB/s。
Hopper是英伟达第九代数据中心GPU,主要面向大规模AI和HPC应用,相较于上一代Ampere 有很多提升。
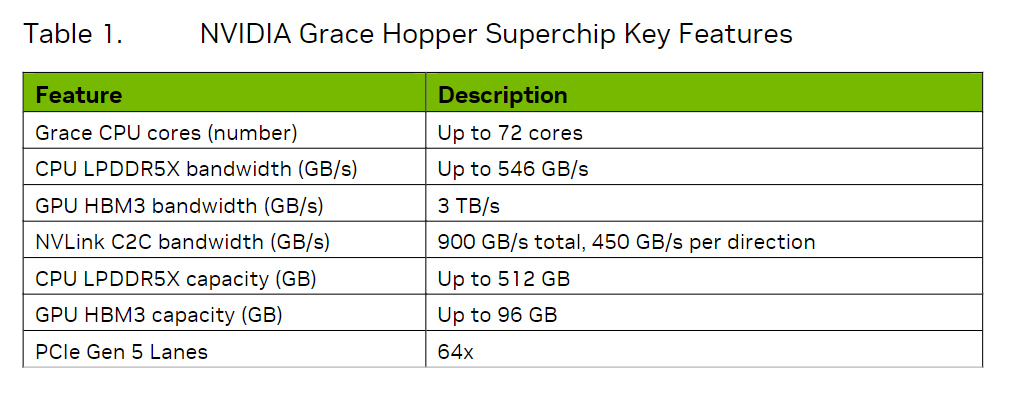
Grace和Hopper之间通过一个叫NVLink Chip-2-Chip(C2C)的互联技术连在了一起,提供高达900 GB/s的总带宽(单向是450GB/s),是x16的PCIe Gen5的7倍,可以为两个芯片提供内存一致性、高带宽和低延迟的通信。
英伟达在文档里写道,NVLink C2C所提供的内存一致性优势,可以提高开发者的生产力,可以提高性能,可以提高GPU的可访问的内存容量。
所谓提高生产力,是指在NVLink C2C的帮助下,CPU和GPU现在可以同时且透明地访问对方的内存,这使得开发者可以专注于算法设计,而不用花时间做内存管理。
NVLink C2C所提供的内存一致性,允许开发者只传输他们需要的数据,而不需要把整个页面数据迁移到GPU或从GPU迁出。
这里提供的内存一致性,还支持通过CPU和GPU的原子操作,来实现GPU和CPU线程之间的轻量级同步原语,方便开发者控制多个线程之间的协作和通信。
此外,配合地址转换服务(ATS),NVLink C2C可以利用NVIDIA Hopper DMA引擎,来快速地在主机和设备之间传输大量的内存数据。
在NVLink C2C的帮助下,应用程序可访问的内存不止GPU所提供的96GB,可用的还有来自Grace CPU的内存,每一个Grace Hopper Superchip可提供最多512GB的LPDDR5X的CPU内存。
加起来就是512+96=608GB!
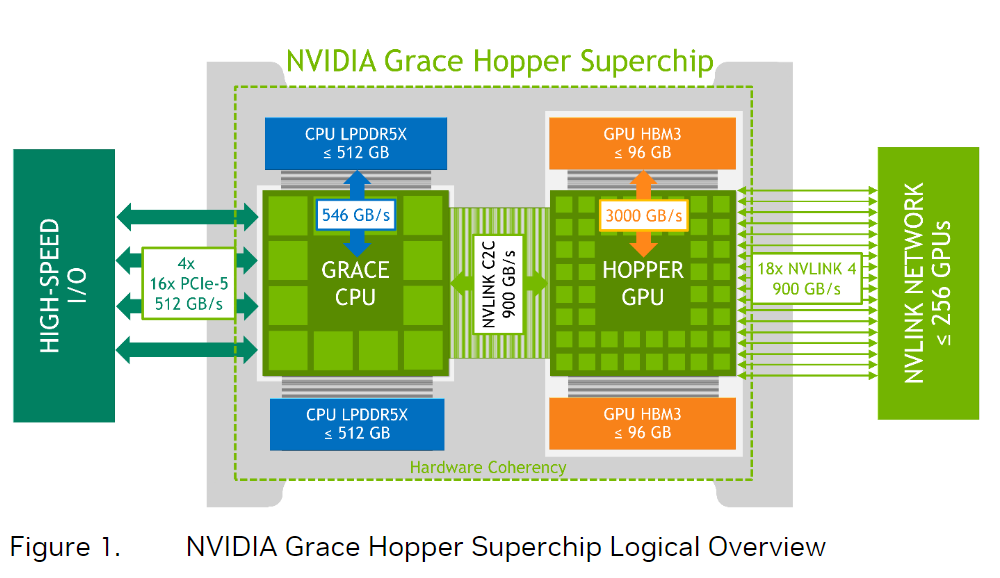
另外,NVLink C2C还支持NVLink Switch System,这使得一块Hopper GPU不仅可以访问本地Grace CPU的内存,还能透过交换机访问远端的Hopper GPU以及远端的Grace CPU的内存。
也就是说,每一个Hopper GPU都可以访问集群里的所有内存。值得注意的是,NVLink Switch和NVLink C2C的带宽一样是900GB/s的,这为跨节点的内存访问一致性提供了基础。
由于NVLink可连接最多256张Grace Hopper Superchip,算下来,最多可以访问150TB(256x608GB)的内存。
总之,NVLink C2C能让应用程序能够更容易地直接读取、储存数据,更方便地进行原子操作,有助于处理更大、更复杂的问题。
Grace Hopper Superchip属于是一种异构加速平台,适用于HPC和AI负载,它对技术领域的主要贡献是:提供了迄今为止最简单、最高效的异构编程模型,为解决复杂问题的人提供了便利。

上图展示的是基于Grace Hopper Superchip的一个HGX Grace Hopper Superchip节点,单节点的TDP高达1000瓦,风冷散热和水冷散热都行。
这么一个东西要怎么用呢?大体上有两种组织形式:

第一种是只用InfiniBand,配合英伟达的Bluefield-3 DPU,本质上还是传统的RDMA加速网络,这种适合横向扩展的机器学习和高性能计算工作负载。

另一种,在用了InfiniBand的基础上,还在显卡那一头用NVLink Switch System把显卡连在了一起,这种连接256个Grace Hopper Superchip的完全体适合用来解决世界上规模最大,最具挑战性的AI训练和HPC工作负载。

上图对比了CPU+显卡传统组合,Grace Hopper一体的组合以及配上了NVLink Switch的Grace Hopper三者之间的对比。
对比之下,CPU-GPU靠16通道的PCIe 5.0连接的速度与有了NVLink C2C的Grace Hopper相比实在是太慢了。
而GPU-GPU之间通过InfiniBand的传输速度跟基于NVLink 4的NVLink Switch相比,也差距甚远。

上图展示了Grace Hopper与x86处理器加GPU传统组合的性能表现差异。
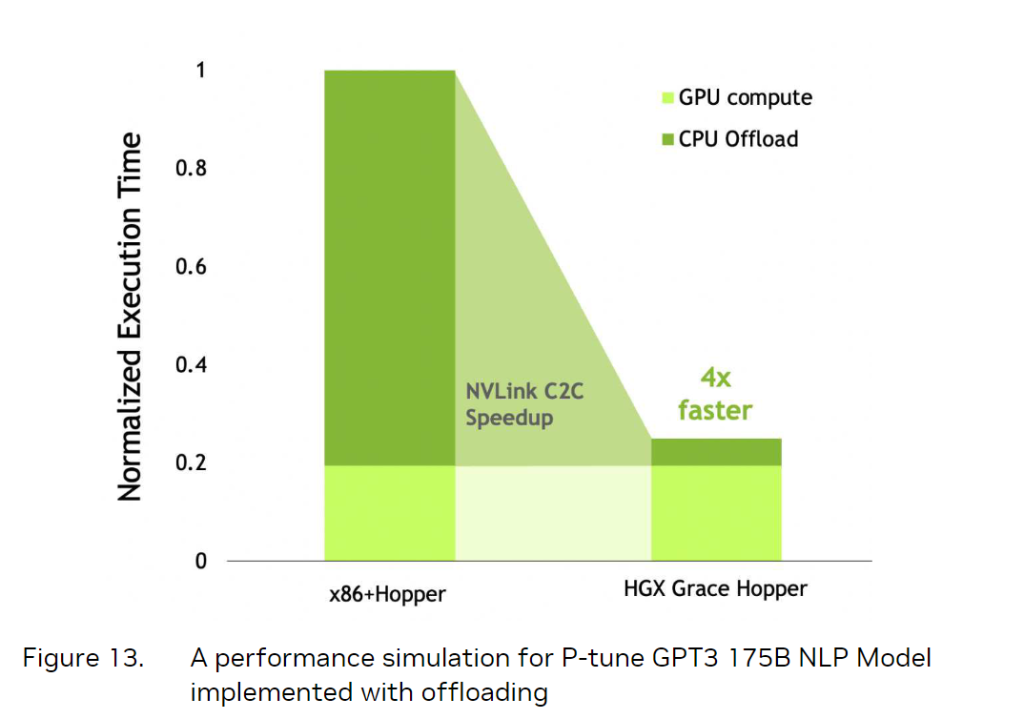
得益于NVlink C2C的加速作用,CPU到GPU的速度更快了,自然语言处理(NLP)场景的处理时间缩短了4倍。

得益于NVlink C2C和NVlink Switch的加速作用,CPU到GPU的速度更快了,使得DLRM推荐系统的处理时间有明显缩短。

在图神经网络场景中,得益于NVlink C2C的加速作用,Grace Hopper的性能表现也很强。

这张图显示的是纯x86处理器和有了GPU加速之后的对比情况,由于GPU-CPU之间的带宽限制,GPU的提升很有限,而有了Grace处理器的加速和NVLink C2C的加速效果之后,性能提高了4.25倍。
看到这里,应该已经大致感受到Grace Hopper SuperChip的厉害的部分,由于笔者对这些专业软件不太熟,也就不现学现卖介绍了。
本文旨在自己学习记录和帮同样想了解Grace Hopper SuperChip先睹为快,想了解更多细节的朋友可以直接看原文档。
https://resources.nvidia.com/en-us-grace-cpu/nvidia-grace-hopper



