
Part 1:如何让存储厂商用上大容量磁盘?
过去近十几年以来,磁盘容量从十几GB爬升到了二十多个TB。
撇开闪存不说,当你仔细看磁盘存储系统的时候,总能发现存储系统厂商在使用最大容量的磁盘时,往往有一些滞后。

这是为什么呢?
有人说了,这是因为大容量磁盘的容量太大,万一容量磁盘坏了,Raid重构的时候需要的时间就更长了。
恢复一块10TB的盘数据,跟恢复一块20TB的盘,工作量能一样吗?
小容量磁盘的重构时间短,对性能压力小,对业务连续性更有好处。
对业务人员的血压有好处,对存储管理员的人身安全有好处。
为了帮存储厂商安心用上大容量磁盘,还得从技术上解决大容量磁盘重构的难题。
为此,硬盘大厂希捷搞了一个叫ADR(自动容量重生)的硬盘技术,配合ADAPT技术,可将系统重构所需的大幅缩短,最多能缩短95%的时间。
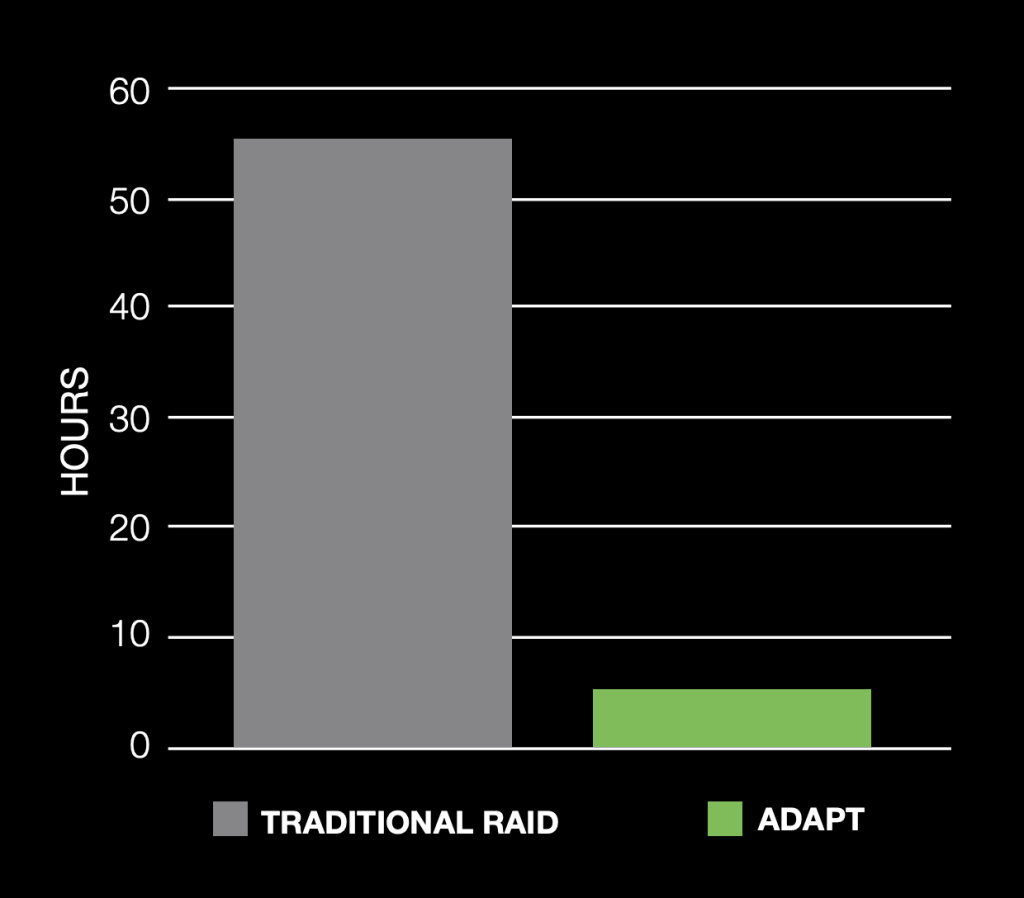
传统RAID技术下,坏一块盘需要五十多个小时重构,而现在需要几个小时甚至几十分钟即可。
重构时间缩短,好处多多:系统性能更稳定,对性能影响更小,还能减少恢复过程中可能带来的二次损坏,比如,恢复过程中又有别的盘坏了。
能缩短95%就很诱人吧,但是,听着很简单的技术原理,实际用起来还比较有挑战。
目前,希捷自家的Exos CORVAULT存储系统支持,其他存储厂商,想要用上这一良心技术,还得需要投入一些人力物力才行。
想了解,希捷Exos CORVAULT的神奇之处的话,可以接着往下看。(看完整版视频)
Part 2:为什么希捷Exos CORVAULT能让存储系统用上大容量磁盘?
Exos CORVAULT是希捷的一块高性能块存储系统,双活架构,5个9的可靠性,还有颇具行业突破性的硬盘故障自愈技术。

4U的空间,装硬盘之前,空荡荡的跟被打劫了一样。说一个人腿长,脖子以下全是腿。说一个存储系统容量大,除了风扇全是硬盘。
一个人想插满硬盘,得需要大概两个小时,塞硬盘的人嫌时间过的慢,旁边围观的,总忍不住想来帮忙。但凡多一个人,装盘的过程都会快得多。
插满之后,2.12PB,容量高到吓人。106块的20TB的大容量磁盘满满当当挤在一起,壮观,我是头一次见到。

这这这,全都是硬盘,这么多磁盘这么高的密度放在一起没问题吧。
嗯,好问题。
防止因为硬盘发热,硬盘转动振动对性能以及稳定性的影响,Exos CORVAUL从控制器到机箱都进行了特别的设计。
硬盘怕噪音的震动,特别是噪音大户的风扇,这次也被特别针对,希捷开发了一种叫Acoustic Shield的技术,给硬盘提供了非常安心的工作环境。

106块硬盘老老实实的摆在这里,满满的,强迫症朋友说了,那个角上的是啥?

是控制器啊,本以为这又是基于英特尔至强的控制器。

仔细一看,原来是希捷自己搞的ASIC芯片,ASIC芯片的成本低,性能呢,做的好的话,性能也挺高的。
上图显示,顺序读性能是14GB/s,顺序写性能是12GB/s,额外查了一下资料,最高IOPS为17680,磁盘存储的重点不是IOPS。
今天,性能不是重点,控制器配合ADAPT和ADR缩短磁盘构建时间才是重点。接下来简单介绍一下。

如图所示,左面是一张图片,代表用户要存的数据。右边是一堆磁盘,代表CORVAULT存储系统。

在计算机的视角里,图片被切成了很多个碎片Shards。右侧的硬盘会组成ADAPT池,什么是ADAPT?
ADAPT全称叫Advanced Distributed Autonomic Protection Technology (ADAPT),直译为自动分布式分配保护技术,一种希捷专有的替代传统Raid的技术。
ADAPT池里有一堆硬盘,负责存数据,存什么数据呢?

一种是用户的碎片Shards数据,一种是CORVAULT的ASIC控制器为用户数据生成的奇偶校验(Parity)。
奇偶校验是干啥的?保护数据用的,硬盘坏了,数据丢了靠它就能找回来。


系统中,奇偶校验会和数据碎片一起均匀地散布到ADAPT池中的硬盘里。
值得注意的是,数据均匀散布到ADAPT池中的硬盘里的操作,其实就是ADAPT技术(分布式自动保护技术)得名的由来。

众所周知,磁盘出问题,一般都是划痕什么的,伤到磁头或者盘片,出问题时,CORVAULT的控制器能分析磁盘产生的日志,根据日志找出是哪个磁盘的哪个盘片出了问题。
CORVAULT控制器发现问题后,先把坏掉的硬盘放一边,依靠奇偶校验数据从其他硬盘中,很快就恢复一份Rebuild Data,也就是坏了的硬盘里的数据。


这些刚恢复来的数据存放在哪呢?也继续散布到其他硬盘里。

接下来,就轮到ADR上场了。
刚才不是找出了出问题的盘片或者磁头了吗,CORVAULT控制器就跟硬盘配合,屏蔽掉出问题的盘片或者盘片对应的磁头,此时的硬盘容量会缩减。

现在一块磁盘最多有20个磁头和对应的盘片,坏了一个之后,就剩下95%了。

磁盘重生后,控制器就跟别的磁盘打声招呼说,这块盘又活过来了,把他该存的数据扔给他吧。


于是,一声令下,一群硬盘都快速把数据还给了它。最后,它又把原来属于它的数据存起来了,一切又恢复了事故之前的状况。
问题来了,为什么它的恢复速度快95%那么多呢?
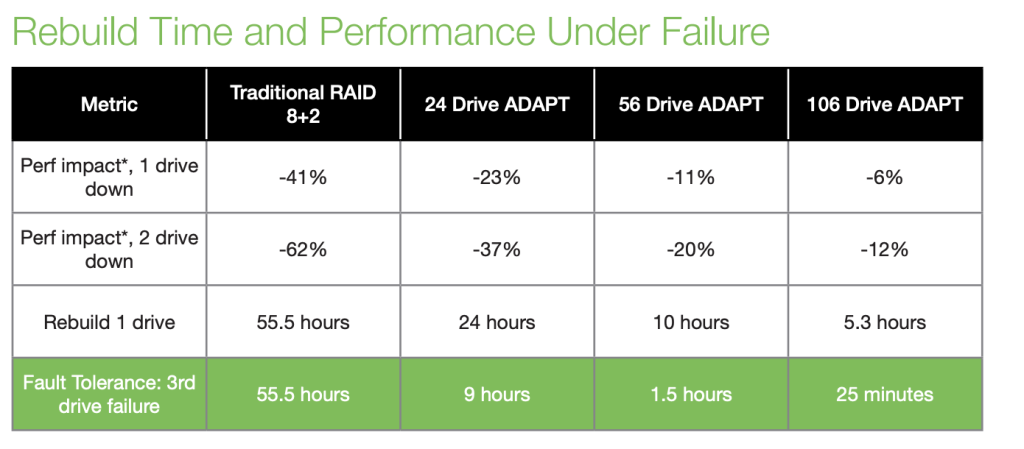
因为,ADAPT技术把奇偶校验和数据碎片散布到其他硬盘里,恢复的时候,实际是由多个硬盘共同完成操作,而不是靠原来一块盘干活。
换句话说,一个ADAPT池里的磁盘越多,恢复速度就越快。
颇有韩信点兵,多多益善的意思。
结束语
如此一番操作,地球上就少了一块坏的硬盘,少了一块电子垃圾,用户少买一些硬盘,存储管理员少开一次机箱盖子,少拔出来一块硬盘。
对了,不知道大家注意到了没有,这场硬盘故障前后,所有操作都是在一台CORVAULT里完成的,完全不需要外部网络。

如上图所示,希捷CORVAULT的集群里,完全没有因为系统重建时的流量造成网络的拥堵,系统的性能表现会更高和更稳定。
以上就是存储厂商在大容量磁盘使用方面的技术挑战,而希捷能让存储系统用上大硬盘这一话题的全部内容。
相关阅读:



