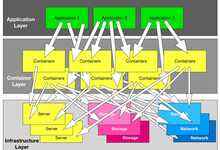
IBM Storage Fusion如何满足容器存储提出的新需求?
如今越来越多的应用都提供了容器化的部署方式,容器化后的应用,既可以在本地部署,也一样可以轻松部署到云上。正因为如此,容器被视为混合云的一项关键支撑技术,将推动混合云的发展。
随着容器技术的大范围普遍应用,对于容器存储的要求也水涨船高,在2023年分布式存储高峰论坛上,IBM科技事业部存储软件解决方案专家周立旸,分享了容器对存储提出的要求和IBM Storage Fusion在应对容器存储需求方面的优势。
容器对存储提出了哪些要求?
众所周知,容器与传统应用有很大不同,最显著的特征就是启动速度快,扩展速度快,对环境配置的依赖少,可以更便捷地四处迁移。在这些特性的影响之下,对存储平台提出了三方面的要求。
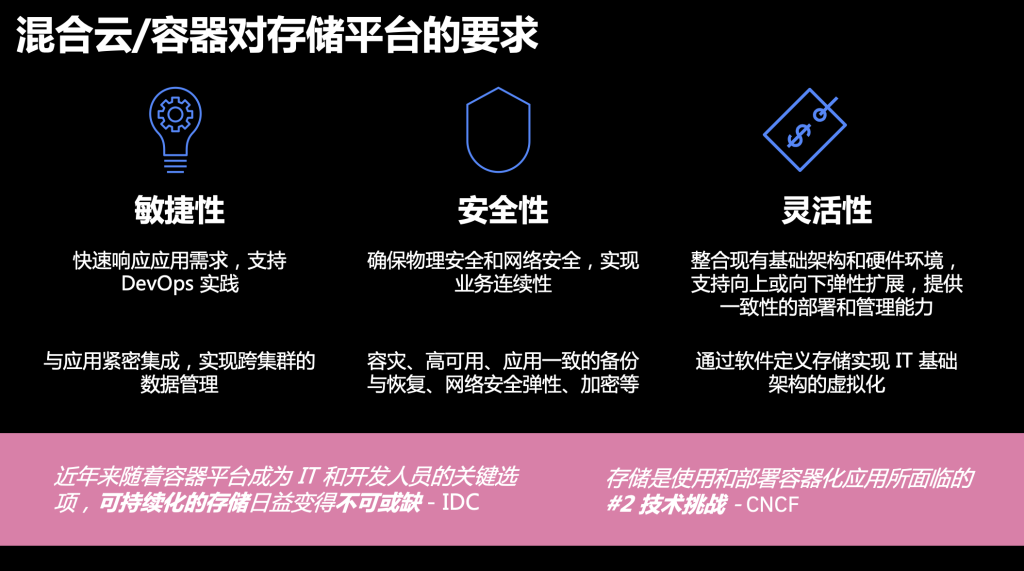
首先,容器对整个存储平台的敏捷性要求非常高,需要存储平台能够随着容器动态扩展,能支撑容器的敏捷部署,能让容器访问到存储资源。
第二方面,企业级的应用在安全性上有较高要求,一方面需要考虑业务连续性,另一方面,也需要考虑网络安全弹性,要能够抵御各种网络攻击和病毒。
第三方面在于灵活性,很多分布式应用既有向上扩展的能力,也具有向下扩展的能力,这要求存储也要具有一样的扩展能力。此外,考虑到节省成本,容器存储还要能与现有存储结合。
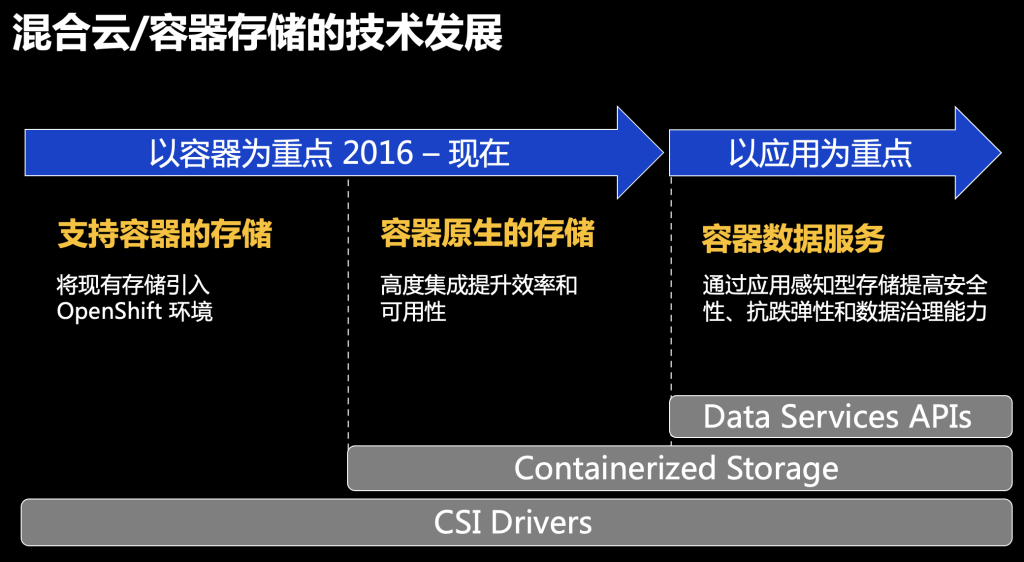
从周立旸的介绍中了解到,容器存储在过去六七年以来取得了长足的发展。
容器平台诞生伊始,容器存储都是在现有存储系统当中通过CSI驱动来支持容器环境。随着种种弊端的显现,用户迫切希望用上容器原生的存储。
容器原生存储的优势很多,它是软件定义的存储,它可以在容器环境里被动态部署和管理,它能提高应用的部署效率和可用性。
看起来已足够完善,但在IBM看来,这还不够。
IBM的容器原生存储——IBM Storage Fusion
在IBM看来,容器原生存储除了需要容器原生的,动态部署的效率和灵活性之外,也需要更灵活、更丰富的容器数据服务。
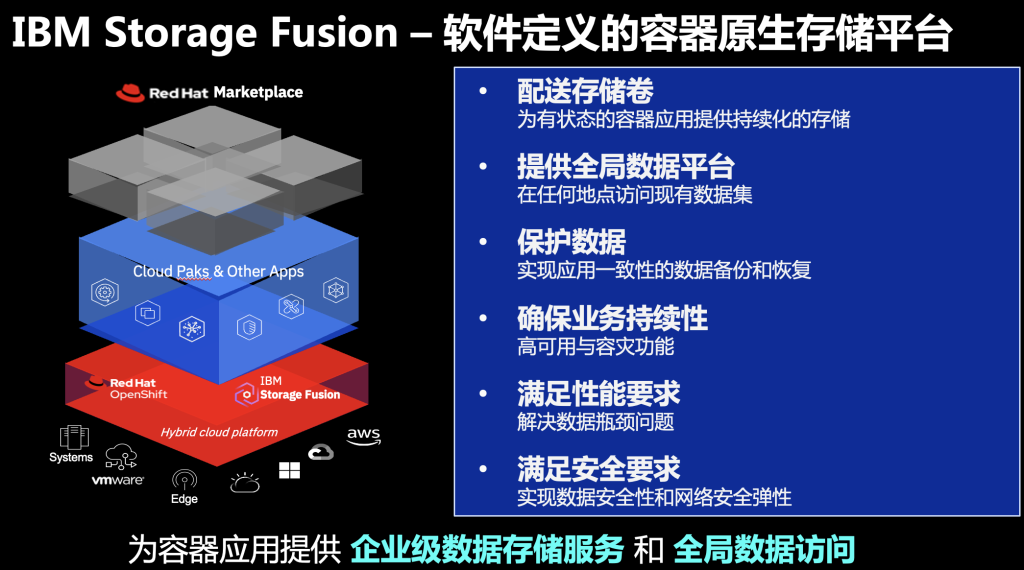
IBM的容器原生存储叫做IBM Storage Fusion,它是一个云原生的软件定义的存储方案,除了可以配送存储卷,为容器应用提供持久性存储之外,它还提供了丰富的企业级数据服务。
比如,全局的数据访问能力,访问到在其他平台当中产生的数据;全局数据平台管理能力,简化了数据的管理和使用操作;还有包括备份和恢复以及容灾等数据保护能力;还可以凭借优异的性能支撑数据密集型的应用。
从周立旸的介绍中了解到,IBM Storage Fusion能满足企业级容器平台对容器存储的所有需求。
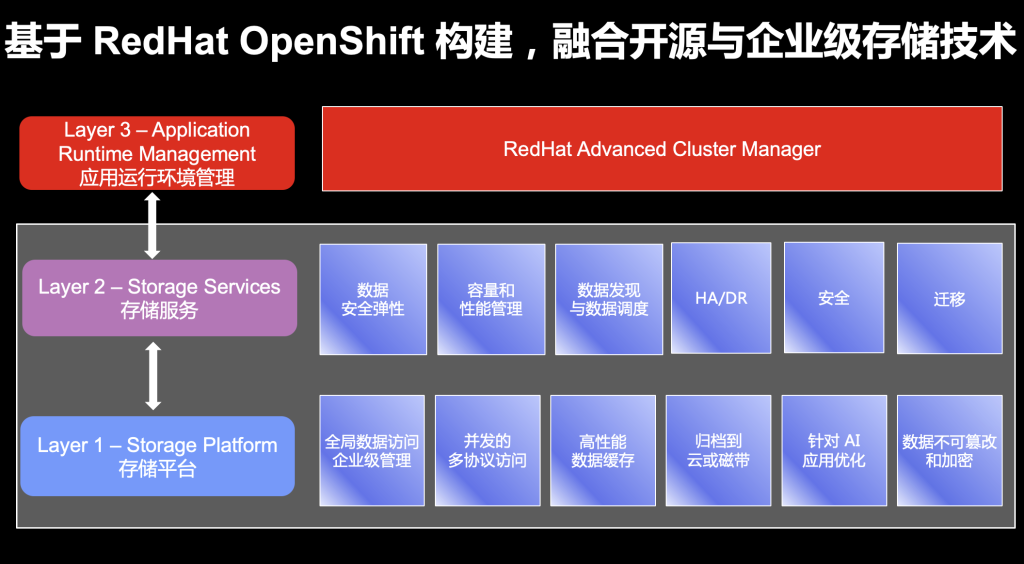
2022年,IBM将Red Hat旗下的存储产品与IBM存储进行了深度整合,IBM Storage Fusion就是基于OpenShift容器平台来构建的,它包含的一些组件可以直接在OpenShift来管理和部署。
IBM Storage Fusion所提供的多种数据服务,有的来自于IBM存储,有的来自开源的软件定义存储方案,整个平台保持了很好的开放性,能更好地满足企业实际需求。
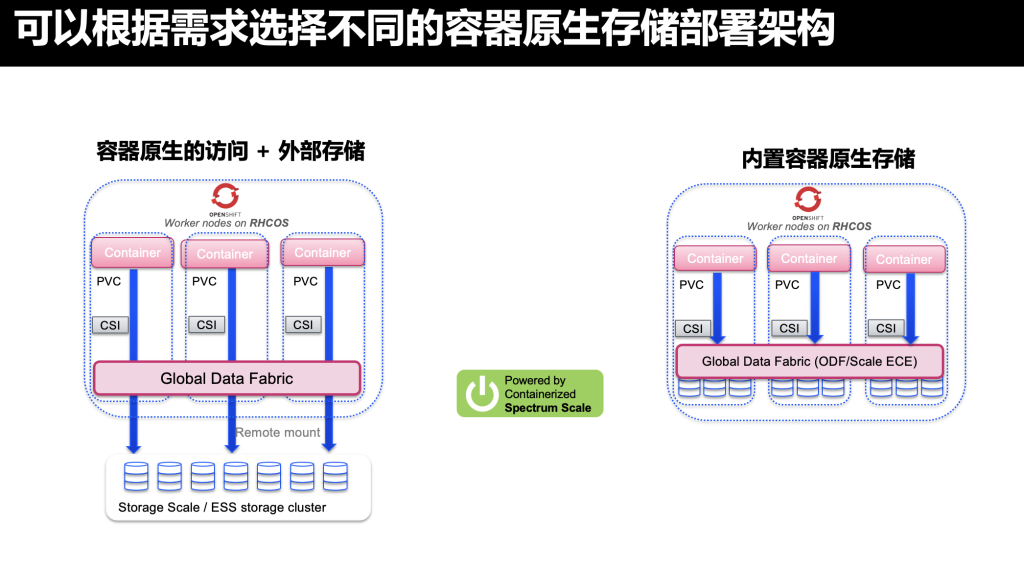
很多容器原生存储都是直接用容器服务器节点内的磁盘存储,而IBM Storage Fusion还支持外部存储,外部存储不仅可以补充额外的存储空间,也能提供更高的性能表现。外部存储提供了更高的灵活性。

IBM Storage Fusion融合了IBM企业存储的许多技术。其中,全局数据访问的能力在容器环境中又一次大放异彩。
它使得IBM Storage Fusion能将任何外部数据存储系统接入进来,无论数据在容器内外、在边缘端、在本地数据中心或者公有云数据中心,都能为容器提供一致的数据访问。既减少了数据复制和移动,也提高了数据存储效率。
IBM Storage Fusion的主要适用场景
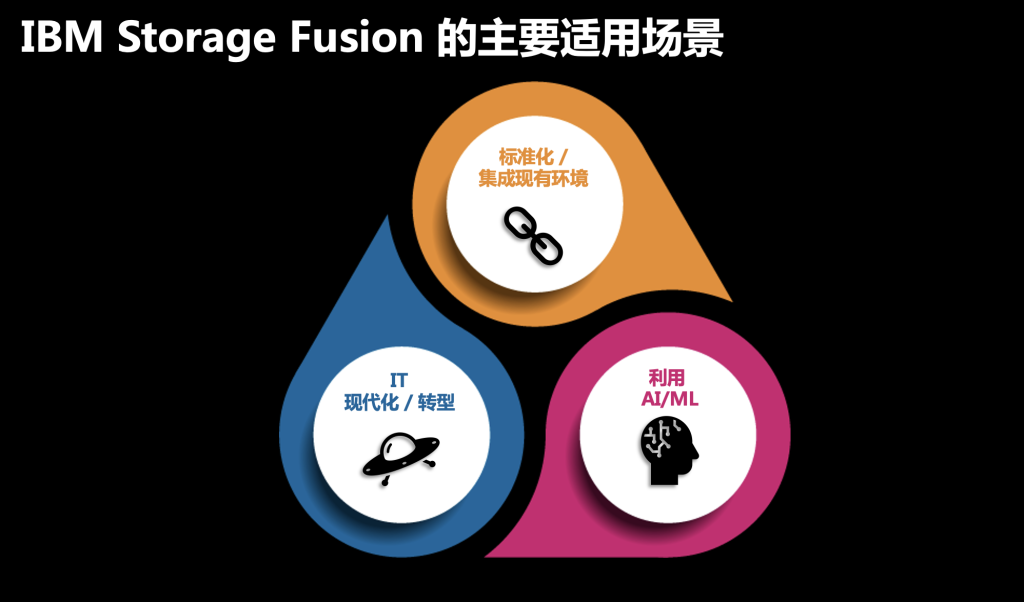
IBM Storage Fusion的主要适用场景有三个:
1,当用户希望拥有一个标准化的容器存储平台时,IBM Storage Fusion是不错的选择,它可以对在数据中心内部,公有云以及边缘平台上的数据进行统一管理。
2,当用户在做IT现代化转型,需要对应用进行容器化改造时,IBM Storage Fusion是不错的选择,它不仅可以维持原有的企业级能力,还能保持一致性的数据访问能力。
3,当用户的容器平台有数据密集型应用时,IBM Storage Fusion也是不错的选择,它能提供高性能数据分析和AI这种负载所需的高性能存储。

IBM Fusion Storage 支持存算分离,它意味着可以在容器平台之外提供独立的存储。存算分离的优势在于可以对存储和计算独立扩容,相互不影响,从而提供了更好的灵活性。
IBM Fusion Storage既支持容器应用,也支持非容器化的应用,用户可以在一套存储上同时部署两类应用,避免了再额外部署存储系统的开销。
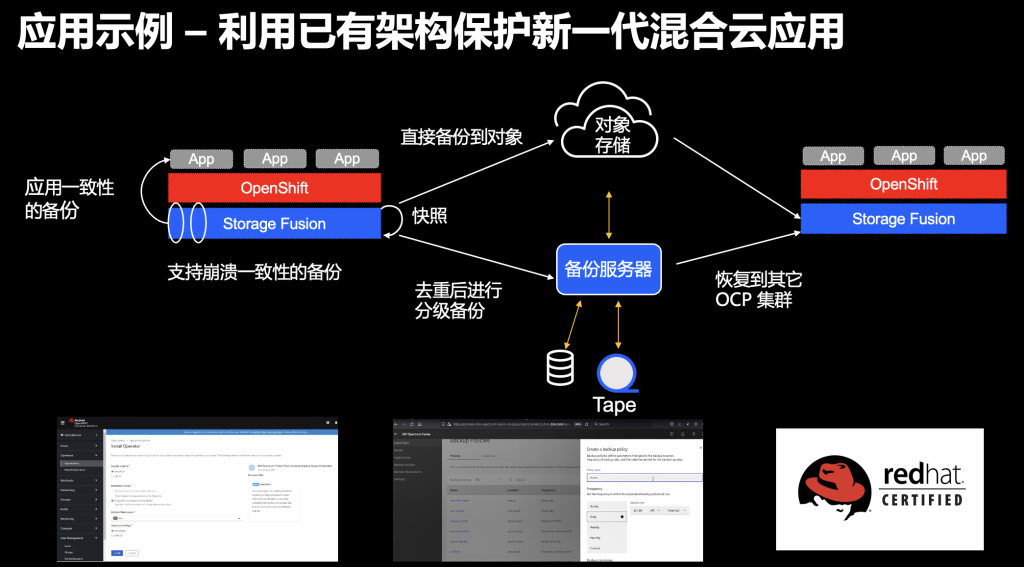
IBM Storage Fusion可以利用现有的备份恢复基础架构,在保护现有应用的同时,也能对容器原生的应用进行保护。更为重要的是,备份恢复是和容器应用紧密集成的,它的优势在于,在做数据恢复时,不会因为数据不一致而导致应用无法正常运行。
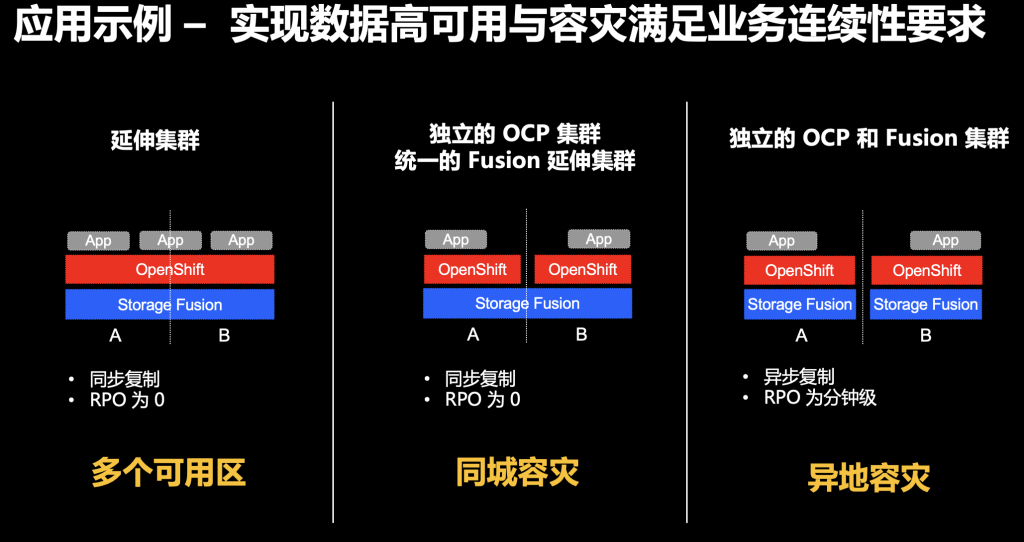
IBM Storage Fusion内置了高可用性。用户可以根据需求划分成多个可用区,在一个数据中心里的多个机架实现高可用,在一座城市里通过同步复制实现同城容灾实现高可用,如果有需要,也可以用异步复制实现异地容灾。
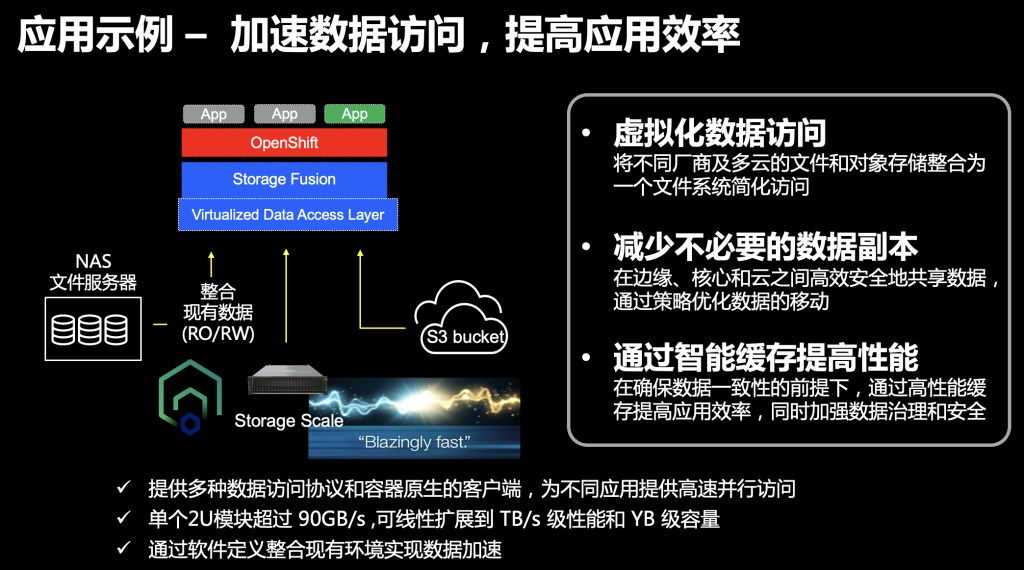
当有一些容器应用需要更高性能时,如果仅靠容器平台内置的存储,通常需要闪存的配置,这会带来很多额外成本。如果利用IBM Storage Fusion的存算分离架构的优势,只为需要高效数据访问的应用提供高速存储,就可以以相对低的成本来获取对应的能力。
IBM Storage Fusion还内置了很多虚拟化数据访问、智能缓存之类的功能,也都有助于提高应用的运行效率,帮助用户更好地管理和访问数据。
结束语
截止到2023年,IBM Storage Fusion已经诞生了一年多时间,在包括金融、医疗、制造业等多个行业都有一些实际落地的案例。
IBM Storage Fusion不仅能加快应用的部署速度,还能通过存算分离架构的优势灵活满足用户需求,并且能实现成本优势。
IBM Storage Fusion的所有技术都是容器原生的,它可以集成在容器的平台里面,被DevOps平台来动态的部署和管理,所有的能力都会和安全能力、备份恢复能力、容灾能力结合在一起,为用户提供一个相当安全,相当可靠的数据底座。
IBM Storage Fusion把IBM的企业级能力和开源软件结合在一起,用户可根据实际需求来灵活的配制他所需要的数据的服务,帮用户能够更好的解锁应用部署的速度,更好的支持他的创新,支持企业实现更高的业务应用价值。