
尊敬的各位领导、各位专家、各位线上的朋友,大家好!我是来自上海交通大学的吴晨涛。

接下来由我给大家带来报告《分布式学习过程中硬盘故障恢复加速的研究》,报告分为四个部分。
首先介绍分布式学习的故障场景。
在云计算系统中,分布式机器学习的数据集通常部署在云上,一般来说,数据集规模很大,它通常存储在多个节点上面,从数百GB、数TB甚至到多个EB不等。但在存储的系统中,存储节点会面临着故障频繁的问题:
一方面,计算层会从数据层的每个节点读取数据,向前和向后传递到神经网络;
另一方面,训练结果进行有效的聚合,形成最终的结果。
下面是常见的分布式的深度学习的训练框架。
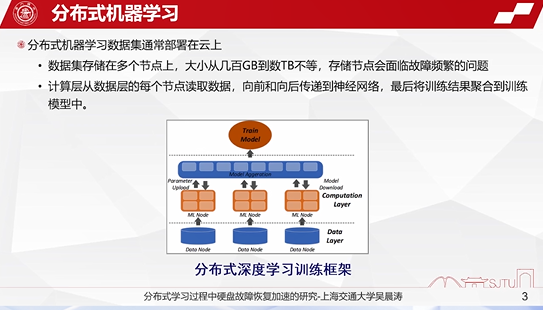
其实向分布式机器学习,向联邦学习等相关的机器学习的方法都采用类似的学习框架。
当前云存储系统中面临着严重的数据丢失隐患。
现在的存储阵列(如闪存阵列)等都广泛的应用于云存储系统中,据一些论文报告以及全世界各大互联网厂商的调研,传统的Flash、硬盘都面临着严重的数据丢失的隐患。传统的3D Flash,其故障率一般来说在1%左右。
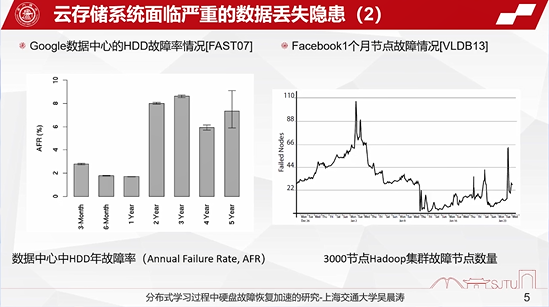
谷歌2007年的调研也表明,两年以上的硬盘的故障率都在3%-5%之间。Facebook的调研也表明,节点也面临着大量的故障情况。所以我们的研究主要面向着在大规模的分布式学习场景下,特别是面临着严重的数据丢失隐患的情况下,硬盘发生故障后该如何进行数据的快速恢复。
在当前的云计算系统当中,纠删码技术成本很低,易于实现,是目前实现大规模硬盘或者大规模存储系统容错的一种通常的技术手段。一方面它能够去适应不同的应用场景,另外一方面,它也面临着很多的问题,比如说延时很高,需要占用大量的恢复带宽。因此,如何在分布式机器学习的故障场景下保证学习效率,同时去挖掘分布式机器学习相关的数据关系来提高恢复速度。我们在这方面做了相关的工作,论文发表在IWQoS 2022会议上面,还有一些后续的工作。
现有的恢复方案主要基于两大类。
一大类是传统的基于纠删码的数据恢复方法。这些恢复方法通常来说是采用数据并行的方式来进行恢复的加速。主要问题在于纠删码的恢复方法主要是集中在分布式存储系统的底层,无法感知上层机器学习应用的特征,只能支持传统的恢复流程,恢复时间也比较长。

另外一类是基于机器学习的机器模拟的恢复方法。通过一些插帧、干的网络或者机器学习的方法实现对图像、视频等相关应用的数据恢复。但是它们的恢复实际上都是一些近似恢复,无法获得精确的数据,还需要消耗大量的GPU等算力资源。所以也存在恢复速度很慢的问题。
在这样的场景下面,如何来做到快速而精准的恢复,是当前面临的一个很大的问题。
二、部分恢复策略PRM

传统的纠删码的一种典型的恢复方式是PPR算法,它的核心思想是将纠删码编码过程当中的矩阵运算分解成几个部分,将部分的解码进行流水线编排,从而能实现训练的加速。但是在整个分布式系统当中,对于丢失的数据它只能进行完全恢复,而不能进行部分恢复,而且它的恢复方式是随机化的,它没有考虑丢失数据对上层的机器学习模型训练的影响。
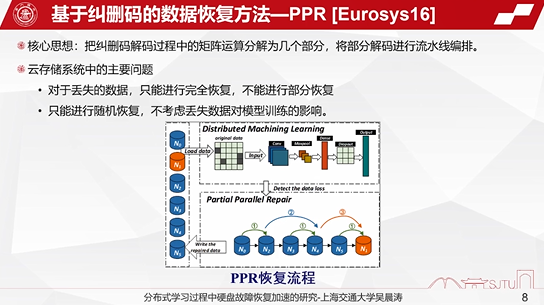
另外一类是在PPR的基础上进行改进的RP的算法,主要是在PPR的基础上进行数据的细粒度编排,达到更高的流水线的并行恢复。但是它对于丢失的数据也只能进行完全恢复,而不能进行部分恢复,而且恢复也是随机的,不能感知上层机器学习的应用信息。

机器学习的方法,比如说基于GAN的一些网络方法,主要是根据机器学习的训练模型生成丢失数据的近似恢复的方法方式。它也面临着一些问题,如有比较高的一些计算开销,需要消耗大量的GPU的算力资源,它的恢复方式主要是近似恢复,不能恢复原始的数据,存在着图像、视频等失真现象。
对比现有传统的基于纠删码的恢复方式和基于AI的一些近似恢复的方式,我们会发现它们在流水线的并行程度、数据的恢复速度、训练精度、恢复代价等方面各有优劣。
如何采用一种能够融合现有纠删码和基于AI恢复的一些方法的优点,来达到更好的效果的方式?
我们提出了一种部分恢复(PRM)的方法,也就是采用纠删码部分恢复、同时也采用AI的方式来做部分的恢复,达到最好的恢复效率,最终这种恢复方法我们把它叫做PRM。
三、部分恢复策略PRM
这个恢复框架主要是分成四个部分。
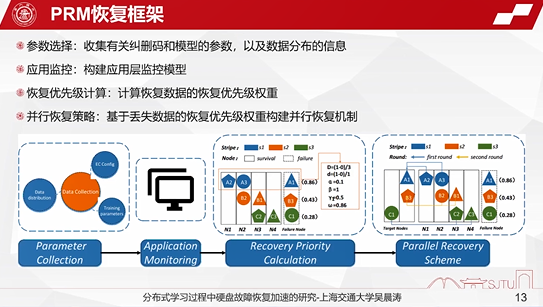
第一部分是做参数选择,主要是收集有关纠删码和机器学习训练的模型参数以及相关的数据分布的信息。第二个是应用监控,主要是构建应用层监控模型,来监控当前机器学习训练的实时状态。第三个是计算恢复优先级,通过计算恢复优先级获取到恢复数据的一些权重。最后是设计一个并行恢复策略,基于丢失数据的权重设计一种并行恢复机制,能够达到更快的恢复速度。
首先介绍一下参数选择和应用监控这两个模块。
在参数选择方面,主要需要收集纠删码的参数、条带的数据块参数、条带检查块参数以及编码矩阵的参数信息。与此同时,也需要去收集机器学习模型的训练参数,包括它的批次、批次大小以及更新权重等信息。

在应用监控方面,需要计算每个数据块和校验块的权重。主要是依据下面给出的公式来进行相应的计算。

在优先级方面,主要是考虑了两个不均衡参数,一个是局部不均衡参数,一个是全局不均衡参数。通过丢失的数据量和丢失的数据对整个样本的影响,从而算出来对于整体的数据集的不均衡的影响。影响越大,那意味着这个数据的权重也就越高,需要恢复的优先级也就越高。
在基于不均衡参数的基础上,我们计算了每一个数据块加权优先级,也就是把前面的这些参数融合起来,形成下面的公式。

这里我们给了一个恢复优先级的计算例子。

假设这个三角形、五边形和圆形分别代表着不同类型的数据。三角形的数据实际上主要是全局不平衡的参数,比如说根据条带和节点的信息来计算,最后算出来的结果就是(1-0)÷3,局部不平衡也是(1-0)÷3,最后算出来它的条带优先级就是0.86。
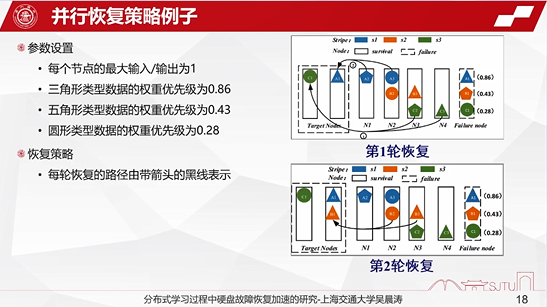
最后我们给出来一个并行恢复的例子。根据每个节点输入输出的情况,分别算出每种类型的恢复优先级,最后通过恢复优先级的叠加规划出最优的一种并行路径。
测试结果及相关的数据分析。
试验环境是基于4块GeForce RTX 3090 GPU卡来模拟整个分布式学习存储节点和计算节点,同时把不同的纠删码将训练数据存储在不同的存储节点当中。
我们使用4个训练数据集,并且基于RS编码来构建模拟的真实节点。整个试验的环境的架构如下面的左图所示,每个服务器的配制如下面的右表所示。

对比的方法主要包括传统的基于纠删码的一些恢复方法,比如说像RS、PPR、RP等传统的基于纠删码的并行恢复的加速算法,还有一类是基于AI的算法,包括GAN生成网络、CPR等等相关的一些机器学习的方法。数据集主要选取了现有的基于图像、视频这一类的为代表的数据集,比如ImageNet、COCO等等相关的数据集。
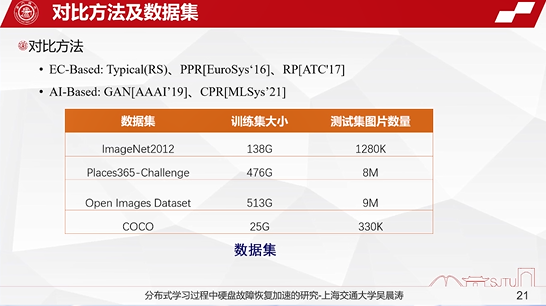
这个表当中还显示出了训练集的大小,以及测试的相关图片的数量,规模都是比较大的,一般来说是在数百万张图片的规模。
四、测试结果
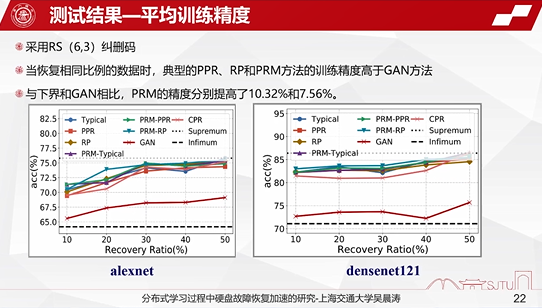
第一个方面展示的是平均的训练精度。我们采用RS(6,3)的纠删码,也就是6个数据块+3个校验块的配制。当恢复相同比例的数据时,我们与典型的PPR、PRM、GAN方法相比,训练精度明显要更高一些,而且与下界的网络相比,精度大约分别提高了10%和7%左右。
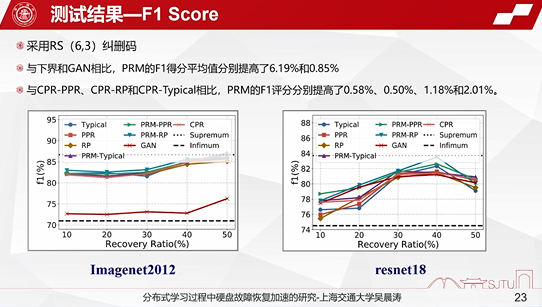
第二个方面,主要测试F1 Score。F1 Score其实跟我们的训练精度也是正相关的。前面说我们的训练精度提高了,实际上F1 Score值也大幅提升了,值分别提高了0.58%、5%、1.18%和2.01%。
第三个方面介绍的是平均恢复时间。与传统的纠删码相比,PPR、RP和传统PRM的恢复方法恢复时间分别减少57.4%、55.7%以及55.98%。与传统的方法相比,我们应用在传统的恢复方法方面减少33.5%的恢复开销,效果是非常明显的。

第四个方面主要介绍平均的网络传输时间。与传统的方法相比,分别可以减少63.4%、54.32%和53.89%的网络传输带宽。与AI的CPR相比,传输带宽也能节省32.2%,效果非常明显的。
平均的I/O吞吐率也是能得到大幅度的提升。在这4个数据集下面吞吐率分别提高了1.258倍、1.325倍、1.36倍和1.327倍,效果也是非常明显的。
总结
此次主要介绍面临故障场景高效保障分布式机器学习任务的正常运行。
与当前的训练数据相关的一些数据,我们实际上会实现优先恢复,从而能够达到训练过程当中更好的精度的保障。与数据集相关的广度相关的一些数据集,我们也会去做一些优先恢复,从而提高它的恢复速度。在这两方面我们分别去做部分恢复并且把它进行融合,能够达到更好的恢复速度,并且实现更好的支撑上层分布式机器学习的训练效果。
以上就是我这边的主要汇报,其他的部分我们后面再进行详细的交流。
谢谢大家!



