
在日前的一次采访中,Cloudera大中华区技术总监刘隶放介绍了Cloudera混合数据的公司新定位。

“Cloudera是一家混合数据公司。” 刘隶放说。这并不等同于我对Cloudera的认知,在我的认知中,Cloudera是一家大数据公司。
从大数据到混合数据,这期间发生了怎样的改变?

所谓“混合数据”最终是要落在Cloudera数据平台上,用于支持现代数据应用。
数据应用离不开硬件支持平台、数据分布、编排以及多功能分析等过程。如果熟悉Cloudera所提供的大数据功能模块和工具,就会知道在每一个部分,Cloudera都提供了对应的产品工具,不论是用来构建湖仓一体,还是进行数据编排、调度,以及最上层的数据创新和应用,Cloudera一应俱全。
对于Zookeeper、Mesos、Fafka、Sqoop、HBase、Impala等功能模块和工具,大数据是从技术的角度对其进行描述,而混合数据则是从数据和应用层面对其进行描述,在我看来本质上并没有区别。
“Cloudera是一家混合数据公司。”更多还是为了顺应“数据生态系统架构”的潮流。
很多时候,为了满足数据创新应用发展的需要,我们需要构建什么样的架构来管理数据?用户会有这样的思考和疑问,需要方法论上的突破。
从这个角度来说,以往的数据架构是一种集中管理的架构,但在实际的应用中,也出现了一些问题。例如以域数据为例,中心化集中式的数据管控,其对数据的理解,未必如业务部分。这也好理解,Splunk就强调对于字符串的检索和分析能力,以138xxxxxxxx为例,业务部门就会清楚的知道其背后的含义,以及号段划分的原则和方法,域数据也是如此。中心化数据管控并不能够很好满足数据应用的需要。为此,Data Mesh、Data Fabric等新的数据架构就被提了出来,非常流行。

湖仓一体也是如此。
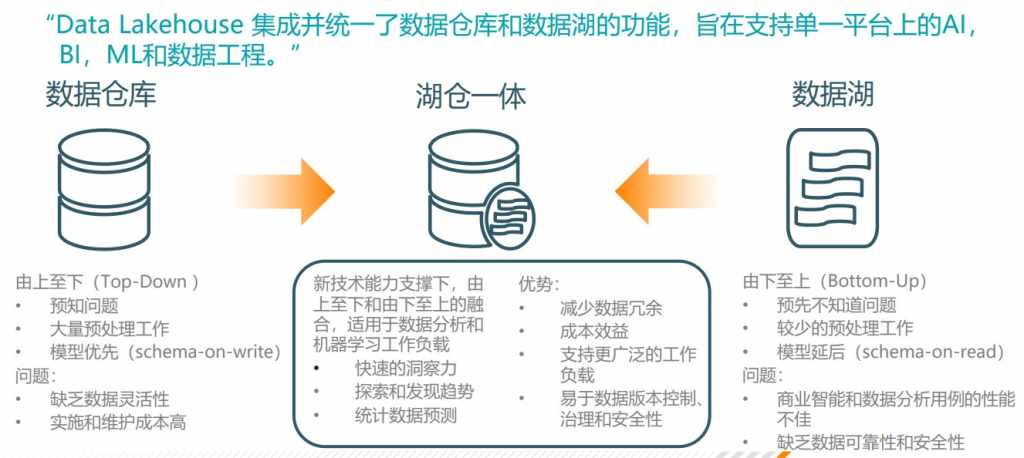
从数据仓库到数据湖呈现不同的技术特点,从预知问题、预先不知道的问题;从模型优先到模型延后,不同的需求,就有不同数据组织的方法。
但是如何的理论和模型都使用来指导实践的。当我们关注Data Mesh、Data Fabric、Data Lakehouse这些概念,当我们关注Hudi、Delta Lake,Iceberg等这些具体的落地技术时,我们应该知道,Cloudera是一家需要的公司,所谓殊途同归!
我想也许这就是Cloudera推出混合数据新定位的原因!对此,你怎么看?
