
传统数据湖面临性能挑战
随着数据分析和人工智能应用的普及,企业数据量大增,创新业务层出不穷,企业对数据分析灵活性、性能和成本的要求越来越高,传统大数据Hadoop系统搭建的数据分析平台已无法满足企业的要求。越来越多的企业以数据湖为基础构建大数据处理平台,数据湖的典型特征是存储和计算分离,能够降低系统成本同时获得更好的系统扩展性。
数据湖架构使得企业可以在一份数据上拓展创新业务,而不必每发展一个新业务就做一次数据拷贝,但传统数据湖方案在性能上仍然存在明显的缺点,传统数据湖依赖云存储,虽然降低了存储成本,但在数据分析的过程中完全依靠云存储自身的吞吐能力进行数据扫描,这种方式只适用于ETL、批量计算等时延不敏感的应用,却无法支撑秒级数据检索、时序数据分析等低时延的分析场景。
数据湖支撑大数据分析和机器学习平台
除了服务传统的Hadoop/Spark大数据分析平台,数据湖还需要满足AI算法的模型训练和推理、数据归档的需求,这要求存储系统支持多种协议以提升处理效率。比如在自动驾驶模型训练及分析场景中,车辆采集的视频、雷达数据需要通过文件或对象接口导入存储,然后通过HDFS接口对数据预处理,预处理结果再通过文件接口由计算服务器进行AI训练和高性能仿真,从而得到新的算法和模型进行下一轮测试。这些需求不是单一的对象存储或HDFS存储能够支撑的,需要更专业的存储平台提供服务。
杉岩数据的MOS海量对象存储通过异构纳管的方式,可以整合管理已有的HDFS数据源和NAS数据源,通过混合云存储方案,可以将存储在公有云的数据也纳入到MOS对象存储池统一管理。杉岩数据近期发布的MosFS高性能数据湖文件网关在系统架构中位于MOS对象存储池之上,为Hadoop/Spark大数据分析平台和TensorFlow/PyTorch/Caffe等机器学习平台提供原生的HDFS接口、S3/OSS对象接口、POSIX文件接口。
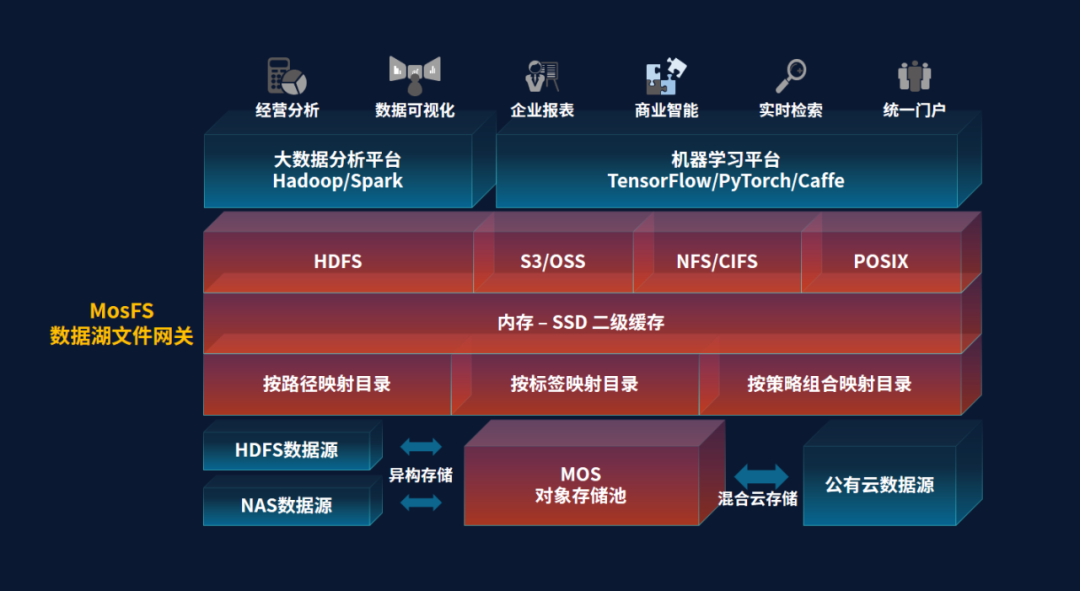
图1:数据湖文件网关架构
MOS对象存储和MosFS文件网关组合构建的数据湖架构为企业统一管理众多的数据源,实现高性能存储和数据治理提供了坚实的基础。
·高效率的多数据源管理
MOS可以纳管第三方的NAS存储、对象存储和HDFS数据源,并通过映射的方式对上层提供数据服务,可以在现有的IT架构中实现存储系统的快速割接,漫长的数据迁移可以在后台异步执行。统一管理的数据可以为多套平台和应用服务,不需要多重复制,减少对存储空间的需求。
·内容感知的多级缓存加速
机器学习平台在模型训练中要求数据的超高吞吐量和超低延迟,MosFS可以和上层应用联动,通过标签感知与应用关联度高的数据,机器学习平台可以通过路径、数据标签、多策略组合等方式得到相关性高的数据集。在实际运行中,MosFS把上述数据映射成目录,并通过内存和SSD多级缓存来加速数据访问。比如在自动驾驶的训练中,算法需要所有车辆在白天的四车道上捕获的视频和图片,MosFS就可以通过这些数据特征对应的标签,将MOS存储资源池中的相关数据映射为一个目录,并通过多级缓存提供给训练算法。
·多策略数据映射简化管理
MosFS的数据映射能力实现了数据访问的虚拟化,并通过全局命名空间将数据呈现给上层应用,基于时间、标签、文件名前缀等多粒度策略可以简化对数据的管理。
性能逼近本地全闪存的分布式数据湖文件网关
MosFS文件网关与MOS对象存储可以合设也可以分离部署,为了满足机器学习平台超高吞吐量和超低延迟的性能要求,通常将MosFS分布式部署于计算服务器,在这种情况下,MosFS将计算服务器的本地预留内存和SSD组成一个分布式的缓存层以加速训练。传统分布式NAS作为机器学习后端存储的方案具有成本高昂、数据与其它类型存储不能互通等缺点,数据管理复杂造成训练效率低下,相比而言MosFS的方案可以管理MOS、原有NAS和HDFS存储,统一所有数据视图,且分布式数据缓存可以将训练效率提升多倍,性能接近于使用计算服务器的本地SSD。
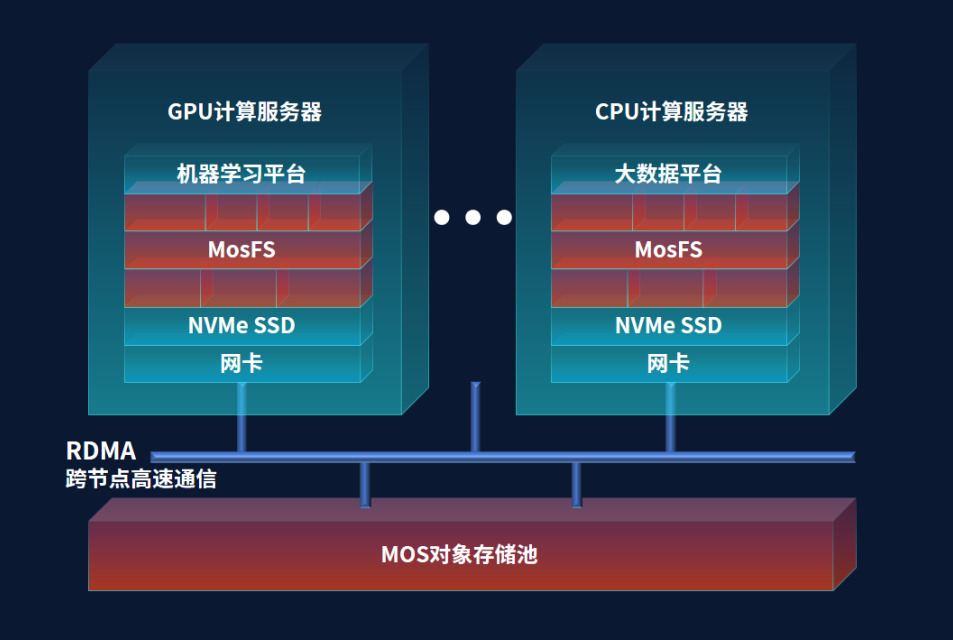
图2:数据湖文件网关分布式部署于计算服务器
HDFS协议增强实现大数据存算分离
HDFS作为传统的数据仓库存储平台在数据湖场景下面临性能和成本的问题。在实际应用中,在10~20PB以上的数据规模下,HDFS的性能下降严重,另外HDFS基本只支持多副本的存储模式,对纠删码的支持效果不佳。MosFS和MOS组合构建的数据湖存储兼容HDFS接口和S3协议,可以实现存储和Hadoop计算平台的分离,帮助客户把HDFS的数据统一归集到MOS存储中,实现非结构化数据、半结构化数据和结构化数据的统一管理。MosFS提供的原生HDFS接口100%兼容主流平台,并在内部实现了S3/OSS与HDFS接口协议的互通转换,避免数据多次拷贝。
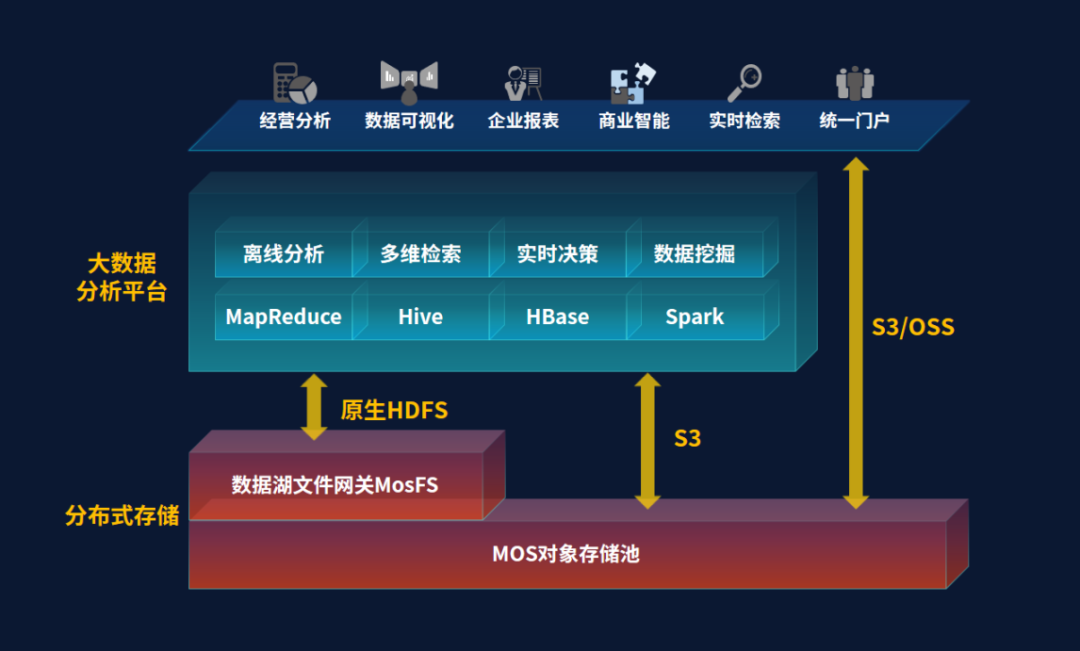
图3:数据湖架构实现存算分离
大数据分析和AI训练推理融合的需求越来越多,传统的大数据存储仅提供HDFS接口,大数据分析的结果如果用于AI训练,需要把数据拷贝到其它存储中处理,导致数据分析整体效率的低下,也浪费了存储空间。杉岩新型数据湖架构既能提供HDFS接口用于大数据分析,又能提供文件和对象接口用于AI训练推理,大数据分析结果可直接通过文件接口访问,无需拷贝和等待,很大程度上提升了融合场景的大数据分析效率。
AI训练实践案例
类脑智能技术及应用国家工程实验室是由中国科技大学组建,由中科院、复旦大学、微软、百度等机构共同承建的国家工程实验室,中科类脑成立于2017年,是该实验室的产业化平台,通过搭建“先进人工智能算法+公有计算云+私有部署云”的智能混合云平台,对外提供计算资源、人工智能技术、智能化解决方案等服务。
中科类脑开发的类脑云OS提供了大规模算力、数据和智能技术,有效降低人工智能创业门槛,能够促进人工智能应用生态的发展,赋能各行业完成智能升级转型。目前该平台已经汇聚了180项AI前沿算法、100类通用数据集,具备丰富的平台建设和行业落地经验。
杉岩新型数据湖架构已经在类脑云OS得到应用,根据中科类脑的训练方案,数据集分别放在本地SSD、分布式NAS存储和杉岩MosFS+MOS上,性能对比测试结果表明,MosFS训练耗时与本地SSD接近,对比分布式NAS,MosFS在单GPU节点下读取性能提升62.5%,双GPU节点分布式训练的性能提升75.8%。集群规模越大,杉岩数据湖方案的性能越能得到体现,表现出了优秀的扩展性。
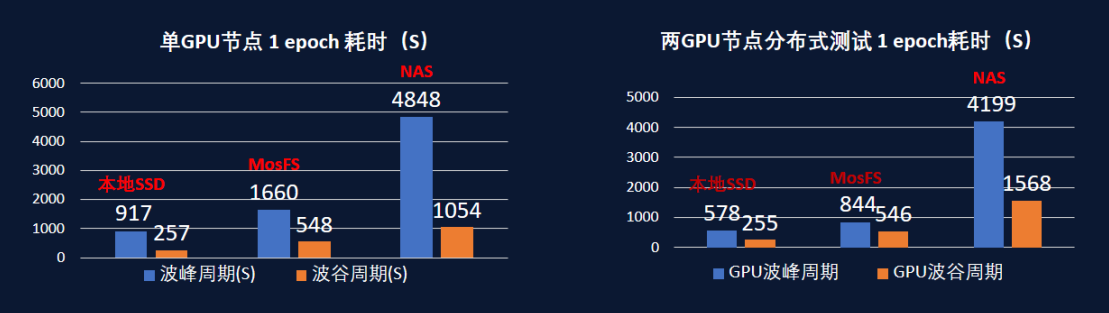
图4:本地SSD、MosFS、NAS的模型训练性能对比
小结:智能应用和大数据分析需要智能的新型数据湖
数据基础设施正在走向智能和融合。数据湖如果不能实现有效的数据管理,就会变成“数据沼泽”,智能管理要求存储提供多维度的检索能力、生命周期管理能力以及数据可视化能力,实现数据的合理分类与管理,加速数据清洗、转换、流动的过程。存储与计算架构实现分离,结构化数据、半结构化数据、非结构化数据统一存放在数据湖中,海量的数据得以在数据湖中实现融合,不同类型数据存储的界限逐渐模糊。
人工智能和大数据分析应用的融合使得一份数据能够同时提供给多个计算及分析流程使用,新一代数据湖存储平台必须具备多源数据管理能力,包括混合云能力与异构纳管其它存储的能力,以及可智能感知内容的高性能多协议数据服务能力。新型数据湖架构必将为数据分析和智能应用的开发和运行带来巨大的便利,加快迭代分析过程,简化基础设施需求,提供综合的数据服务能力,方便人们高效率地提取数据价值。
