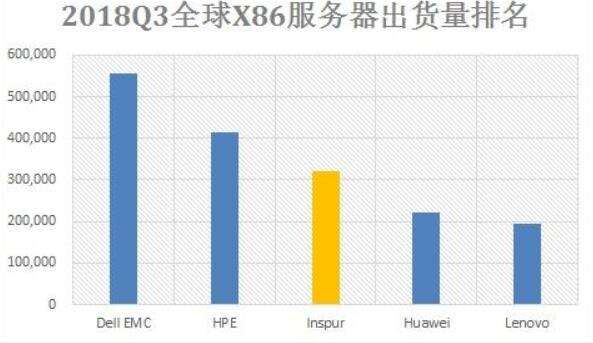
在Hadoop、Spark以及Kafka这一代大数据平台引领风骚10年以后,迎来5G时代。
5G催生车联网、智能制造、智慧能源、无线医疗、无线家庭娱乐、无人机等新型应用,人和物、物和物之间的连接产生的数据井喷式海量增长,数据类型也进一步丰富, AR、VR、视频等非结构化数据的比例进一步提升。
传统数据处理架构三大弊端
当下许多互联网公司搭建的大数据处理平台,往往对实时数据和历史数据进行严格区分,这样既带来了数据存储空间的极大浪费,同时也加大了应用程序开发的负担。而且依照流程,数据会首先注入到Kafka(一个Message bus),随后根据这个Message bus分两条线去处理,或通过Spark Streaming去处理实时数据,或按传统的ETL方式如Hadoop或Elastic去批处理集中得到批处理结果。

这样的架构存在三大问题:
一是它把数据根据时间的属性走向两条处理逻辑,应用程序的处理逻辑会被写两遍;
二是这样的架构要得到批处理的正确结果才可以做聚合处理,对实时处理平台而言带来的是无法忍受的延迟;
三是原始数据在不同的开源项目当中被拷贝了多份,如在Kafka中会有3拷贝,到了Spark Steaming还会有3拷贝,在整个系统和里存在6份甚至是9份拷贝的现象都很普遍。但其带来容量的需求对客户来说是一场噩梦,尤其是AI引入之后数据的增速是爆发式的。关键的是,Message bus并不是一个存储系统,在Kafka中的数据并不能保证被长期存储。而对大数据处理平台来说,最重要的是先得把数据存下来才谈得上发掘出更多的商业价值。
另外,Hadoop只能针对历史数据做批处理,Spark和Kafka只能对Pub/Sub系统进行梳理。可以说,传统大数据平台并不完美。
可以说,传统单一的计算平台已经无法应对如此复杂、多样、海量的数据采集、处理的挑战。
海量、低时延、非结构化的数据特点将进一步促进数据处理和分析技术的进步,推动流式处理技术的发展。
那么,应对5G和物联网时代的下一代大数据处理平台,需要具备哪些能力?
5G时代呼唤新的数据处理平台
2019年12月初的戴尔科技集团上海研发中心之旅活动中,戴尔科技集团Dell EMC软件工程总监滕昱首先分析了大数据处理领域近期的三大趋势。

一是在Amazon S3A推出之后,凭借其高可用容量和可扩充性等特点逐渐形成对Hadoop分布式文件系统(HDFS)的取代之势,流式大数据处理平台存储端工作负载显著增加;加上Hadoop可以直接运行于S3A上,突破了绑定于HDFS上的限制。可以说,2020年将会是从HDFS转向流存储的元年。
二是在容器编排战争中,Kubernetes赢得了胜利,意味着未来的软件平台都将以Kubernetes为基础,在各种各样公有云和私有云中自由地进行工作负载的迁移变得更加容易。
三是在计算方面,除了要求准确结果,还需要满足更多实时计算的需求。一个经典的用例就是银行实时监控的需求,除了能对线上数据进行实时监控处理,还要同时能调用历史数据。类似的场景还有IoT和5G,特别是车联网的连接等越来越多的领域。
为了满足层出不穷的实时应用场景,同时降低大数据应用平台的投入,戴尔科技集团决定推出一个 “All in one”的新的大数据处理平台,即Dell EMC流数据处理平台(Dell EMC Streaming Data Platform,简称“DESDP”)。
起底Dell EMC流数据处理平台
Dell EMC流数据处理平台是戴尔科技集团从零开始构建的一套实时流式数据分析与存储解决方案,旨在为编写可靠的流式应用程序提供基础。
借助于该平台,客户除了通过诸如S3一类的接口传输数据,还可以通过Dell EMC即将提供的Streaming接口去注入数据,计算端不再需要了解数据的来源及传输过程,仅需使用SQL或者通用的搜索语法,即可从数据中实时获得商业价值。
Dell EMC Streaming接口与众不同的最大特点,是它能接入流数据。
流数据具有四个特点,一是数据实时到达,二是数据到达次序独立,不受应用系统所控制,三是数据规模宏大且不能预知其最大值,四是数据一经处理,除非特意保存,否则不能被再次取出处理,或者再次提取数据代价昂贵。
从存储端而言,流数据要求在大并发下实现实时数据低延迟的读和写,同时对历史数据要能高吞吐量的读,这样的特性才是一个合格的流存储接口。
因此,一个成熟的流数据处理平台,首要的就是能具有同时存储和处理实时数据的能力,开发者也无需根据数据的时间属性开发两套不同的商业逻辑,其次,对于企业而言,只要做好存储和计算动态的扩容和缩容,应用程序无需根据工作负载大小进行感知,第三,平台当中的数据一定会被处理而且仅被处理一次,保证大数据处理平台企业级应用的价值。
(1)Dell EMC流数据处理平台架构剖析
分析Dell EMC新的流数据处理平台架构,中间部分是计算端和流处理端,其上是分为左右两部分的流数据平台。
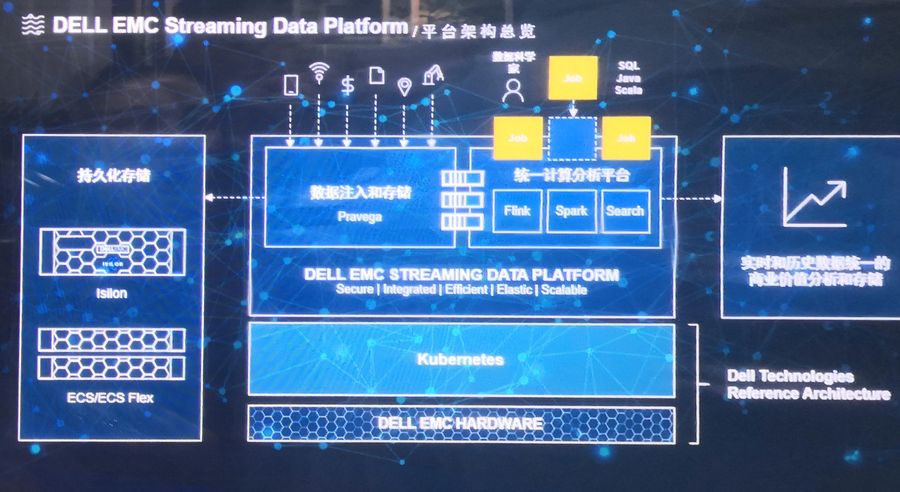
左边是Dell EMC开发并开源的流式数据存储引擎Pravega,它作为该平台的基础组件实现流存储的抽象来满足计算平台达到实时和历史数据抽象统一的要求。
数据注入到一定程度后就会放置到持久化存储中,或者是Isilon 或者是ECS,也可以是今年将推出的全新的对象存储架构。历史数据存储在Tier2的Isilon和ECS上,之后对数据处理引擎也进行了统一处理。
这种两层的架构解决了存储端去进行实时和历史数据的抽象统一。
(2)Isilon——百分百本地化研发生产的存储产品
在这里必须给Isilon打个广告。
上一篇文章曾说过,戴尔科技集团中国研发集团有两大引以为自豪的产品,一个是VxRail,另一个就是Isilon,而且是百分百本地化研发生产的产品。
谈到Isilon的应用场景,戴尔科技集团大中华区企业技术战略总监许良谋表示,解决数据孤岛就是Isilon一个典型的擅长,因为它海纳百川,支持各种协议。另外,Isilon还可当作数据的承载,用这样的方式去解耦,甚至还可以在VMware上做Hadoop,帮助客户降低成本。这在制造业的优势尤其明显。除此之外,Isilon在媒体、生物科技以及基因测序等领域的需求都非常旺盛。

戴尔科技集团全球资深副总裁、大中华区企业解决方案总经理曹志平补充说,风靡2018年的电影《哪吒》也是在Isilon平台上完成的三维动画渲染;每一次展会上戴尔科技集团Isilon支持播放的自动驾驶的辅助设计系统效果最好,因而受到很多的汽车厂商的青睐,Isilon行业的应用是非常普遍的。
戴尔科技集团中国研发集团上海研发中心总经理陈春曦很风趣:作为一名高科技研发工作者,他自我感觉很高大上,但在他母亲眼里他一直就是一个“修电脑“的。《哪吒》上市后,他告诉母亲说影片采用的就是他参与研究的成果,令母亲对他从此刮目相看,自己在家里的地位也提高了不少。

“所以要感谢《哪吒》!” 陈春曦开心地说。
回到Dell EMC新的流数据处理平台架构,在该图右边的计算平台方面,Dell EMC与开源社区合作,创建和管理Flink集群并集成了Flink的企业特性,以现代流行的开源方式提供运营能力——将内部的Metrics(指标)开源给成熟的硬件供应商,同时大量简化开发框架。毕竟流处理和实时处理对应用程序开发者来说也是一个新的挑战。
除了2019年新支持的Flink,Dell EMC今年还将支持Search,把它们的功能带入流处理世界。
最终,只要写Flink SQL或Search语义,平台就可以从这些数据中抓取商业逻辑。这是企业级下一代数据处理平台最重要特点,也就是前面提到的,客户只需通过对象存储接口、文件接口或新的Streaming接口注入数据,在分析端,完全不需要了解下层数据是款如何被存储和计算一类的各种复杂环节。
一切以客户为中心
Dell EMC流数据处理平台并不只针对流数据处理,它可以处理实时数据和历史数据,目的是取代以Hadoop和Spark、Kafka为代表的现有大数据处理平台。Dell EMC新的流数据处理平台是一个扬长避短,或者说是取长补短后达成一个统一的架构。
基于新的架构,Dell EMC在数据注入端和存储端做到历史数据和实时数据的统一,而且因为开源,高度的安全得以保证,最终智能地降低了用户在DevOps上的开销。
所有这一切创建的Dell EMC流数据处理平台,终极目标就是为了降低客户拥抱新平台的投入,同时提供关键的安全隔离、稳定和容易支持的特性,帮助客户加速数字化转型。

采访的最后,滕昱表示,“现有技术无法满足现有用例的需求,就是技术进步的动力。Dell EMC真的是从客户那里收集这些要求去设计各种新的架构的。”