
5G、AI和云的技术应用逐渐普及伴随数据量暴增。据预测,2018年至2025年,全球数据量将从33ZB翻增至180ZB,从2K向4K、8K分辨率过渡数据增长达到40倍。从4K转向4K/VR还会有6倍数据增长,再加上未来L4级自动驾驶汽车每天都将产生可观的64TB级数据量。
将这些日常数据进行时限三十天的存储已经是非常惊人的数字了。但未来我们还要保存的更多更久,从而导致了巨大的存储需求落差。
然而落差不仅限于此。这些数据仅2%得以保存,在这2%的数据中,又只有10%的数据可以进行分析利用转化价值,进而出现数据激增与我们对实际应用于计算。存储资源之间的落差。因此,我们亟需构建更完善、更具优势的数据基础设施助力各行各业实现数据存储智能化、管理简单化和价值最大化。

近日,由百易传媒(DOIT)主办,以“数智·未来”为主题的2019中国数据与存储峰会(DATA & STORAGE SUMMIT)在北京召开。华为智能数据与存储领域副总裁张福鹏在会上发表了《打造“融合、智能、开放”数据基础设施,携手迈入智能时代》主题演讲。
开局:从数据存储进阶数据基础设施建设
如果是在去年来到这里,我可能会讲存储,但自今年5月15号华为发布GaussDB数据库,华为开始讲数据基础设施,刚才DOIT发布了数据基础设施全景白皮书,华为11月份也发布了数据基础设施白皮书,数据基础设施已经逐渐成为大家的共同认知。今天有幸和大家分享一下我们怎样打造数据基础设施。
华为公司使命和愿景是把数字世界带入每个人每个家庭每个组织构建万物互联的智能世界,我们不再按照原来的以产品捕捉市场。现在智能世界的新认知是,算力成为新生产力,数据成为新生产资料,5G+云+AI成为新生产工具,三者相互作用将带来智能时代的最佳实践,使得数字经济获得更好发展。
9月18号,华为首次发布整体计算战略,发布“一云两翼双引擎”,今天主要介绍这个战略中如何围绕数据的采、存、算、管、用构建自身的能力,打造融合智能开放数据基础设施,释放数据价值,让智能无所不及。
智能时代让数据从管理走向运营
首先数据驱动客户体验。我们打开一个APP能收到自己感兴趣的内容,精准推送背后是数据在驱动。例如快手平台上每天产生1.2亿个数据标签,背后与用户画像进行实时匹配,然后进行内容精准推送。
数据驱动企业决策。以某油田为例,多年的开采导致产能产量有所下降,采用华为大数据和AI解决方案以后,通过测井曲线分析找到新的油层渗透率和空隙率,从而找到新的油层,保持每年500万吨的产量。
数据驱动体验变化。以华为为例,每年约有三百万人出差,过去差旅费用考勤,需要十几个电子流,现在一个电子流足矣,每天有45万数据碰撞,让华为可以更好地做到内容的开发。
综上所述,华为不再局限于单一场景,而是致力于对数据的采、存、算、管、用进行端到端整合优化,让数据在全生命周期内更好地用,数据每比特价值最大,每比特成本最优是数据未来的方向。
如何打造融合、智能、开放的数据基础设施
打造融合、智能、开放的数据基础设施要通过打破数据处理与数据存储的边界,实现数据的高效共享和分析,降本增效。通过AI+存储+云的方式,数据周期内自动管理自动运营,存储越用越快,价值越来越大。通过数据虚拟化引擎,让用户像使用数据库一样使用数据,数据系统从孤立走向融合,从复杂走向简单,从封闭走向开放。
融合,数据应用核心是存储和分析,过去烟囱式IT系统带来两个问题——不同场景下产生多个副本,数据不能流动,成本高,分析时导致大量数据迁移,出现分析效率问题。华为通过打破存储内部的系统墙,数据库与存储的链路墙,大数据与存储之间的配置墙,数据库和大数据协同墙实现数据每笔成本会更优。

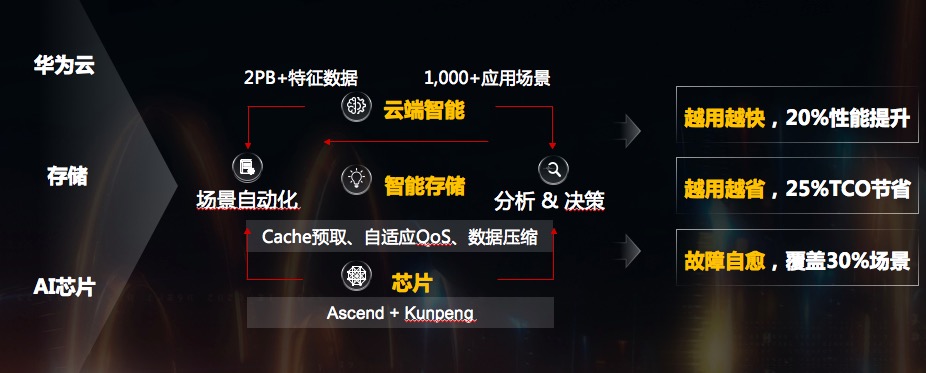
智能,过去整个网络数据的运营靠人工配置,靠个人经验和能力决定效率高低,华为基于AI芯片、存储设备和华为云三体架构,云上训练、云下推理的方式,越用越快,越用越省。依托生成AI的能力,自动学习和识别IO流中的数据,提升cache预取命中率,提升20%系统整体性能。
依托鲲鹏多核计算的能力,依据不同业务类型数据类型实时进行数据缩减算法的调整,让TCO降低20%。
结合华为云大规模运营经验,当前可提前14天预测故障硬盘,提前60天预测性能瓶颈。可以提前365天预测容量的不足。这当中30%的故障可以实现自愈,为客户极致体验。
开放,随着业务类型逐渐增多,大量业务下面需要跨平台跨数据协同分析,我们认为有三个问题,找数难,不同类型的海量数据放置目录不同,搜索特定如同大海捞针;取数难,尤其分析型业务需要跨多机构、系统、平台获取数据;用数难多业务分析需要多访问技术,开放门槛高。
华为河图引擎:从“大数据”走向“大数据库”
华为推出的河图引擎,引自“大禹得河图始清明”的传说。希望帮助企业掌握数据的情况。让开发者如使用数据库一样使用大数据,复用现有生态技能,效率提升2到10倍。
河图引擎具备四个核心能力:
- 一个目录:通过源数据的感知,构建一千多个以上异地异构数据源,形成一个虚拟的数据视图,打破数据孤岛,让使用数据全局可见。
- 一个接口:通过开放式的连接架构,五千个节点,实现30种异地异构的数据,数据源能够深入访问,数据可以以秒获取,数据全局可得。
- 一份数据:通过CarbonData技术实现一份数据、多场景分析,多应用共享,数据0搬迁,数据全局可用。
- 统一安全:通过细粒度动态授权,敏感数据自动识别,实现异地异构数据中心,数据的授权时间从天到秒解决安全和合规的问题。
河图引擎还将在2020年6月为大家提供开源版本。openHetu具有三方面,包括北向应用接口、南向数据接口和内核引擎。
- 开源北向应用接口支持更多应用,确保上层的数据治理和数据应用软件可以更加好地对接数据基础设施;
- 开源南向数据接口,可以确保更好的集成进来,方便伙伴们使用;
- 开源核心引擎,主要是确保合作伙伴们能够,免厂商锁定
伙伴和客户可以基于开源代码进行定制、优化,实现更快、更好的业务系统对接,简化应用开发难度,提升企业IT系统内部数据协作能力,获得商业价值。华为愿与广大伙伴一起,共建开放、繁荣的河图生态,让数据更简单,让商业更敏捷!

数据基础设施围绕三大场景构建解决方案
数据基础设施构建围绕生产交易,数据分析以及边缘业务三大场景构建解决方案。华为不只是提供存储产品服务,而是有三个场景为客户提供内容。
OceanData提供多样性的算力,能够把数据的存储和数据的处理结合,这个场景主要实时性高可靠性,面向金融要求实时性场景。
FusionData支持核心生产场景,打通各个数据孤岛,通过数存的融合,协议的互通,实现分析效率的提升,存算分离实现资源灵活扩展,避免计算和存储不足,这样让客户节约TCO。
华为还发布了FusionCube 2.0版本,即插即用2.0版本中内置芯片卡,分析能力提升两倍以上,在云端进行训练,本地进行推理,无需大量消耗网络带宽、避免5G部署困难。
除了三个场景之外,如何进行数据基础设施的自动化驾驶,这个驾驶当中为了减少大家以后在复杂的数据投入方面的OPEX,云上成为eService,可以进行天级别和月级别的训练,使得你来完成一个跨厂商、跨企业这样一个训练,全域管理。
当然,构建完备的数据基础设施只靠华为一家是不够的,还需要更多的产业联盟来共同推动发展。因此华为成立了鲲鹏智能数据产业联盟,包含四个推进组,其中数据库,大数据,智能边缘产业推进已经成立,明年存储产业推进组的构建已经在计划中。
华为始终践行“平台+生态”策略,华为将为产业提供融合、智能、开放的数据基础设施,通过数据虚拟化引擎HetuEngine,让更多的客户和伙伴,享受数据在全生命周期内好用,每比特价值更大,每比特价值更优。有了河图引擎、“数据平台+生态”战略,将更有利于创造一个共赢的生态环境。




