
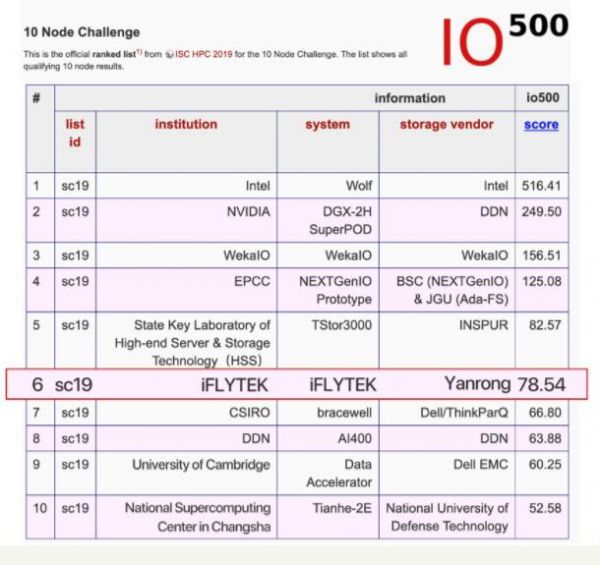
11月18至21日,代表高性能计算和存储行业最高水平的年度盛会SuperComputing 2019在美国丹佛举行,与计算性能Top500榜单相对平稳的排名和趋势相比,IO500榜单的竞争显得异常激烈。焱融科技本次携手科大讯飞基础架构团队,在焱融科技YRCloudFile的基础之上,进行了大量创新性开发和调优,最终提交的IO500十节点性能测试数据在激烈的比拼中位列全球第六。相对于上半年的成绩,存储性能有了400%的提升。这次联合测试的成功经验,标志着焱融科技与国内顶级人工智能企业在技术攻关过程中取得了较大突破。
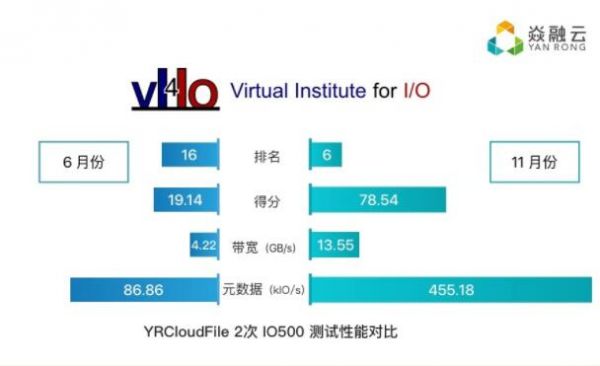
从发布的结果上看,焱融科技本次测试的结果比上半年提升了4倍。这得益于焱融科技前期与科大讯飞的紧密沟通,让我们对人工智能这种需要高性能存储支持的典型场景有了更深入的理解。在此基础上,双方工程师做了针对性的开发和优化,从而获得了满意的成绩。
在《最新全球IO500名单出炉,焱融云跻身存储厂商Top10》一文中,我们对IO500做了基本的介绍,很多客户和同行对IO500表现出强烈的兴趣。在此我们再深度剖析一下IO500,进而了解为何众多高性能存储和计算的行业领导者对该榜单都高度关注的原因。
总的来说,IO500十节点测试共包含了12项测试任务,测试限制在10个客户端上执行,评估总体集群的性能表现。这12项测试模拟了各种或简单或苛刻的IO场景,涉及数据吞吐、元数据等方面操作。以下我们按执行顺序来看这些测试任务的含义,并分析这些测试背后对应的实际应用场景:
1)ior_easy_write:
多个客户端、多个任务、并发地、顺序地、独立地向存储集群中写数据,这一项主要测试存储集群的写入能力。默认每个任务写入9.9TB,200个任务会写入PB级的数据,这个测试模拟了传统HPC写入密集型应用场景。
2)mdtest_easy_write:
多个客户端、多个任务、并发地、独立地向存储集群中创建大量空文件,每个任务独占一个目录,这一项主要测试存储集群元数据的处理能力。默认每个任务写90万文件,200个任务共写入1.8亿文件。这个测试模拟了新兴的人工智能场景中写入海量文件的场景,侧重于元数据性能的测试。
3)ior_hard_write:
多个客户端、并发地、共享地写同一个文件,每个任务每次写的数据量是47008 Bytes,这一项主要测试协同写单个文件。默认每个任务要写190万次,每次写47008 Bytes。这一测试模拟的是传统HPC场景,多个计算任务同时更新同一个文件时,文件系统锁以及并发写入的能力。
4)mdtest_hard_write:
多个客户端、并发地创建大量文件,创建文件后,会写3901Bytes数据,所有任务的文件都写到同一个目录下。默认每个任务写95万文件,200个任务共写入1.9亿文件。这个测试也是模拟新兴的人工智能场景中写入海量文件的场景,与mdtest_easy_write侧重元数据性能测试不同的是,mdtest_hard_write会同时考察文件系统数据写入的能力。
5)find:
对前面创建的大量文件去做find查询,考察海量文件下,基于标准POSIX语义的文件系统查询性能。
6)ior_easy_read:
多个客户端、多个任务、并发地、顺序地读取自己在ior_easy_write阶段写入的数据。该测试模拟传统HPC场景中,多客户端并发读取数据的过程。
7)mdtest_easy_stat:
多个客户端、多个任务、并发地去stat自己在mdtest_easy_write阶段创建的空文件,这个测试模拟人工智能等应用,在海量文件场景下对文件系统最常用的stat操作性能(文件系统的大量操作会调用到stat接口)。
8)ior_hard_read:
多个客户端、多个任务、并发地去读取自己在ior_hard_write阶段写入的文件,每次读取数据量47008 Bytes。该测试模拟传统HPC业务,多个计算任务并发加载数据的过程。
9)mdtest_hard_stat:
多个客户端、多个任务、并发地去stat自己在mdtest_hard_write阶段写入的文件,stat之后再读取3901 Bytes数据。该测试模拟人工智能业务检索、open、随后读取文件的过程,并评估这一过程的性能。
10)mdtest_easy_delete:
多个客户端、多个任务、并发地去delete自己在mdtest_easy_write阶段创建的文件。该测试模拟元数据集群对海量空文件并发删除的支持和性能。
11)mdtest_hard_read:
多个客户端、多个任务、并发地去读取自己在mdtest_hard_write阶段写入的文件,读取3901 Bytes数据。该测试模拟人工智能业务对元数据集群open,并读取指定小文件内容的性能。
12)mdtest_hard_delete:
多个客户端、多个任务、并发地去delete自己在mdtest_hard_write阶段创建的文件。该测试模拟文件系统对海量小文件元数据以及数据删除的性能。
从这些测试项可以看出,IO500主要测试了四大类场景:
1)存储集群的吞吐能力,验证多个任务顺序写,相互之间有无数据冲突,看集群能提供的写入、读取吞吐的上限。ior_easy_write、ior_easy_read主要用于测试这个场景。
2)存储集群对于共享读写的处理能力,多个任务共享、协同地读写同一个文件,需要做一定的并发控制,否则测试将因数据错乱而报错。ior_hard_write、ior_hard_read主要用于测试这个场景,这部分测试针对的是HPC的典型IO类型。
3)存储集群对于小文件IO的处理能力,比如mdtest_hard_read、mdtest_hard_write的读写3901 Bytes,如果数据布局不当,这项测试的性能值会很低。
4)存储集群元数据的处理能力,重点考察集群创建、查询、删除文件的性能。其中md_hard_*还会去测试单个目录下大量文件(单目录下1.9亿文件)这个场景的性能。
YRCloudFile为了支持单目录下海量文件的测试,改进了原有的元数据放置策略算法,增加了虚拟目录层,用于拆分海量文件的目录,分散目录热点,从而提升总体性能。在测试中,YRCloudFile在海量小文件场景下表现突出。
通过2019年两次参与IO500测试,我们在不断学习和追赶国际领先存储企业的先进技术,分析IO500的测试,我们可以看到:
1) IO500委员会由存储业界知名学者和专家组成,为了加强测试数据的中立,在下半年测试中,委员会针对测试脚本进行了修正,更加确保测试数据的公平、公正,同时模拟真实的高性能计算及人工智能场景,其测试数据可作为评估存储系统总体能力的一个重要指标。
2) 参与的厂商持续保持非常高的热情和投入,上半年16家,下半年15家,既有传统厂商如DDN、NetApp、Dell、IBM、HPE、浪潮,也有新兴存储厂商WekaIO、Qumulo、焱融科技,各家都非常重视IO500的测试成绩,一方面这是国际上对存储性能的公认指标,另一方面由于IO500测试脚本模拟的真实的IO场景,对于各个厂商持续改进产品也是非常好的输入。
从测试结果看,焱融科技和科大讯飞此次发布的测试数据,也是在对YRCloudFile做了针对性改进后获得了优异的成绩。
接下来,焱融科技将深入总结此次测试中获得的宝贵经验,将多项技术创新进一步反馈到产品中,帮助国内众多人工智能、高性能计算的用户持续提高AI训练和数据分析的性能,为客户提供更优秀的国产高性能存储产品。
