
8月22日-23日,2019全球闪存峰会(Flash Memory World)在杭州国际博览中心正式召开,盛邀众多存储行业技术专家与知名企业代表等发表主题演讲,以便更快更好地推动闪存及芯片市场发展,增进产业上下游交流与互动。

美国德克萨斯大学阿灵顿分校教授,IEEE Fellow, 同时也是阿里巴巴达摩院的项目专家,江泓(Hong Jiang)受邀出席了智能存储与存储新架构学术论坛,并发表《支撑大数据的闪存系统》的主题演讲。

以下内容根据现场速记整理。
今天和大家分享一下我们在探索支撑大数据的闪存存储系统研究方面的一些经验和结果。

谈到大数据,这张图片比较能说明问题,这是经济学人刊物两年以前的一个封面。主要意思是如果上世纪全球最有价值的资源是原油,本世纪最有价值的资源就应该是数据。
对比看一下,20年以前,前10名企业绝大部分都是与石油相关的一些企业。2019年,Top5,Top10绝大部分都是和数据相关,如谷歌等等。但数据和原油不同。数据有一些是过去产生,更多是正在产生或者尚未产生。在这方面其对我们提出了很多挑战。
我们先回顾一下大数据的主要挑战和特征。它的Volume(容量)很大,数据分析速度(Velocity)要高,还有一个特点是多样性(Variety)。当对这三个V进行了很好处理以后,真正价值的才能充分体现,这就是第四个V(Value)。前三个V为存储界提出了重大挑战。因此我们现在需要更新,更快,更有效,而且更智能的存储系统。
大数据的整个生态环境,生命周期,是从数据产生,收集,清洗,到存储,管理,最后是分析以及应用。在此过程当中,存储起到一个从原始数据到数据真正发挥作用两个环节里一个承上启下的作用,一个至关重要的环节。
要真正对大数据有效率的支持需要什么呢?我们的存储容量,性能还有性价比。它对传统基于硬盘容量的存储系统提出了前所未有的挑战,比如说现在在整个市场氛围,基于容量的存储系统里,以闪存为支撑的,现在基本上和硬盘已经是平分秋色。预计在过去几年可能会逐步取代硬盘,至少按照这个预测,到2026年可能96%的Capacity将以闪存为主。闪存之所以给硬盘提出这么大的挑战,主要是存储密度在提高。
随着密度提高,存储空间增加非常迅猛。与此同时,这是一个双刃剑,读写的性能不断降低,读写之间的非对称性更大。如何能够真正将闪存用在支撑大数据,必须要解决相关一些问题。
今天我想讲的主要关注这两个问题还有其他的一些挑战。一个就是,闪存性能较难预测,今天我讲的是读写的干扰,由于读写问题,读取的延迟是写入的十分之一不到,如果读写混在一起,那么写入速度如果是正在进行,我后面读取速度就会堵住。而我们知道对大数据分析来讲,读取性能非常重要,因此这是一个很重要的问题。
还有一个问题就是闪存速度,单位GB价格还是比硬盘高出很多,如何能充分把性价比进一步提升?这就需要空间利用率的进一步提高,还有就是寿命的提升。
这个我们想借用重删技术提高写入性能和容量,同时也减少擦除次数。接下来我们主要是围绕最近做的几项工作——解决读写干扰以及如何在闪存里有效进行重删问题。
为什么会读写干扰?SLC是一个存储单元一位,MLC就是两位,那么有四种不同的方式,依此类推,TLC是三位,有八种不同的状态,导致读写过程中需要判断读写时间与量级等各种因素。
这个问题会越来越严重。我们对一些公开的问题进行了分析,然后发现的确在这几个大家经常用到的开源工具里面,平均33%的读请求被写请求给堵住了,最高达到56%。这样一来对读性能的降低是非常可观的,平均是42.8%,最高可以到75%。目前这个问题现在有一些解决方案,同时也有它们的问题。

比如P/E分析,这项工作实际上是华中科技大学何老师团队做的。在写过程中如果遇到读取,就把写工作暂停,不过虽然可以改善读的性能,但会影响写性能。
另一个方法(Rails)是把读和写分开,写的数据复制以后,将它分开处理,这个方法显然对空间容量开销很大。还有一种办法(TTFlash)是采取计算的方式避开写入,把读的几个顺序合起来,通过计算来恢复读的内容,实际上就是增加内部读取请求,一个读变成多个读,但会加剧读写互相的干扰。
我们的方法是什么呢?HotR,我们发现读写在闪存页(page)上是两级分化的。绝大部分读和写请求都分别有读取和写入密集型页面,我们把这些页分类。因为读取至关重要,我们就临时代用一个空间,这个空间可以在现有的闪存盘里。我就把热度高的读页面,暂时移动到这个System Overview上,这就避开了读写冲突。结果简单有效,我们进行了比较,平均提高非常明显。

关键是从开销和延时的层级来评估其性价比。因为不同解决方案要么对空间有要求,要么对硬件有额外要求,这样以后得出的结论应该比较公平,平均响应时间缩短54.0%,是最具性价比的。
接下来是重删问题,上午大家听了主题报告,戴尔的毕总已经提到,重删已经标准化,在很多场景里落地了。现在做是因为没有办法了,未来全球产生的必须存储的数据对比全球所有的存储空间加起来还是有大概一倍甚至两倍差。
唯一的办法就是数据压缩。现在大家证明有效的就是已经标准化的重删。
产品里面的重删是这样的,写入以后,我首先进行inline dedup(内联重删)。剩下就是我在写的时候,不能及时dedup,还是写进去,但在空闲的时候再进行offline dedup(外联重删),offline dedup可以最终减少占用的空间,但不能减少写的量。为什么要这样做呢?因为计算机的CPU能力很有限,还要做很多FTL(闪存转换层)等很多工作。
现在用的重删方法还是用传统的哈希,计算开销非常大。我们想能不能用更简单的指纹方式,数据本身每一次写入的时候,为了提高数据可靠性都自动产生一个ECC(纠删码)。实际上可以用来做一个弱哈希,弱的指纹。ECC产生是免费的,硬件里面已经产生,已经有的。如果这样我们可以通过ECC来首先判断你这个数据是不是有匹配,没有可以排除,如果有匹配,由于ECC很弱,在这种情况下因为写是读延时的10倍,所以很快就能把整个页读取出来,然后逐字节得比较。
以这种方法,我们可以把CPU计算的CR1,CR2很大的开销完全去掉,取而代之就是读,因为ECC本身不要这个。现在遇到一个问题在很多闪存里,为了避免同一个数据写在同一个物理位置上,导致里面的存储单元报废时间不均匀,很多芯片里面有固件,把这个写进去的数据在写到物理介质之前,先把它打乱,然后再写进去,保证固定位置均匀分布,读的时候重新分布。
这给重删带来一个问题,ECC代表数据的指纹。现在读了以后,ECC所针对的值就不一样了,本来两个值是相同的,是可重删的,通过读取,两个ECC不一样,针对这样一个问题怎么解决?
每一个逻辑,用随机产生数据,产生一个随机的scrambler(扰码器),这有一个对应,只要你有一个固定LBA,我的scrambler就是固定的,我们利用这个特征然后引用一些数学上的基本特性设计了一个是在Host端重建软件扰码器,一个是在Device端有选择地绕过硬件加扰器,通过查找的方式把数据恢复过来。
最后测试,Inline and offline deduplication效果比较明显,我们基于ECC的dedup方式进行比较,我们的方式所得到的重删率要高出大概20-40%之间。这个就证明这种方法还是非常有效的。
还有另外一个问题,现在闪存在数据中心,通常被用于高速缓存,这就出现一个问题。怎么能够把缓存的实际空间增大,同时提高它的缓存命中率?目前方法是2016年的CacheDedup方式,把元数据和数据缓存进行分开管理和访问,然后采取传统方式对Source Addresses进行替换算法。
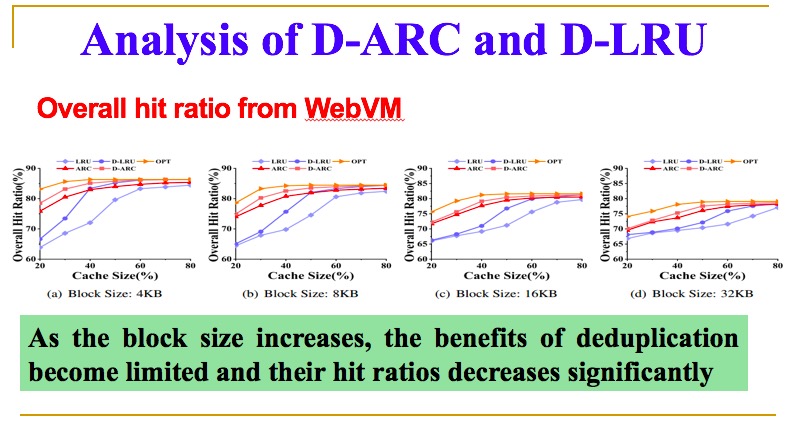
我们对现有的进行分析,发现随着你块的大小不断增加,重删率下降很快,另一个命中率也在显著下降,这样实际利用空间减少了,命中率也降低了。
最后我们发现主要原因是大家没有对重删本身特性进行进一步的挖掘,传统方法在独立的情况下是有效的,但在重删的情况下,一个物理块可能对多个逻辑地址,这种情况下,所对应的逻辑地址数量不一样,这个我们称作内容共享的程度。基于内容的局部性或者内容共享的强度来对这个进行挖掘,得出新的替换算法,最后的结果还是比较满意的,我们性能大概提高一倍。
同时读和写性能都有所提高,这个是三项工作相应的三篇文章都是今年最新发表的,我今天就介绍这么多,谢谢大家。
Q&A
Q:存储系统里,读性能的优化,垃圾回收和重删方面展示了最新研究工作,对于垃圾回收你分享的主题里面方法是很奇妙的。在页的检测时候,它的准确率大概会是什么情况?准确度会直接影响到算法的效能吗?
A:目前我们是通过对现有的开源数据进行分析,我刚才讲比较两极分化,所以这个分配目前来看,我们做的这几个数据级还比较准确。接下来如果要有更多数据级,可能就不是很准确。我们接下来希望把一些AI和机器学习技术放在这里面来做更准确的预测。
文章内容未经演讲人审核




