
AMD 7nm了,英特尔慌了?
2019年5月27日,AMD在台北电脑展上重磅介绍了基于7nm的数据中心处理器产品,不久前,英特尔也发布了数据中心处理器新品,不过采用的是14nm制程工艺,Intel要被超越了吗?英特尔慌了吗?
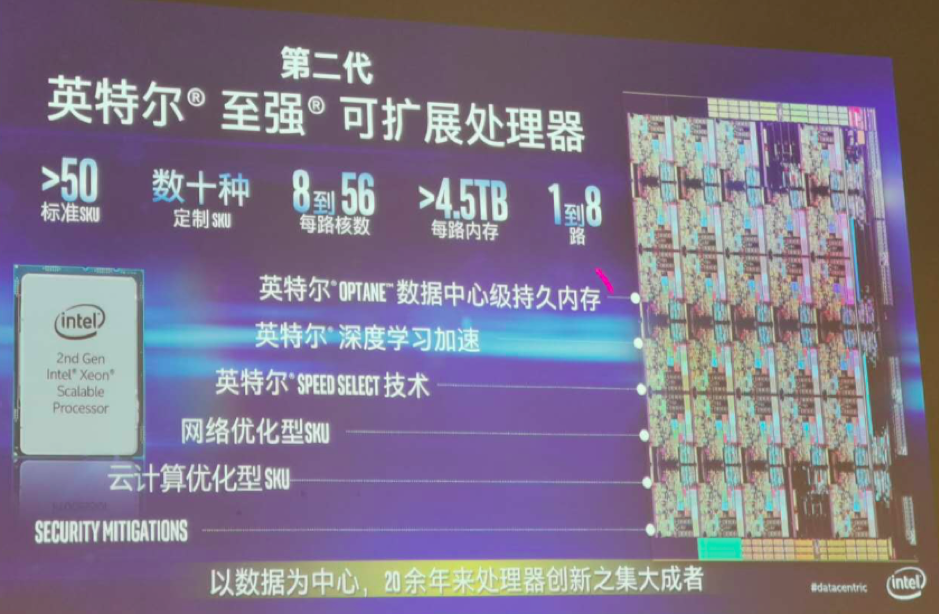
2019年4月,英特尔发布第二代至强可扩展处理器,新一代的处理器增加的功能包括对英特尔傲腾数据中心持久内存的支持,还增加了深度学习加速指令集优化AI场景、Speed Select内核控制技术,并针对网络、云计算、搜索以及边缘等场景提供对应的型号,新一代至强还增加了基于硬件的安全解决方案,减少了以前软件方案对性能的影响。
这次采用Cascade Lake架构的第二代可扩展处理器采用的还是14nm制程,早在此前,AMD的 7nm就炒的沸沸扬扬,2019年年初,英特尔表示数据中心事业部预计每 4-5 个季度推出一款全新英特尔至强产品,并计划在 2020 年上半年出货基于 10 纳米技术的“Ice Lake”CPU(客户端的10nm Ice Lake会在今年6月份出货)。
此外,英特尔 7 纳米制程也已列入日程,首款7纳米产品将是基于英特尔 Xe 架构的 GP-GPU,主要面向数据中心人工智能 (AI) 和高性能计算 (HPC)市场,预计于 2021 年推出。
虽然,英特尔的14nm之后还有14nm+以及14nm++,但面对AMD的7nm,英特尔公布了制程roadmap,这是真的慌了吗?
其实,制程不是全部,规格再高也怕针对场景优化后的方案,不要小看优化的意义。这里主要谈的是处理器,但也不妨拿游戏界的AMD显卡和NVIDIA显卡举个例子,经常性地,A卡哪怕各种参数都优于N卡,但实际游戏体验还是N卡好,这就是规格配置以外的优化带来的差异。
对于英特尔来说,在10nm,以及7nm出来之前的这段时间,英特尔如何绕开制程上的暂时不足,在制程以外的部分发挥自己的优势所长,针对场景做优化呢?且看下文对于英特尔计算产品线的一点介绍。
产品线概览,面向场景优化的英特尔至强第二代可扩展处理器
第二代至强可扩展处理器,在型号命名上延续了第一代的命名规则,用四位数字来代表它的型号,再加上字母后缀代表可选的型号。数字当中“2”代表的是第二代处理器,比如8180是第一代,8280是第二代,而第一位数字代表了功能和性能的分级,数字越大等级越高,命名上从低到高分别为铜、银、金、铂金,对应5、6系列和8、9系列。

铜牌3200系列是入门级的产品,提供最基本的功能,当然包括一些这一代特有的功能,比如安全的硬件防范特性以及加速功能,这些功能在铜牌级产品当中都是有的,它提供最基本的性能,可以供入门级的应用来使用。
银牌4200系列除了具有3200系列的基本功能之外,还增加了睿频以及超线程技术,在核心数和能耗管理上也做了很多优化,总之,4200可以提供非常好的性价比。
金牌5200系列相对4200又增加了更多新的功能,包括对英特尔傲腾数据中心级持久化内存的支持,以及对4路服务器的支持。
6200也是金牌系列,6200相对5200更进一步实现处理器之间的互连,提供比5200更高的带宽和端口速度,也可以支持更加先进的可靠性、可用性、可维护性。
8200开始进入铂金系列,这一代进一步实现4路以上的连接,直接用CPU就可以搭建一个多达8路的服务器平台。
铂金9200系列是旗舰王牌了,单颗芯片拥有高达到56个物理内核,12条内存通道,相当于两块8200的处理器。在技术上就是把两个CPU通过最新封装技术封装在一个芯片上,核数、内存通道数x2。胶水核的说法很多人都听说过,但是把8200系列这样的核封装在一起,对于封装技术的要求还是挺高的,需要考虑空间需求、散热需求、可靠性需求、制造需求等多方面。
9200的应用场景包括高性能计算、数据分析和人工智能以及高密度的基础设施,计算密度新高度。
第一代至强可扩展处理器就优化了人工智能深度学习的训练(training)和推理(Inference)能力。第二代至强可扩展处理器里加入了深度学习加速技术(DeepLearning Boost),在英特尔AVX-512指令集中扩展了新的VNNI矢量神经网络指令,强化了深度学习的推理能力,它的意义在于,比如过去卷积神经需要三条指令,而现在的话就需要一条指令就可以了,加速技术在处理图像识别,语音识别以及对象检测等场景下会有明显加速效果。
从技术角度来看,大多数情况下GPU更适合训练阶段,英特尔强化的推理能力更适用于人工智能的应用侧,CPU的推理能力能更多地出现在城市交通、安全管理、零售或者是金融业的应用场景中。
硬件指令层的优化以外,为了帮助用户基于这一平台做开发,英特尔与业界合作伙伴对这些功能所需要的计算框架、软件都做了优化,使得用户可以很方便的使用这些工具包来开发应用。

很多人提到人工智能其实首先想到的都是GPU以及一些加速器,其实英特尔处理器在人工智能方面的优化进步也很明显。
以常见的Caffe Resnet-50模型为例来看性能变化,如果把2017年7月份之前处理器性能表现看成基础1,第一代至强可扩展处理器8100系列相比前者提升了5.7倍,第二代至强可扩展处理器8200系列已经可以提高到14倍,如果要算上9200的话,则提升了30倍。英特尔在人工智能场景方面的优化就是为了证明CPU也可以很好的支持人工智能。

产品家族中带N字母的型号是针对NFV做优化的。
2011年开始出现NFV的概念,网络功能可以通过虚拟化跑在CPU这样的通用计算平台上,这种想法很快过了概念验证阶段并进入商业落地阶段,英特尔也捕捉到了这一转型下的需求,在第二代至强可扩展处理器产品家族中,专门推出了针对NFV业务特点的型号,产品型号中带字母N的就代表对NFV做了优化,英特尔方面表示使用NFV优化的处理器搭建平台可以提供更高的VM/VNF容量和密度,也就意味着同样的设备上处理更多的用户容量和服务。

产品家族中,带字母Y的型号都支持Speed Select技术。
Speed Select技术是一种对芯片内部能耗进行控制的技术,该技术能对一个封装里的不同内核进行优化,一部分主频更高一部分运行的状态较低,还可以关闭部分核心把一部分核运行在高频状态下,该技术可以让用户灵活做配置。这样的处理器其实可以算多合一的处理器,一个型号可以设多个不同频率,当业务需求变化时候,用户可以不用更换CPU就可以调整配置。
带字母V产品系列的处理器表示对虚拟化环境做了优化,支持创建更多虚拟机,提高单个物理机上虚拟机的密度值。
带字母S的系列针对的场景更为细致,是对搜索算法和业务特点做了优化,提供了搜索优化,与普通型号相比,该型号有更高的主频,使得搜索性能更高。

带字母T的型号对于边缘场景做了优化,这种场景下的设备通常需要在恶劣的环境下运行,比如说要承受更高的温度,比如需要更高的可靠性来运行更长时间。

除了至强可扩展处理器之外,最新发布的还有最高八核的D-1600处理器,它是D-1500的后继者,它不仅是处理器,也集成了芯片组、外设网络、加速功能,与上代相比在计算能力,网络包专发能力均有所增强,是一款转为网络边缘解决方案设计的高密度、高集成度的SoC。

与处理器家族一起发布的还有一款FPGA产品——Agilex FPGA,英特尔的这款FPGA跟此前的很多FPGA有许多不同,首先FPGA内核是基于10纳米制程,Agilex FPGA同时支持英特尔最新的黑科技——Compute Express link缓存一致性加速,当FPGA加速器和CPU连接之后,能与CPU处于同一个内存空间当中,CPU可以访问FPGA的内存,反之亦然,再也不用像以前一样走PCIe了,这是一种新的异构计算形式。
另外,Agilex FPGA还采用了英特尔最新的3D封装,一个封装里除了有FPGA内核之外,还可以有收发器、内存等,这些零部件可以在二维平面上布置,也可以在3D平面上堆叠,所有这些采用不同工艺的硅片可以根据需要灵活集成在一起。
英特尔还在Agilex FPGA中加入了eASIC,所谓eASIC是介于传统的FPGA和ASIC之间的一种技术,与FPGA相比,它的硅片面积和功耗可以大幅度减小,而开发人员面对的那套东西还跟传统的FPGA一样,还是用英特尔的Quartus Prime的工具套件。
以上是2019年上半年,英特尔在计算领域的主要产品方案。
结语
虽说规格配置很重要,但面对场景的优化也非常重要,7nm确实有很大优势,让AMD有了很大的施展空间,但AMD确实还需要投入非常大的精力才能发挥这一优势。AMD的7nm数据中心处理器承担着AMD重回数据中心市场的重任,不过,面对深耕数据中心市场多年,一手打造x86生态,并拿出6大技术战略支柱的英特尔,AMD要做的事情还是挺多的。

