
一.NVMe 协议
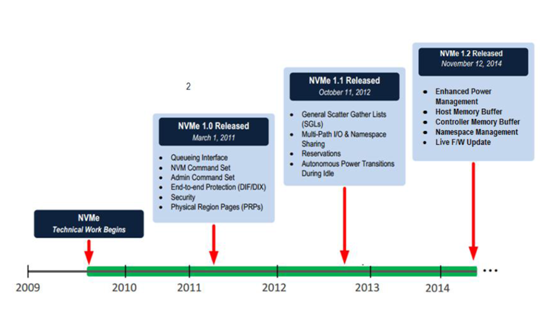
NVMe协议是在PCIe SSD开始大量出现在市场上后,因为各个厂家的私有协议不具有兼容性,无法和现有操作系统无缝衔接,INTEL为了统一接口协议建立生态,而在2011年发布了NVMe协议。
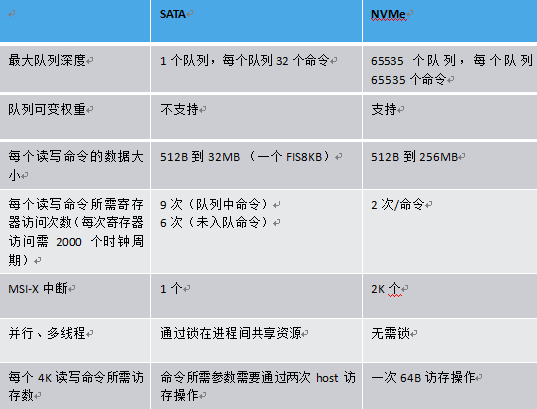
NVMe采用了多命令队列 (最大65536个命令队列),每个命令可变数据长度(512B到2MB),同时数据在host端内存支持Physical Region Page和Scatter Gather List。NVMe协议支持命令间的乱序执行,也支持命令内数据块的乱序传输,同时支持命令队列间的可变权重处理。
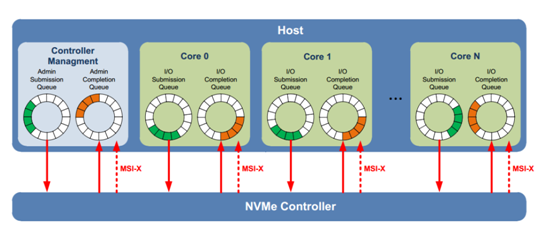
和基于传统ATA(基于PC时代硬盘的接口协议)的SATA协议相比,NVME协议做了很多针对多核host以及NAND存储介质的协议优化。
因为PCIE接口的高带宽,NVMe协议带来SSD访问的高效率,但也同时带来了SSD控制器端NMVe协议栈实现的难度和挑战。这个挑战主要是1)多权重命令队列的管理和命令抓取,2)命令的解析分解,分发,3)数据的传输。
在开始讨论解决方法之前,我们先了解一下SSD控制器的基本架构。
二.SSD控制器
典型的SSD控制器架构如下:
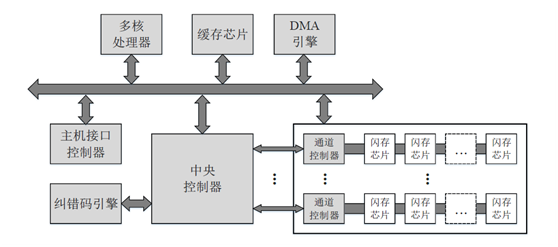
主机接口控制器:
主机接口负责进行主机与固态盘之间的通信和数据传输,接受和解析I/O请求,并维护一条或者多条请求队列。目前主流使用的物理接口包括SATA、SAS、PCIe、M.2等。其中,SATA是低成本的硬盘接口,SATA 3.0的理论带宽是600MB/s;SAS向下兼容SATA,能提供更高的传输速率、可靠性和可用性,SAS3.0的理论带宽是1.2GB/s;PCIe是连接外围设备和主机处理器的主要接口,SATA和SAS接口就是通过PCIe接口连接到主机处理器和内存,PCIe SSD既缩短了主机处理器到存储介质的路径和响应延时,又能提供更大的带宽,PCIe 3.0×4和x8的理论带宽分别是4GB/s和8GB/s;M.2是新一代接口标准,分为支持PCIe通道和SATA通道两种,它具有更灵活的物理规范,在传输带宽、容量和轻薄特性等方面优于SATA接口。消费级固态盘主要采用SATA接口和M.2接口,企业级固态盘主要采用SAS接口和PCIe接口。这些物理接口采取的逻辑接口协议一般是AHCI或者NVMe,它们规定了主机与存储设备之间通信和传输数据的方式。AHCI协议主要是针对高延时的SATA接口的机械硬盘而设计的,虽然能够应用于SATA接口的固态盘,但是成为了高性能固态盘的瓶颈;NVMe协议是2011年由英特尔等公司领头,为闪存存储和PCIe接口量身定制的非易失性存储器标准,不仅具有跨平台的兼容性(目前Windows、Linux和VMware等主流平台都已经支持),而且相比于AHCI协议,具有更低的延时、更高的IOPS和更低的功耗。比如,AHCI只能支持一条最大深度为32的命令队列,而NVMe最多支持64000条最大深度为64000的命令队列,能充分利用固态盘内的并行性。因此,NVMe协议能够更好地发挥出固态盘的高性能优势,得到了越来越广泛的应用。
● 多核处理器:
固态盘的管理需要处理诸多复杂的任务,比如主机接口协议、调度算法、FTL算法和缓存算法等,因此需要强有力的多核处理器来提高这些任务的处理效率,从而降低软件延时。比如,可以使用一个计算核心处理主机接口协议,而使用多个计算核心处理繁重的FTL算法。
● 缓存芯片:
固态盘内置有缓存芯片,一般是DRAM,用于缓存用户数据和软件算法的元数据。缓存既能加快数据访问的速度,提高固态盘的性能,也能够减少对闪存的写入,延长固态盘的寿命。缓存用户数据的部分称之为数据缓存,缓存地址映射表的部分称之为映射缓存。为了防止突然掉电导致RAM中的数据丢失,固态盘一般会内置备用电容,并采用适当的数据保护技术,用于保证在突然掉电的情况下,将RAM中关键的脏数据刷回闪存。
● 中央控制器:
中央控制器是整个固态盘控制器的核心,负责配置固态盘的工作模式,管理各个模块之间的通信和数据流。中央控制器内置有小容量的高速SRAM缓存,用于临时缓存数据。
● 纠错码引擎:
纠错码引擎对要写入闪存的数据进行编码,所增加的纠错码冗余会被写到闪存页的额外存储区中;当需要从闪存中读取数据时,纠错码引擎会对数据和它的纠错码冗余进行解码。如果发生的比特错误数在纠错能力范围内,数据中的错误就会被纠正,从而得到正确的数据;否则,如果没有其它的数据恢复手段,存储的数据就会丢失。编码和解码位于访问闪存的关键路径上,因此纠错码引擎通常采用专用的硬件实现,以提高编码和解码的效率。为了降低硬件开销和解码延时,纠错码引擎会将数据划分为固定大小(一般是1KB、2KB或者4KB)的片段,作为编码和解码的单位。一个数据段和它的纠错码冗余称之为一个码字,数据片段的长度与码字长度的比值称之为纠错码的码率。码率越低,纠错码的纠错能力越强,但是开销也越大,比如冗余的存储开销和解码延时都会变大。为了增加编解码的并行性,纠错码引擎一般包含多个编码器和解码器。固态盘常用的纠错码算法包括BCH码和LDPC码,后者因为纠错能力更强而成为了优先的选择。
● 通道控制器:
为了提高性能,固态盘将数量众多的闪存芯片安置在多个通道上,每个通道上的多个芯片共享一条I/O总线。每个通道包含一个独立的通道控制器,主要负责与中央控制器和本通道上的闪存芯片进行通信,并维护多条操作闪存的命令队列(比如为每个芯片维护一条单独的队列,外加一条总的高优先级队列),将命令发往目标芯片进行执行。所以,固态盘内部具有四个层次的并行结构:通道,芯片,晶圆,分组。高效地利用并行性是保证固态盘高性能的关键。
● 闪存芯片:
闪存芯片上既存储用户数据,也存储需要持久化的元数据,比如地址映射表。固态盘提供的物理存储容量会比用户可见的容量要多(一般多7% ~ 28%),多余部分称之为过量供应(Over-provisioning, OP)空间,主要用于提高软件算法(比如垃圾回收操作)的效率和补偿因闪存坏块产生的容量损失。有的固态盘还会在闪存芯片之间组建RAID5,以加强存储的可靠性。
● DMA引擎:
DMA引擎负责控制在两个RAM之间进行快速的数据传输,比如在中央控制器的SRAM和缓存芯片之间。
不同的固态盘可能在模块设计上会有所不同,比如在每个通道控制器内配置一对纠错码的编码器和解码器,而不是配置一个集中的纠错码引擎;也可能会包含更多的模块,比如电源管理模块、RAID引擎、数据压缩引擎和加密引擎等等。但是,以上模块的介绍能够说明固态盘内部的主要架构。
三. 本文主要针对NVMe主机接口控制器的实现
一般来说NMVe主机接口控制器包括以下几个部分:
Admin命令和completion队列处理模块,IO命令队列处理模块,IO completion队列处理模块,IO写数据处理模块,IO读数据处理模块,中断处理模块。
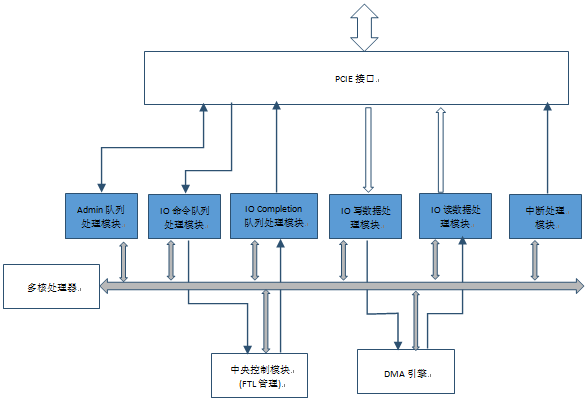
回到NVMe协议栈面临的挑战:1)多权重命令队列的管理和命令抓取,2)命令的解析,分解,分发,3)数据的传输。
命令队列的管理
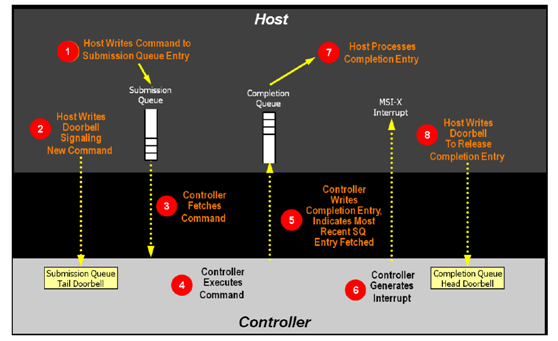
NVMe协议的命令队列分成两种,admin命令队列和IO命令队列。
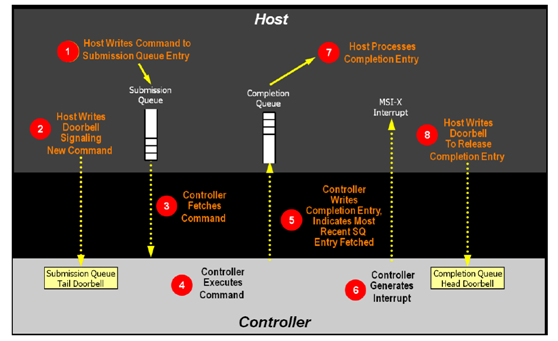
Admin命令队列负责协议的初始化和管理,不负责用户数据传输,对带宽和响应速度没有要求,一般可以用负责前端协议处理的CPU固件来处理,即固件来处理admin命令队列的doorbell,从hostmemory抓取命令,并解析命令;根据命令字段,返回或抓取admin命令的数据段;然后发回completion队列的completion字段。
IO命令队列用于数据传输,而且支持多达65536个命令队列(一般根据hostcore的情况命令队列从16-256不等),数据传输对命令队列的处理要求比较高,SSD控制器的接口控制器需要高效处理命令在各个不同权重的命令队列的抓取、解析和分发。对主机接口控制器的设计挑战比较大。对IO命令队列一般有三种设计思路:1)硬件逻辑处理;2)多核CPU并行固件处理;3)硬件逻辑+CPU固件处理
我们可以比较一下三种思路的优缺点
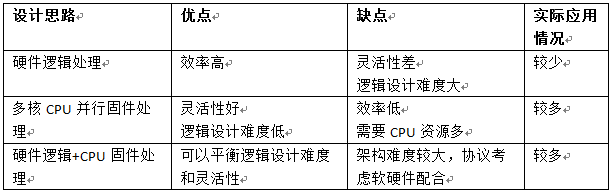
因为NVMe协议的复杂性,不建议采用纯硬件逻辑处理。思路2)和思路3)比较有可行性。
命令队列的管理要解决几个难度较大问题,1)是多权重队列的轮询次序和优先级问题 2)命令字段的解析分解。3)IO读写命令 PRP list处理 4)IO读写命令Scatter Gather list处理。
1)是多权重队列的轮询次序和优先级问题
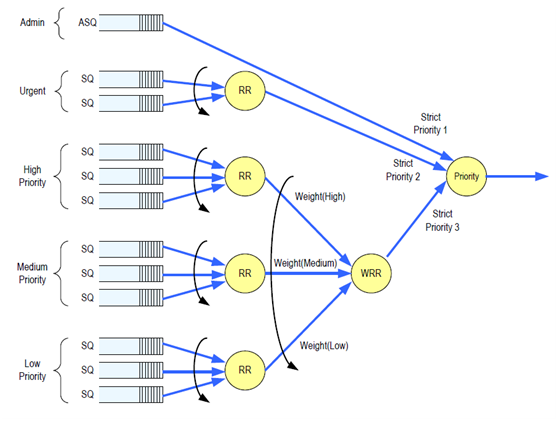
IO命令队列的轮询和命令的抓取需要doorbell寄存器的持续轮询,命令抓取也需要频繁启动PCIE IP,不太适合CPU固件完成,会严重影响命令的处理效率,每个命令字段固定为64B,建议由硬件逻辑处理,但要处理不同权重的命令轮询,需要非常复杂的硬件逻辑,对设计难度考验极大。
2)命令字段的解析分解
NVMe IO 命令的字段如下。
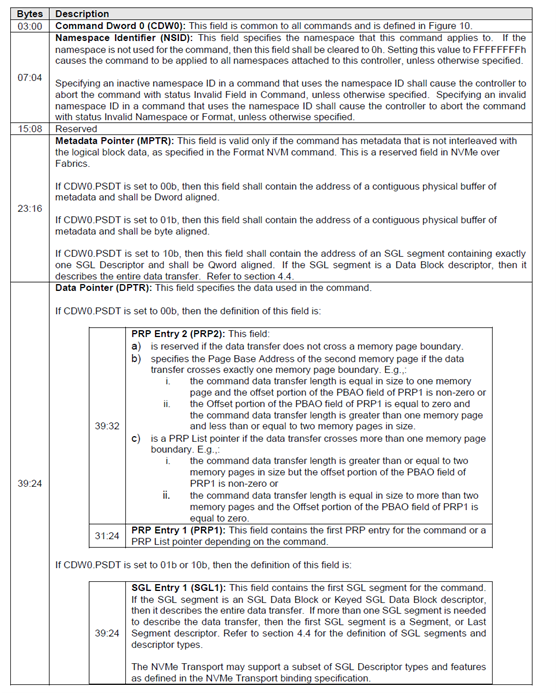

每个IO命令都由64B组成,DWORD0-9字段有固定定义,其他字段根据不同IO命令,有不同意义。而且随着协议发展,还可能一些新的命令和参数会引入。所以对协议的解析需要CPU固件来完成,这样可以增加灵活性。
IO命令对应的数据块在主机侧内存中的存放方式有两种:PRP list 和SGL
PRP list如下图
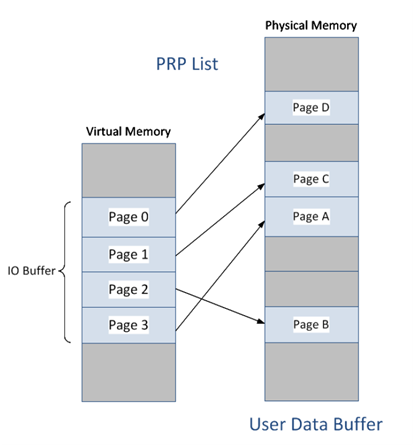
Physical Region Page
SGL 如下图:
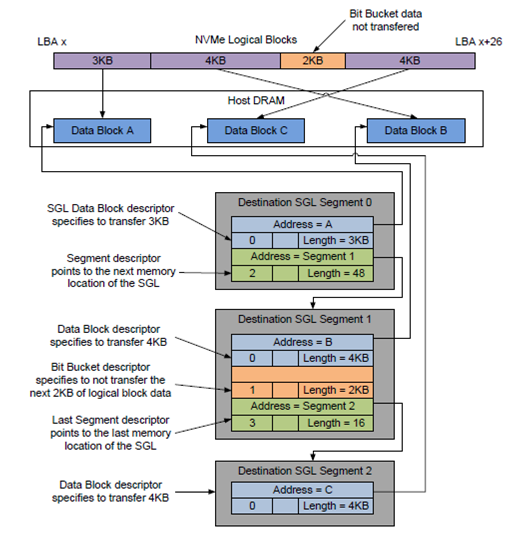
Scatter Gather List
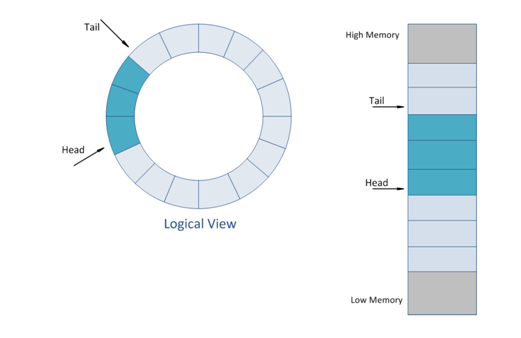
数据在主机侧的内存中,一般以4KB为单位颗粒存放,但颗粒之间物理地址并不连续,而且起始颗粒的offset并不是4KB对齐的。如下图
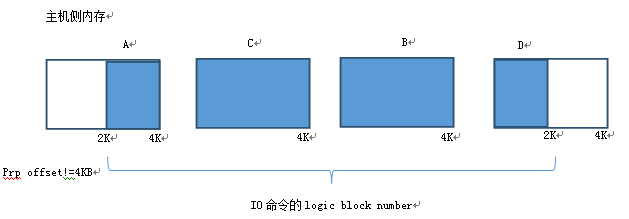
主机控制器在启动PCIE DMA访问主机内存时要注意4K不对齐带来的细节问题,起始块的非4K对其和块大小,结尾块的块大小,这些块需要非4K的PCIE DMA传输。在处理主机内存访问时,CPU固件处理能带来足够的灵活性,但考虑到主机数据传输带宽性能的高要求,需要硬件做协助或者由硬件处理。比如在PCIE DMA加入PIPE-LINE机制,充分利用PCIE带宽。
因为每个IO命令的数据传输大小从512B 到256MB不等,对于SSD中央控制器(FTL管理模块)来说,管理的NAND测数据单元一般是4KB。
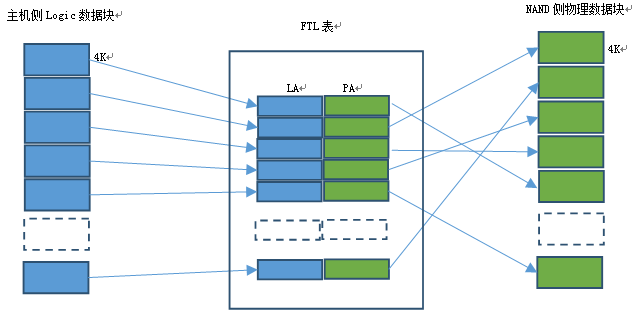
如果主机测IO数据块大于4KB,每个IO数据块的传输都涉及到数据块分解的问题,即需要把主机端数据块分解成FTL管理模块的4KB颗粒单位。从模块化分层设计的角度,数据分割功能不太适合放到FTL管理模块完成,而应该由主机控制模块完成,NVMe协议部分对FTL控制模块是透明的。同样,主机侧协议也应该对FTL管理模块透明。
对于4KB模式LBA,因为数据的offset是4KB对齐的,主机侧数据分解较简单。
对于LBA非4KB模式(512B,1KB,2KB),主机测数据块分解为FTL控制模块需要的4KB单位情况较为复杂,case也比较多。每个IO命令的SLBA(Start Logic Address)不一定是4KB对齐的,Logic Block Number也不一定4KB的倍数。所以数据块分解后的起始第一个块和最后一个块有可能不是完整4KB,主机侧数据分解后的4K块数量要同时考虑Logic Block Number 和SLBA不对齐的情况。例如一个12KB(12KB/4KB=3)的主机侧数据块,分解后在FTL NAND侧可能会分布到4个FTL NAND侧4KB数据块。
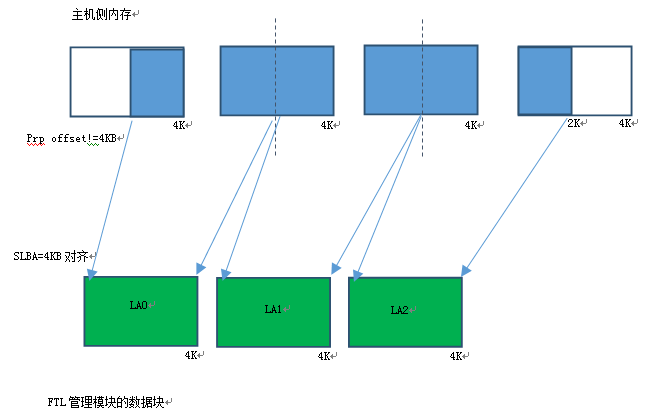
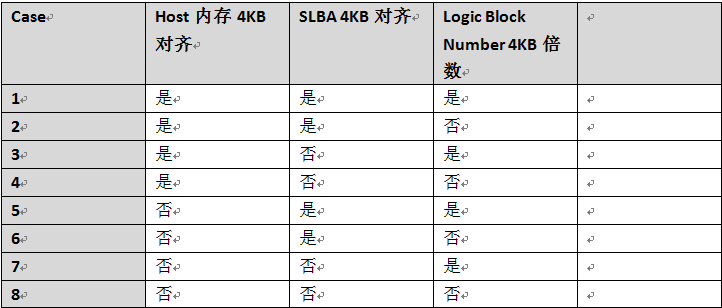
Host内存4KB不对齐,SLBA=4KB对齐,Logic Block Number=4KB整数倍
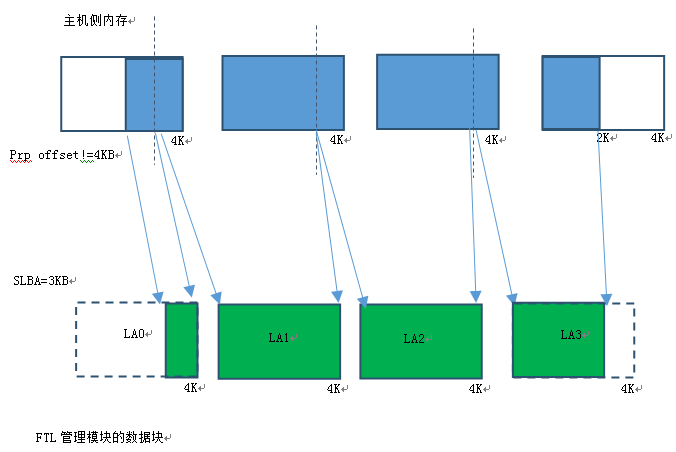
Host内存4KB不对齐,SLBA 4KB不对齐,Logic Block Number=4KB整数倍
从上面两张图可以看出,数据块在主机侧内存是否4KB对齐,SLBA是否4KB对齐,Logic Block Number是否是4KB的倍数,会组成很多复杂的情况。比如:数据块主机侧内存4KB不对齐,那么FTL侧看到的4KB在主机侧内存会分布在两个主机侧内存块里。
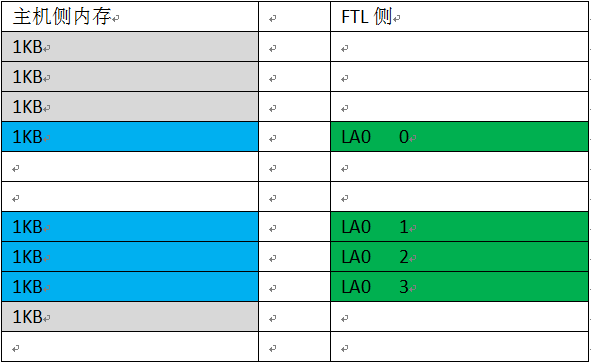
读者有兴趣可以把所有组合整理处来,每种情况数据的分解情况都有不同。
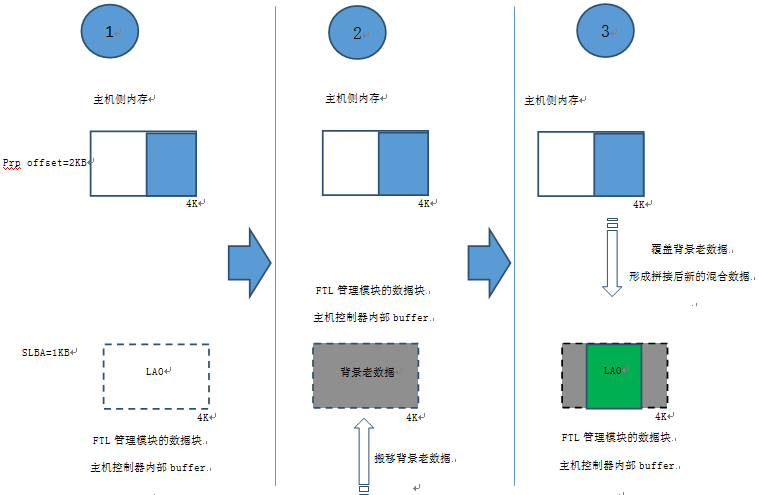
如果分解后的IO数据块小于4KB(如:512B,1KB,1.5KB,2KB… ….),对写IO数据,则涉及到不完整部分数据和FTL 4KB数据块中其他原有背景数据拼接的问题。
NVMe协议是命令控制通路和数据通路分离的,支持多个命令队列,而且支持命令之间的执行和数据传输乱序,命令内分解后的4KB数据块乱序,所以关于命令之间和命令内控制流数据流的控制也是个很好的话题,技术上也有很多难度,就不在这篇文档赘述。下一篇重点谈这个话题。
