
12月9日,以“新存储,新常态,新应用”为主题的中国存储峰会于北京悠唐皇冠假日酒店召开。中国存储峰会是每年一度的亚洲最具规模的存储产业年度大会,历时十二载,记录了存储产业的诸多变化,每年的存储峰会都吸引学术界、产业界和最终用户代表的积极参与。
在存储峰会的“闪存技术应用”分论坛的主题演讲中,迈络思亚太区解决方案营销总监张辉发表了题为《智能网络释放存储无限潜能》的主题演讲。演讲内容围绕如何通过网络把存储的性能释放出来,并把闪存的性能释放得更高展开主题。

迈络思亚太区解决方案营销总监 张辉
张辉表示,早期的矛盾主要集中在毫秒级别的磁盘介质延迟,而网络延迟和软件堆栈(200+微秒)基本都处于微秒级别。然而,现在的介质延迟基本已经被控制在微秒级别。这时候你会发现你的瓶颈主要矛盾已经不是介质,而是网络本 身和软件堆栈。
以下为张辉的演讲实录整理:
今天我要讲的内容是网络如何把存储的性能释放出来,并把闪存的性能释放得更高。
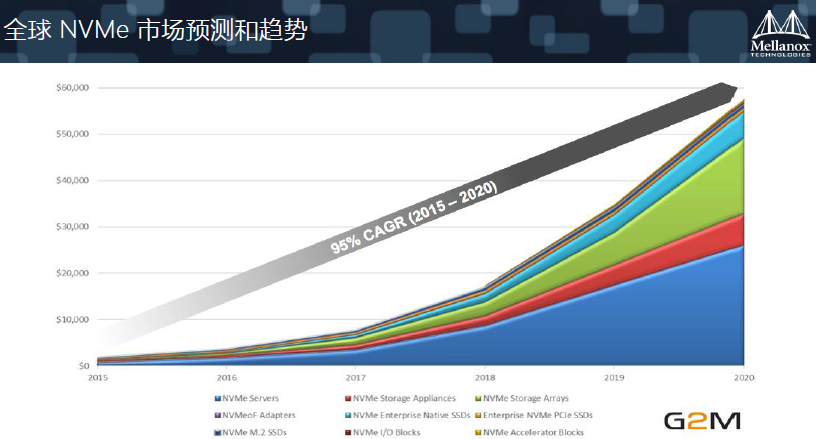
我们现在可以看到,闪存发展越来越快,整个生态系统也会增长越来越快,几乎接近100%的增长速度。当然,NVMe相关的增长也更快,在2020年的时候,有70%的Server会用到NVMe。存储方面,几乎70、80%会用到NVMe。也就说,用不到NVMe的场景会很少。
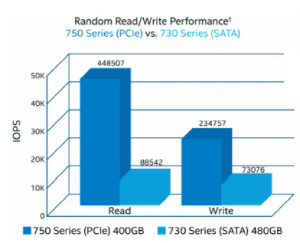
最早的SAS、SATA、PCI的NVMe。这条做技术什么感觉?传统的磁盘,走SCSi协议一路下来是没有问题的,但是介质和技术在发展的时候,协议(软件层)没有更大的进步,这时候会出现效率降低。这里面有一个对比,一个是SAS,一个是SATA,基于SATA走PCIe的性能会出现几倍的差距,因为NVMe把整个协议层做了重新的编写,跳过了一些比较繁锁的过程。
 存储是随着介质的变化,科技的发展,当然最重要的也是来自于客户需求的变化,迫使我们做更好。为此,我们有两个层面的应对方法。一个容量更大,另外一个是速度更快。单介质目前发展的比较快,包括未来会有3D XPoint,而我个人比较坚信未来Flash会发展的越来越快,越来越好。
存储是随着介质的变化,科技的发展,当然最重要的也是来自于客户需求的变化,迫使我们做更好。为此,我们有两个层面的应对方法。一个容量更大,另外一个是速度更快。单介质目前发展的比较快,包括未来会有3D XPoint,而我个人比较坚信未来Flash会发展的越来越快,越来越好。
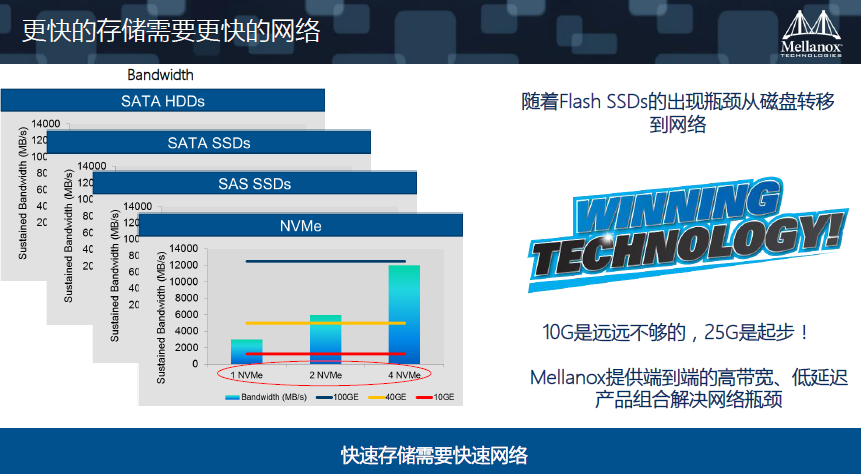
这个问题暴露出来这个单节点性能越来越好,那么他们之间如何通信?我举两个例子,比如北京的交通。我相信无论是北京还是三、四线城市都会拥堵,拓宽街道其实难以解决这个问题。那么怎么解决这个问题?不可能不买车,就像不可能不去运用我们这些数据,如何疏导也是一个问题。因此我刚才提到了带宽,再一个就是协议层的调整。在网络上相对比较简单,我们看一下Mellanox是怎么做的。在NVMe出现以后你会发现,万兆根本无法支撑,百G的情况下也只能跑3-4个。所以说,25G刚刚起步,一个25G刚刚够支撑一个NVMe。
刚才我们谈了介质,现在我想谈“超融合”。超融合是典型的分布式,节点之间的通信流量会很大。因此这个技术对都网络的要求会越来越高,对延时和带宽也都有很高的要求。
再回到技术看一下,我们要优先解决网络中的主要问题。早期的矛盾主要集中在毫秒级别的磁盘介质延迟,而网络延迟和软件堆栈(200+微秒)基本都处于微秒级别。然而,现在的介质延迟基本已经被控制在微秒级别。这时候你会发现你的瓶颈主要矛盾已经不是介质,而是网络本身和软件堆栈。目前Mellanox已经可以把软件堆栈控制在几百个纳秒。可以说,目前TCP/IP方法论已经影响了整个系统的性能。
RDMA是什么?它就是远程直接访问,绕过软件堆栈,绕过CPU,不需要CPU干预,因为内核会产生中断,出现等待时间。而RDMA是远程直接访问的,CPU卸载后,效率会提升好多倍,200多个微秒的软件堆栈延迟就可以忽略了。
今年会有一个新的标准RoCE(RDMA over Converged Ethernet),是跑在以太网上的RDMA。性能比跑在InfiniBand上略低,但是相对之前行能也会有很多倍的提升,而且成本更低。今年6月份会有新的RoCE标准提出来,其中一个是RoCE会支持NVMe over Fabric。我们的新产品会支持200G。
在分布式存储中,为了保证数据的安全性,会进行备份,但是利润率会变低,需要纠删码提高利用率。纠删码需要做重新计算,需要CPU资源,占用率有时会非常高。在我们的产品上,会把纠删码交给闪存卡来做,不需要占用CPU。
NVME Over Fabrics这个很好,未来空间也很大。但是在传统设计里,它也需要消耗CPU资源。因此我们希望CPU只是用来做计算的,如网络计算,NVME Over Fabrics这些工作量,都可以交给闪存卡来做。
刚才讲到一些产品和技术趋势,现在我想介绍一下我们的产品。
今天我希望大家记住一个新单位,就是纳秒。我们这款机器的延迟维持300纳秒左右,和市场上的几个微妙的以太网产品差10倍以上,这是低延迟。带宽方面,目前是100G,明年我们还会有200G的产品推出。另外,丢包也是影响存储效率的比较重要的问题,Mellanox目前可以做到0丢包。当然还有功耗问题,我们也提供了很低的功耗。
现在我想谈一下闪存卡的问题。我发现有很多的技术在里面。首先是带宽的问题, 100G带宽,延迟0.7微秒,即700纳秒,其中我们的卡的延迟只有200纳秒,剩余延迟由软件堆栈产生。从ConnectX 4开始,我们可以支持NVMe Over Fabrics。到了ConnectX 5这一代,开始支持NVMe的卸载,会释放CPU的资源,让你的CPU专门做复制、快照、重删、容灾等,从而实现低延迟,高效率。同时,ConnectX 5里还集成了E switch,基于这个卡可以创建出一个小的存储系统。
到了BlueField的阶段,它集成了ConnectX 5所有的功能,100G芯片,前后端的端口,支持PCIe Gen3、PCIe Gen4,同时还有一个ARM。可以说,有这个芯片,和一个主板,就可以设计你的整个系统了。BlueField可以帮助企业建立全闪存系统,从前端的连接到主机,后端的连接到磁盘,再到计算。
目前我们最新的产品是ConnectX-6,支持PCIe Gen4,适用如高性能计算等应用场景。
下面我想为大家介绍一下落地的东西。第一个华为,在华为这款基于Mellanox的产品中,我们做到了1000万IOPS;第二个是华云网际(FusionStack),单节点做到100万IOPS;下面是Memblaze,同样做到100万 IOPS,带宽是10GB/s最后一个是戴尔EMC的Isilon,也是用的我们的网络。在基于Mellanox的网络里面,都能把存储的性能发挥到极致。大家可以看到,我们所有的产品基本都是单节点百万IPOS起。
我在这里面有一个观点,如果想把性能发挥到极致,那么一定不能让网络成为你的瓶颈。反而要利用网络,降低你的消耗,降低你的性能依赖,让存储系统跑得更快。
谢谢大家。





