

2015中国存储峰会于12月10日在北京成功召开,大话存储作者冬瓜哥发表题为“IO协议栈前沿技术研究动态”的主题演讲,分析了传统IO协议栈的局限以及IO协议栈最前沿的技术趋势。
以下为演讲实录:
谢谢大家,这是我的微信公众号,大家有兴趣可以关注一下,里面有我平时写的一些文章,结尾还有这么一个码,大家来不及,可以结尾再扫。先上一道开胃小菜,大家知道这是什么东西吗?我估计可能没有人见过,我也没有见过。这个东西是一圈一圈的铁丝,说白是铁丝,当然不是一般的铁丝,是经过设计的。
这是半个世纪前的一种存储装置,是怎么存的呢?跟我在这个房间里面讲话有回声,我说出一句话,声波反射到我耳朵里面,我听到,再把这个话再说出去,它又反射回来。我用这种方式,让我要传达的信息,不断在这个媒介上,空气的振动,不断的振动,循环的振动,这个信息就保存在这儿了,除非我断电。这个装置跟这个原理是一样的。你把一个你要存储的信息,编码成也是一种声波,从这个铁丝上传过去,声波在铁丝里面绕绕绕,绕回来以后,你在这儿再把它重新加强,再发出去,不断的循环。这改变所谓的延迟线存储器。一般延迟五微秒左右。
下面我们进入正题。我今天这个话题就是想为大家分享一下IO协议栈里面一些前沿技术和动态。首先搞清楚什么叫协议,什么叫做栈,什么叫IO。IO协议栈是一个操作系统里面一系列软件的模块,让你的应用要读盘的时候,比如读一个U盘,U盘插上以后,点一个复制粘贴,复制粘贴是一个程序,并不是某个菜单,你点的这个菜单,激发了这么一个进程,后面起了一个进程,比如Linux下的做运维的都知道有一个dd的程序,这个程序会调用系统提供的一些代码。当然先得打开,然后做一个准备工作,然后才读写。这些代码都是OS提供的,你只需要调用就可以了。这些代码会被映射到用户空间里面。你把IO下发给这些代码以后,你把这些参数传给他,要读写哪个文件,哪个路径,哪个设备,怎么度,怎么写?把所有的参数告诉它。
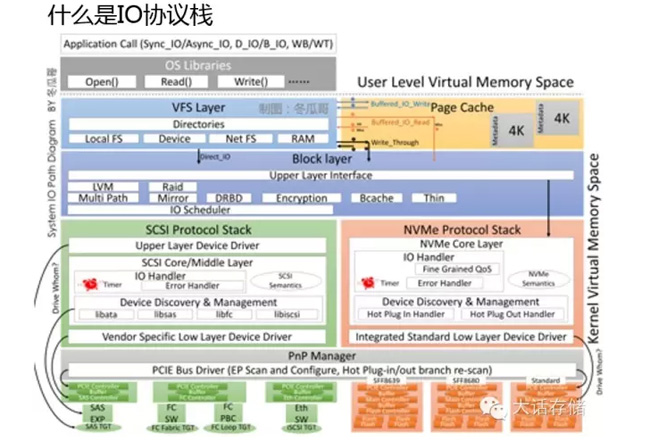
它下一步实现一个操作叫陷入内核,中断到内核里面,这一步操作开始非常大,因为牵涉到权限的转换,开销是很大的。进入内核以后,先到一个VFS的层,这是一大块的代码,这个层就是目录层,比如C:/,Linux下/某个字母,再写一些字母。谁来维护目录和底层的存储的实体的映射关系呢?由VFS层维护,你访问的是一个网络盘的路径,还是一个本地盘的路径,是一个文件,串口,终端,其实都是符号,由VFS把IO下发给底下对应的承载者,底下画了四个承载者。还有跨设备的各种设备,还有网络的系统,还有内存里面的数据结构,比如/PROC,有一些运维的时候用的一些命令,把它从零改成一,触发了某一个逻辑,这都是内存里面的数据结构,也在这个符合下限。
这层再往下,如果访问块设备,直接下到块层,块层是最终对存储设备的集中访问点,在这个层里面,有一些附加功能,比如多路径,加密这种分层,缓存,很多的开源的这些产品,其实都是基本上在块层这个功能上面做二次开发做出来的。块层下面就是一个IO的队列,在这儿做一下IO的优化,合并,存盘这些事情。在这儿会有一个瓶颈,就是IO这个里头的队列是一个瓶颈,上层把IO往这个队列里面放,下层不断把IO拿走。俗话说的SCSI协议栈,包括三层,一个是上层的协议驱动,指磁盘驱动,磁带驱动,如果有其他的设备,比如打印机之类的,SCSI打印机和扫描仪也有,很早的时候,这块就是驱动设备了。SCSI Middle 层就是管SCSI指令,下发下来都是在内存里的数据结构,每个OS都不一样,但是如果发到磁盘,发到外面的交换机,必须把它弄成标准化的,因为外面有很多厂商做硬件,你不标准,就没法做了这个硬件,你不能说为每个OS都做一个硬件。这层除了翻译成SCSI指令,这边有SCSI语义,还有管真正的SCSI的处理,比如超时了怎么办这些事情,这是中间层。
底下这层是HBA层,首先要有驱动,在HBA上有设备发现的这么一层库,因为传统的SCSI几十年前,那时候只有SCSI这么一种物理硬件,大家可能有人见过,很粗很笨的线缆,后来出现了FC,SAS这些,更快速的、高效的物理链路类型。SCSI协议,如果想跑在这些物理链路类型说,就需要有这么一块代码,这个网络里面,把你对端的SCSI设备发现上来,如果后端改成SAS,这块代码就会往SAS网络上发出一些广播的消息,将设备探测到,然后才生成设备符号。
再往下就是硬件,出了协议就是硬件,硬件你先得连到HBA上,SCSI卡、SAS卡、以太网卡、各种卡,通过这个卡,再通过网络,或者连交换机,或者直连,连到最终的设备上。所以,我这儿画了一些箭头,指的是什么呢?每一种硬件,每一个角色都有各自的驱动。最底层的设备,它的驱动在最上面,再往上一层,HBA驱动在这个地方,然后HBA上还有一个PCIE控制器,它是从里向外扩散的一个东西。但是,IO要先发给最上面的驱动,先冲着最底下的设备来,驱动是从上往下这么发出去。这是传统的协议栈。
红色的这块,就是所谓NVMe的协议栈。刚才英特尔也讲过,NVMe跟PCIe有什么区别呢?NVMe它是一个协议栈,是一个协议。跟说话一样,我跟你说话,我们中文这就是比方说SCSI,非常博大精深了,语法,还有成语,非常厚重。NVMe相当于英文,简单直接26个字母。但是,我们都是用嗓子来说话,都是用空气来传播,振动来传播。就是这个道理。SCSI也可以跑在PCIe上,就像SCSI跑在FC上一样,同理NVMe也可以跑到以太网上,也可以跑到FC上,你怎么over都行,over在串口上都行,只要不嫌慢。下面再介绍NVMe这边的协议栈。这个协议栈非常轻量级,像英文一样,表达简单,所以它的速度要快。

我们看看这个传统协议栈到底出了什么问题?为什么这么多人在尝试修改它?主要问题就在于闪存。它没出现之前,没有任何问题,它一出现,全是问题。我们看到底有哪些问题?第一个问题,太长,大家可以看到,我刚才讲的这一堆的东西,其实整个就是IO协议栈。当然,SCSI协议栈是泛式的,一般指下面这块,但是上面这块也应该算。它经历了多少个块?非常多的模块,你每经历一个模块,你这个代码就要在CPU内存之间交换、执行一会儿,还牵涉到来回切换。当然,你拿人的标准来判断,CPU执行的这一条IO可能费不了多长时间,比如微秒、毫秒级。但是,对于SSD,SSD响应非常快,如果上面太慢,你这个性能就发挥不出来。我们常说NVMe SSD性能很高,你是把它放到机箱里面性能很高,但是假设把一块NVMe SSD放到海南去,从北京发一个IO协议到海南,然后它返回,它肯定不会快了。也就是这个IO发出来,到磁盘被收到之间,经历的路径越长,这个时延就越大,经历的模块越多,每个模块处理的事情越多,时延越大。那就是说NVMe离远了,它就不快了。就因为这个时延太高。下面还有另外一个是吞吐量,到时候再说。
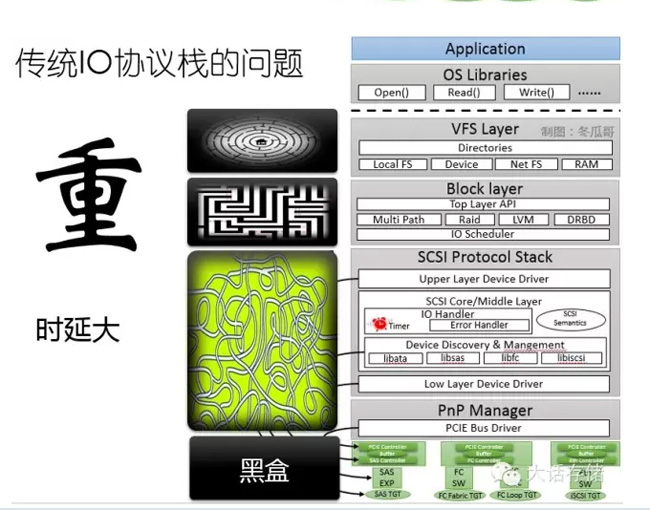
太重,所谓太重,每一层都有自己的处理逻辑在里面,比如下到VFS,要搜一下这个目录到底对应的谁?搜fstab表,要是访问文件系统,还得到文件系统把元数据读出来,也就是读元数据的时候,文件系统就会往磁盘上发IO,读上元数据,找到处理你这个IO必要的信息,然后IO才能下到盘,相当于一个IO触发了N个IO,有可能很慢,很重。Block层有很多协议要处理,SCSI协议栈更厚了,因为SCSI传统的东西,发展到现在几十年了,里面什么东西都往里加,各种库,各种不定都往里塞,塞的整个协议栈很重。再往下就是黑盒,到外面外面的设备怎么实现的,你也不知道,有可能就是一块盘,也可能是被别人虚拟出来的盘,也有可能是分布式的,像刚才讲的那种,也有可能是集中式的,你也不知道。但是,你可以猜到什么?下面的存储设备,其实它内部也是个OS,你的IO到他那儿,他也要经历这层,最后才下到真正的物理盘,可能经历N轮,IO才能下去,所以传统协议栈又长又重。

还有一个窄的问题,就是Block层的队列只有一个。这个队列就是IO不断的往里堆,你有多个应用访问底下的设备,多个应用都是多盒CPU,每个CPU运行一个线程,每运行一个线程都往下发IO,如果正好四个线程都往里发IO,相当于一个单车道,两辆车同时往里塞,就会出现撞车,IO也是一样的。谁要往这里面发IO,要更新写指针,如果这个变量是双字节,或者四字节,你写一个字节,我写一个字节,最后写乱了,就崩溃了,乱套了。所以,你要往里插入IO,必须把这个队列锁住,又把这个变量锁住,先加锁,加锁别人就不能访问了,然后你再往里写。这样顶上看似是并行的,到这儿就变穿行了,再这么搞一个加锁,就开销非常大了,所以导致性能比较差。当然,对于机械硬盘,都不是问题,因为机械硬盘太慢了,这点开销对它来讲,根本就不算开销。这是窄,就一个队列。
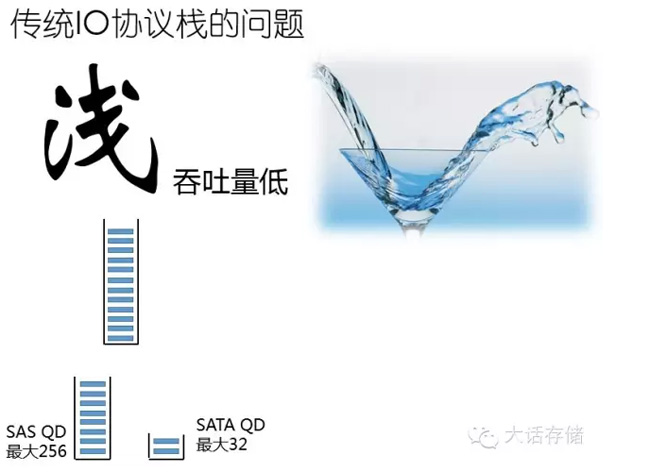
我们再看看浅。这个队列不但就一个队列,还窄,而且还浅,里面容纳不了多少IO,SATA最大32,SAS盘最大256,上去还有HBA卡的队列,驱动里面的队列,Block里的队列,这些队列都是照着这个盘设计的,比如256个盘,256×32,最大照着那个来,但是实际比这个还要少。浅会造成什么问题?如果底下很慢,浅没有问题,因为一时半会儿消耗不完这也IO。但是,如果很快,会发现一会儿这个队列就空了,一会儿IO还没有下来,又空了,整个这个跟开车一样,油给不上,就是这个道理,太浅了。

“长+重=厚”。比如传统说的协议栈很厚,就指这个意思,又长又重。厚影响时延,刚才那个例子。什么场景下在乎这个时延呢?比如OLTP,用什么场景呢?就是在线处理。这个场景就相当于你在淘宝里买了东西,点个购买,你恨不得马上我就成功,点个付款,马上成功,你总有人等着你,马上回来。这就是证明有人在等,赶快回来。如果点击购买,发给谁,半天才回来,你肯定不再在网上买东西了,因为三天两头超时你就会很不爽,所以时延很重要。
同步IO是典型的要求时延的场景,你发一遍IO以后,IO结果返回了,才发下一个IO。我IO调用下去以后,阻塞掉了,你不返回,我的代码就没法往下走,又被阻塞掉了。如果是同步IO,这个路又非常长,性能就非常差,但是,如果是异步IO,你流程长,我时延大没有关系,但是吞吐量还是可以上来的。因为我原端不断把IO往下发,IO不断的过去,你不断的接收,总体是有一个时延的,这个就看场景了。OLTP很在乎时延,对吞吐量要求不那么高。
窄和浅就影响吞吐量,因为本来并发的变成串行了,一个一个来,最后吞吐量就上不去,OLAP场景最怕吞吐量低,比如大数据分析,因为没有人等着你马上把结果返回来,你这个任务下发下去,要分析谁谁谁,某处买个什么东西,哪个时间段干什么事,这就是定型的OLAP场景,不是点一个按纽,马上就知道结果的,可以等一分钟,这一分钟以内,你只要保证底层的吞吐量最大,完成的速度就快,它对时延反而没有什么要求。

我们看看传统IO协议栈问题很严重,对于机械盘来讲,是没有问题的,你算算就可以了。协议栈引入比如0.01毫秒的时延,一个IO下去,一直到发给磁盘,出了这台机器,耗了0.01毫秒,别看这么大的带宽执行。机械盘执行这个IO,平均需要10毫秒,这么一比,开销就这么点,根本没有问题。但是,对于它就有问题了。SSD执行平均耗费比如10微秒,基本50%的开销了。所以,这个IO下去一半的时间在路上,一半的时间执行,这个效率非常差。所以,要着手去优化这个协议栈。

NVMe协议栈是怎么优化的呢?就是把长、重、窄、浅取个反义词就完了。长就降低模块的数量,它从块层,把IO Scheduler下面一堆的东西全部格掉了,不再修改,从Block下来。设备发现一堆的库,这个不需要,如果是NVMe Over PCIe,它的设备发现都是PCIe给它做了,他自己不需要做,就变轻了。只有一组指令,很少的指令数量。关键是下面这两个,队列变宽了,之前只有一个队列,相当于只有一个单缸的发动机,如果来一个多缸发动机,动力当然强了,所以变宽。还有变深,每一个队列很深,这个汽缸排量就这么一点,坡都爬不上去,换个大的,一次让它玩命的爆炸,NVMe基本就这么干的。
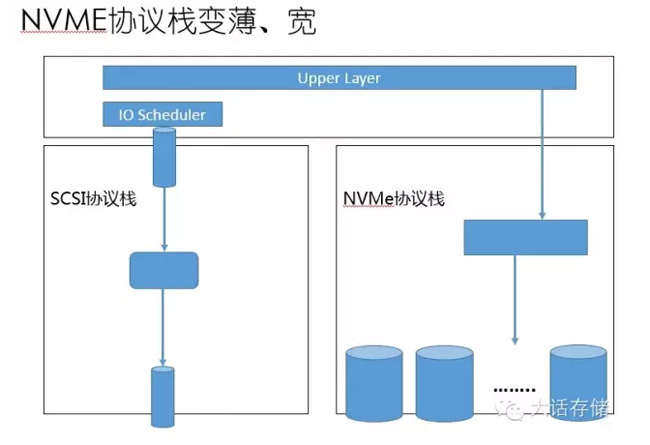
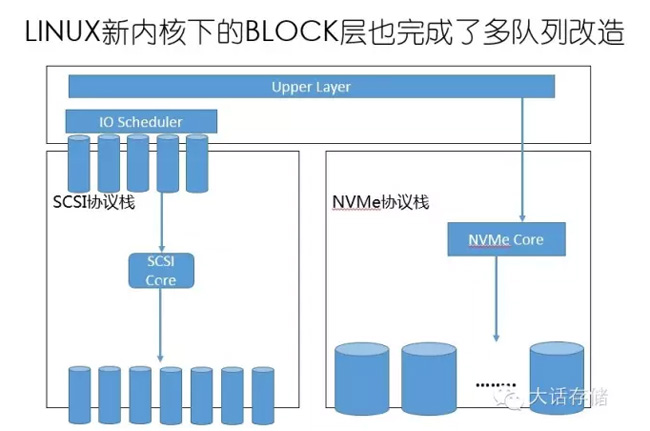
变短、轻、宽、深了以后,基本就是这么一个情况。SCSI协议栈就这么一个队列,硬件队列,硬件队列,块层队列,块层最大支持64K的队列,当然现实产品没有用这么多的,但是将来不一定多,将来谁知道会发展成什么样呢。对传统的SATA SSD、SAS SSD,他们走的是SCSI协议栈及不是NVMe,他们只是SCSI指令,这个怎么优化?他们也是SSD。所以,最新版本内核,做了块层的多队列优化。底层驱动跟着多队列,这样就把它变宽的,当然这是在最新的内核下面才有这个特性。
NVMe1.2版本里面有一个特性叫Controller Memory Buffer。传统的驱动模式是,先把命令准备好,在内核内存里面,然后由驱动去通知这个设备,我这儿有条命令,设备要自己到内存里面,把这个命令取回来,设备要自己来取,你看这里面,很麻烦,我不是把说命令直接扔给你了,你自己来取,我告诉你这条命令。那么,为什么这么设计呢?我也不清楚。但是,现在有了这个SSD以后,有了这条命令以后,直接把这个命令写到设备里的内存了,少了一轮交互,当然NVMe1.2现在还没有能支持,很快了,无非就是软件上,当然硬件上也会有一些改动,当然改动也不是非常大。

驱动方面,早期的IO设备有一种模式,叫做Program IO,PIO,这个PIO是什么意思?很早的时候,比如打印机,把打印命令发出去以后,打印完没有,这个程序要不断的问这个设备,打印完了没有?不断的问,如果全速循环的问,CPU百分之百就耗进去了,所以每次执行都耗干净了,不断发N个指令问这个设备,打印完了没有,这很浪费的,CPU都干这个事了。因为这个打印机很慢。后来才出现中断方式,我这个打印机打印完以后,你命令下给我以后,你该干什么干什么,打印完了,我给你发个中断信号,你把你当前正在执行的程序保存起来,上下文保存起来,然后来处理我这个IO完成命令。这个就非常好了,又不耽误事,CPU又不会耗费这么高。
这个模式一直发展到今天,终于出了问题了。当然也不是问题,只是效率显得低了。为什么?现在不是说SSD慢了,不是说CPU在等SSD完成IO指令了,是IO指令下去以后,SSD等待你CPU来处理这些IO的完成。我下面快了,怎么办?CPU就得回归到传统的模式。下面这么快,我就不断的问,每次问的时候,肯定会有完成的,因为底下太快了。每个io完成之后是在一个完成队列里面等着,告诉上层IO我完成了。
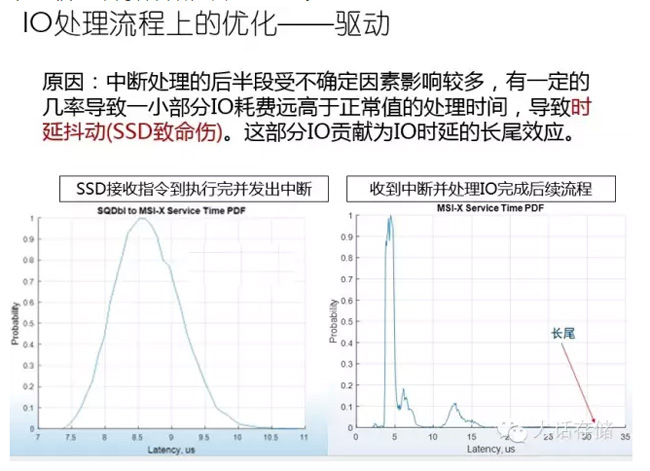
所以,就有人在开发这种叫PMD,polling mode driver。中断模式的驱动其实还有一个致命的伤,对SSD有一个致命伤,就是中断IO完成模式,SSD收到指令完成,这个过程基本在8.5-9微秒之间完成。这是一个叫PDF的分布图,大部分的IO都集中在这个横坐标的时延,集中在这个区域完成。它完成以后要发中断,中断完了,CPU驱动处理。处理的时候,大家可以看到,99%点几都在5毫秒之内就完成了,但是百分之零点几的概率会在30微秒才完成,产生了一个叫长尾效应的这么一个效应。30微秒,一旦IO正好到这儿,30微秒才结束,这体现SSD的性能抖动,延时抖动,这个抖动会造成什么?比如高速路上突然有一个车停在车道上,后面的车就得绕过他,一变道,那个车又减速了,整个就堵在那儿了,就算不停下来,速度慢了点都会出现这个问题。SSD这么高的速度,上面使劲发IO,这么大的吞吐量,突然来这么一下,整个性能反馈上去,就会出现比较严重的后果,可能上层业务就卡在那儿了。这是刚才那个道理,高速路。这也是一个严重的问题,就是中断模式。

所以,有人在研发Poldling额 Mode Driver,说白了就是用驱动不断的Poll这个完成队列,把IO赶紧拿出去,赶紧处理掉。其实代码上也比较简单,就是这三大块poll,然后锁住队列,执行一条IO,解锁。单个队列还得锁,多个队列之间就不用锁了,多个队列之间是毫无关系的。这个付出的代价就是CPU又达到百分之百,因为要不断的polling,不断的循环,你把CPU占满就体现为百分之百。
我们看一下实际的测试效果。先看一下两种方式,一个是在内核里面poll。一个是在用户态poll。这个用户态是比内核态更高效的驱动,因为每次IO下去都要进内核,陷入内核,开销非常大,直接用户态Poll,这个性能更高,但是如果在用户态做个驱动,优势就是性能会有比如10%的提升。但是享受不到操作系统的任何功能。所以你的用户态自己开发的程序,自己做一个。一般人不敢玩这个,玩不好,反而还不如之前的性能。
这是一个人做的测试,基本上三种模式,一个是传统的中断模式,这个是在内核态poll的模式,还有这个用户态poll模式。同样的方式,QD=1的时候,它的性能能到68000IOPS。换成轮询模式性能达到10800。换成用户态poll,需要自己在用户态写一些服务,用它来做,120K,12万,基本是中断模式的两倍了,所以这个效果提升非常明显,但是CPU的耗费也是上来了,基本都是百分之百。时延当然轻了,传统模式12微秒。
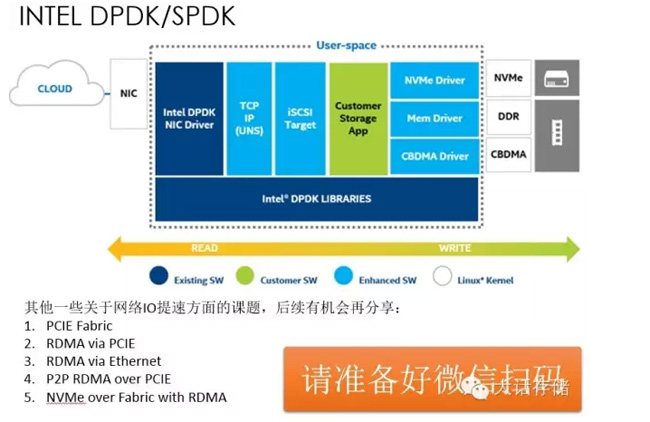
这就是SPDK,它由好几部分组成,如果跑以太网,把DPDK也包进去了,其实都是在用户态运行的,绿色是你自己开发的的,三个蓝色就是用户态的NVMe驱动,包括Mcm Drive。这就是今天分享的东西,当然这块还有很多东西要说,这些后续有机会再和大家分享。谢谢大家!


