
据市场分析公司IDC的研究结果表明,2011年创造的信息数量达到1800EB,每年产生的数字信息量还在以60%的速度高速增长,到2020年,全球每年产生的数字信息将达到35ZB。迅速增长的数据量突显了重复数据删除技术(De-duplication)的重要性,它不仅能够减少了信息在物理存储空间的压力,而且大幅降低了数据传输的网络带宽占用。
在面对大数据时代的今天,重复数据删除技术再次成为热议的话题。首先,原始数据将被打散为数据块,并进行单一实例存储。如何保证数据块与指针正确,不造成数据丢失或误删除,显得非常重要,任何数据块的丢失都意味着很大一部分数据将无法找回。其次,如何保证重复数据删除的性能,过小的数据块使得重删比率会越高,但海量的数据块比对会影响运算性能;数据管理人员需要在两者之间找到合适的平衡点,同样是一场博弈,既要保证重复数据能够大量删除,又要选择能够接受的运算性能。
众志和达(英文SOUL),是中国信息存储、数据安全与应用领域领先的解决方案与服务提供商,拥有超过15年的中国本土市场经验和3000多家最终用户。
SOUL以满足云计算、大数据时代企业客户需求为目标,坚持自主创新,拥有基于自主知识产权的SoC(Storage-on-Chip芯片级存储)技术、SureSave智能化存储与保护管理、分布式存储与计算管理等核心技术,提供海量数据的存储、保护与云计算、大数据等应用解决方案,为现代IT应用提供高速、安全、可靠、弹性的基础架构,将数据与计算的价值充分发挥。
块级变长算法的高缩减比
SOUL开发的重复数据删除技术基于块级、变长模式,采用业界流行的HASH算法,以In-Line方式实现了在存储过程中实现重复数据删除功能。为防止重复数据删除运算降低总体I/O性能,所有重复数据删除运算均采用硬件实现。
基于块级去重的方式:
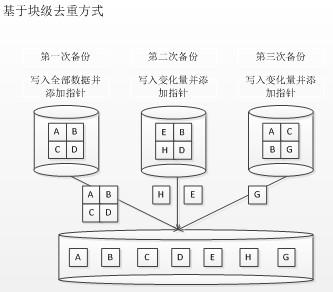
图一:基于块级去重方式
如图一所示,图中第一次备份为全备份,以后每次只备份变化量,并给每个数据块添加相应的指针。从形式上看,块级去重与文件级去重原理基本一致,但文件级去重比对的是不同文件,如果文件内容有变化,则被视为变化量进行保存;而基于数据块去重模式无论文件是否变化,只记录变化数据块,而文件内容变化后,其变化数据块部分被保存。
基于变长去重的方式:
在去重效果上看,块级去重远高于文件级去重,而块级去重则进一步涉及到变长与定长的问题。
定长是指数据块大小是固定的,一般固定值为12K—256K不等,对于定长而言,数据块越小,去重率越高。而变长的数据切割方式通过相应的块的长度,再加上相应的字母顺序,通过一个三维的算法进行切割。
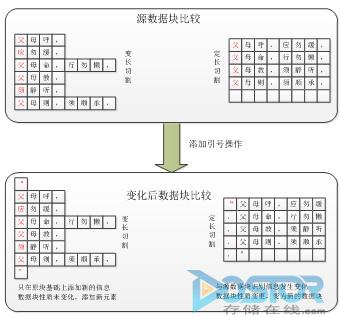
图二:变长切割与定长切割的对比
如图二所示,如果文件进行改变,比如插一个“”在数据块中,变长切割模式就变成4、4、7三行一组,剩下的又按照“父”是有含义的一个字,切割方法没有变。最后扫描下来,只有首末行是变化的,需要备份首末行这一小小的变化量,即完成了变更,而数据量增加的仅仅是引号。
如果是定长则首行没有任何规律可言,完全按照固定大小进行数据切分,当添加引号时引起整个数据块变动,从而生成了新的数据块。从去重效果上看,变长的去重率要高于定长。
多重校验的高可靠性
重复数据删除技术的关键在于可靠性,由于数据存储时候被切块并对每个块进行单一实例存储,那么任何一个数据块丢失,或者指针错误都会造成一大部分数据永久无法找回。对于客户而言,是造成不可估计的损失,因此如何保证重复数据删除的可靠性显得至关重要。
SOUL的重复数据删除技术在每一步hash对比过程中都有CRC校验,保证了每一步对比中数据的正确性;而每一步对比过程都会定时与log进行同步。如果出现不同步现象,则该步骤将清空记录并重新引用log信息,再次执行比对工作;而log则定时与底层数据库同步,保证了数据与hashkey的绝对一致性。为了防止非法关机造成的数据不同步,SOUL在hash对比的第一层设置了启动同步,无论是否非法关机,设备在启动后都会进行自检,并与log进行同步,进一步确保了数据准确性。
沙漏式对比机制的高效率
重复数据删除技术始终是在去重比例与性能之间找平衡,去重比例越高则必然性能衰减越大,其原因在于数据块在切块时候块越小,出现重复数据块的几率会越高;而块越小则意味着相同大小的数据被切割后,产生的数据块的数量越大,而数据块数量越大在hashkey对比过程中耗时越长,使得性能衰减越大。因此即便采用等同的变长法则切块后,hash对比过程也同样决定着性能损耗的程度。
SOUL的重复数据删除技术在hash对比过程中采用了沙漏式的对比机制,该机制会在缓存中逐级筛选重复数据。最上层机制做最简单的粗略判定,丢掉绝大部分重复数据,将可能不重复的数据传递到第二层级;第二层做相对对比,判定hash是否已经包含于某个hash段组中,此时已经有99%的数据进行了dedupe,而剩下的1%的数据将传递到第三层;第三层将前面没有判定结果的hash与系统全部被使用过的hash进行对比,此处才开始真正对比hash,也就是是细节对比,第三层将过滤掉剩下数据中的99.99999%,最后剩下仍然无法判定的则会在hash库中逐一查找进行对比。
虽然对比过程变成了4步,但去重效率却大幅提升。通过实际去重测试,在打开重复数据删除之后,磁盘I/O是未开启重复数据删除的1.06%。磁盘I/O决定了一个系统的性能,更低的I/O不仅有效提高去重效率,也提升了磁盘的使用寿命。在采用多重对比后,其数据缩减比也大幅提升,实际测试数据缩减比可以超过30:1。
能够将磁盘I/O降低到以上程度主要是因为每一步运算是在内存中进行,并且都采用预读取机制,而每一步都将只判定自己可以判定的hash,任何无法判定的hash都交给后面处理,这样每一层数据筛选的效率将大幅提升,从而提升整体效率。
综上而言,SOUL采用多种优化机制,解决了高去重比例下性能衰减的问题,实测在系统性能衰减不足5%的情况下实现了超过30:1的数据缩减比。同时高效、多重的校验机制也彻底打消客户对重复数据删除可靠性的担心。
SOUL为大数据时代打造了安全可靠、高效灵活的数据管理与计算解决方案,以智能化、可拓展的开放式系统设计,辅助用户实现从传统IT应用向云计算、大数据应用的平滑迁移,从而更加快速开展数据资产的分析、挖掘、管理,并从中获取商业机会与竞争优势。

