
重复数据删除技术的核心理念就是:在存储数据时检查和比较已存在的数据,如果它们是相同的,那么就过滤掉这部分数据的备份,然后通过指针引用已存在的数据。重复数据删除目前是存储领域一个比较热门的研究课题,因为它能给整个存储系统甚至是整个企业带来很多明显的好处。显然,重复数据删除可以从根本上减少存储占用的空间和用户的磁盘驱动器数量,减轻人力、能源、电力资源等方面的开销,从而大幅度的节约存储成本。另外,重复数据删除可以减少在网络中传输的数据量,进而降低能量消耗和网络成本,并为数据复制大量节省网络带宽。
工业界产品往往注重强调处理重复数据删除的时间,这样的划分可以将处理时机分为两类:同步处理和异步处理,也成为在线处理和离线处理。
所谓同步方式,就是当大量的备份数据流到达具备重复数据删除功能的备份设备时,首先驻留在内存里,然后重复数据删除引擎对先到的备份数据进行辨识,判断是否存在已被保存过的数据块。如果有,则写入一个指针来代替实际数据块的写入过程;如果没有,则直接写入该新数据块,从而完成数据备份过程。而异步方式则不同。它是当备份服务器开始向备份设备传输备份数据流时,将整个备份数据量作为一个整体来传送,然后再启动单独的进程开始读取已写入磁盘的数据块,从这开始重复数据删除处理过程。如果读入的数据块和已存储的数据块重复,则用指针替代该数据块,如果没有重复,则将该新数据块留在磁盘上。也就是说,前者是在数据备份的同时对其实施操作,后者是在数据被写入磁盘后才开始实施操作。如此一来,两种方式在整个数据备份过程中所花的时间就有所差异。
虽然同步处理可以缩短数据备份的时间,但对CPU 及网络资源的占用非常大,所以,用户在实际的应用中必须仔细地进行调优处理,保证重复数据删除速度足够快,从而不至于造成进入备份设备的数据流拥塞。另外,同步重复数据删除方式对于实施重复数据删除的硬件平台性能要求很高,对于数据一致性和整体系统的扩展性也存在较高的要求。
与工业界不同,学术界在提到重复数据删除时,更多的是去关注检测重复数据的方法。粗略的划分,可以将检测方法分为两类:基于相同数据的检测和基于相似数据的检测,也可以称为精确去重和近似去重。
基于相同数据的检测是指将存储系统中的数据按照文件级别或者数据块级别划分后,利用文件或者数据块的hash值来查找新来的数据与已存储数据完全相同的文件或者数据块。而基于相似数据检测是指利用数据自身的相似性特点,通过相似性查找技术,挖掘出与新来数据相似的已存储数据。在选定了相似得已存储数据后,再进行精确地重复比较,进而减少存储空间占用。
虽然重复数据删除技术能够缩小存储占用空间,减少网络传输带宽,节省能源,但这项技术能够应用的前提是对原有系统的性能,可靠性等方面不会造成过大的影响。所以除了关注能够如何检测到重复数据之外,还需要关注对系统性能和可靠性方面的影响以及改进技术。另外值得一提的是,重复数据删除与编码技术相结合,可以最小化压缩相似数据,进一步所见存储空间和网络带宽的占用。
1. 基于相同数据的检测
1.1 文件级别相同
文件级别的基于相同数据检测重复是在文件粒度级别查找重复数据的方法。存储系统中,通常是以文件作为一个信息集合的单位,所以重复数据删除技术出现的初期想到基于文件比较重复数据。对于已经存储在存储系统中的文件,会先计算出它们各自的hash 函数值(通常用MD5 或SHA-1),并将这些hash 函数值组织成hash 函数值库, 单独存储起来。这里应用重复数据删除功能的前提是: 应用本身会有很多重复的数据,否则由于多存储了文件的hash 函数值,实际是浪费了存储空间。
当有新的准备存储的文件到达存储系统以后,会首先计算这些新文件的hash 函数值。将得到的hash 函数值与已经存储与hash 函数值库中的值进行比较。如果发现两者有相同的hash 函数值,就判定为两个相同的文件,只需要用指向已存储文件的指针代替新的准备存储的文件即可。如果发现新的准备存储的文件hash 函数值不在hash 函数值库中,则可以判定该文件没有在存储系统中,除了将文件存储起来之外,还要更新hash 函数值库,将新的文件hash 函数值添加进去。文件级别的相同数据检测过程如下图所示:
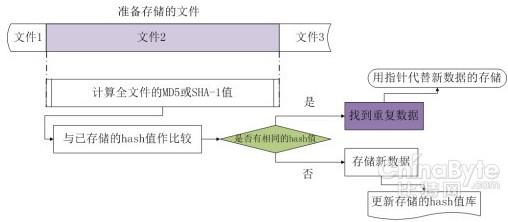
图 文件级别的基于相同数据检测
经典文献
u Single instance storage in Windows 2000
Bolosky WJ, Corbin S, Goebel D, Douceur JR. In: Proc. of the 4th Usenix Windows System Symp. Berkeley: USENIX Association, 2000. 13−24.
Windows 2000的单一实例存储(SIS)是作为支持远程安装服务的一个组件。由于远程安装中不同的machine image可能存在很多重复文件,所以Windows 2000可以用这项功能节省空间。
SIS 主要由两部分实现:内核级的文件系统过滤器,用于管理复制、修改和归并文件;用户级的数据检测器,用于搜索需要归并的相同文件。如下所示。
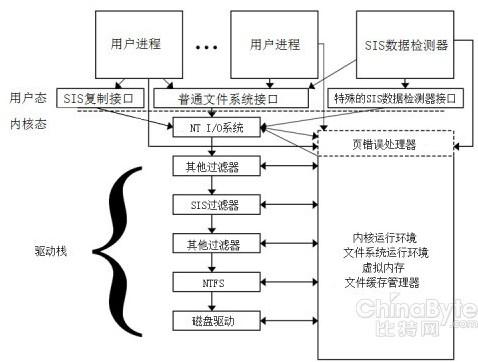
图 Windows SIS 实现原理图
用户态下的数据检测器用每个文件的128位摘要进行检测,摘要的前64位代表文件的大小。事实上,用64位表征文件大小的开销并不大,但它显然不能区分相同大小的不同文件。摘要的后64位是用文件的一部分计算出的hash函数值。过滤器从文件中部截取两个4KB的数据块计算它们的hash函数值。如果文件小于或者等于8KB,则直接用全文件计算。用户级检测文件系统的变化,维护一个文件hash值的数据库用来检测重复文件,然后将检测到的重复文件报告给过滤器。如果两个文件的摘要相同,数据检测器会进行仔细的二进制比较。
内核态下SIS是位于NTFS文件系统之上的一层过滤器,负责管理数据检测器检测出的硬盘卷上的重复数据。发现重复的文件时,SIS过滤器首先将文件拷贝到SIS公共存储区域中,接着将原文件位置用一个指向公共存储区域的链接代替。当用户进程试图读一个普通文件时,SIS过滤器将文件的去写请求重定向到SIS公共存储区域目录。当用户进程想写一个文件时,SIS采用copy-on-close策略。Copy-on-close策略和我们熟悉的 copy-on-write策略不同。复制操作不是在第一次写操作的时候执行,而是延迟到关于这个文件的所有更新操作都完成时才执行,并且只有新的数据才会被拷贝到公共存储空间。也就是说当文件在公共存储区域中有副本时,SIS的复制操作开销其实很小,只有SIS链接和新的数据。通过对具有20个不同 Windows NT映像的服务器进行测试,结果表明共节省了58% 的存储空间。
文件级别的相同数据检测可以检测出不同文件名的相同文件,也可以检测出不同目录下的相同文件,运算快速,便于实现。但由于hash函数的雪崩性,两个相似的文件即使只有一个字节不同,计算出来的hash函数值也会完全不同,因此文件之间依然会存在大量的重复数据。为了解决这个问题,研究者们提出了基于数据块级别的重复数据检测。

