
存储在线编译文章:就像在一个小黑屋里面相隔50步远的两个击剑手,用户和厂商都坚持自己刺出的是正确的方向。你是否向厂商要求可以匹配你应用程序的设置的基准测试?厂商测试中的存储解决方案的测试是否是基于你所将购买的设置的基础上的?
唯一能确保用户和厂商不会鸡同鸭讲的方法就是了解你的应用程序的IO模式。
了解你的IO模式
在我的前一篇文章中,我谈到了一个新的基准测试现实,即基准测试应该包含驱动器重建期间的性能并应该报告驱动器在负荷下重建结束的时间。我在那篇文章中评论道:“做一个补充说明,客户很经常要求一个不匹配他们IO模式的设置,而他们这么做的原因可能仅仅是因为小道消息,或可能是因为要实际描述他们应用程序的IO模式很复杂。”我想在本篇文章中谈到这个声明是因为人们经常忘记的一个非常非常重要的概念–了解你的应用程序的IO模式。
让我们来进行一个简单的试验。写下你系统上前三个应用程序。这些应用程序可以是最耗CPU时间或最经常运行或使用最多数据的或看起来最IO密集型的应用程序,甚至可以是运行得最慢的程序。你可以想想这些应用程序是如何进行IO的,然后写下你认为的IO模式。
其实这并不容易,不是吗?相信还是不相信,甚至应用程序开发人员都很难跟你讲清楚他们的应用程序是如何进行IO的。
开发人员所能告诉你的就是在应用程序执行期间的哪些点上会进行IO。他们有时会告诉你IO功能所使用的语言(比如,C和C++语言下的fwrite()、fread()、write()、read())他们经常关注的是算法本身而不是数据是如何进出存储的。
当然,我并不是真的怪他们,因为如果不注意他们的应用程序的IO模式的话,算法是很难设计的。不过,这也意味着要设计一个完全满足应用程序IO需求的存储系统几乎是不可能的。这就好像你到一家鞋店去想买10号网球鞋,结果出来的时候却穿着15号的拖鞋和一双黄袜子。随着数据增长速度的加快,这种情况越普遍。
如果你可以描述和演示你的应用程序的IO模式,那你就是我知道的少数可以做到的人之一。请公开一下你的结果和你所使用的流程,帮助其他人做这事。但是对于世界上其他的99.9%的我们来说,描述IO模式是非常难的。作为开始,让我们先使用一些典型的指标来描述IO模式。
从开始线开始
关于你的应用程序的IO模式,你能回答的最基本的问题是“IO是不是在运行时间中占很大比例?”换句话说,“IO是不是很重要?”
无论信与不信,这个问题也不是那么容易回答的。你必须能够衡量进行IO所花费的时间,同时还要不影响应用程序的总体运行时间。不过对许多应用程序来说,有一个简单的办法–Strace。
Strace是*nix类(Linux、Unix等)操作系统的系统跟踪工具。它可以跟踪系统调用并可以产生许多信息,比如完成状态(进程是否完成?),系统调用的参数,完成系统调用所花的时间,以及在读取和写入情况下,函数的成功状态(有多少数据被实际写入或读取?)。通过这些信息和一些工作,你可以检验应用程序的IO模式。
实际上,所有的IO都是通过系统函数调用来完成的,因此Strace应该可以捕捉许多IO信息。
一个提醒–如果应用程序在进行mmap IO而实际没有使用系统IO函数,那么strace就帮不了你。但是如果你在使用mmap IO,那么你会有其他问题,因此这种情况下了解IO模式可能不是那么着急的事情。
Strace信息可以让你从应用程序的角度来理解IO要求。它会告诉你应用程序向操作系统要求的系统函数调用,包括IO函数。换句话说,也就是应用程序在系统上进行的IO。数据要实际进入存储媒介还要经过好几个层,但是这是操作系统内部的事情,不是应用程序函数内的事情。
下面是一个写入一些数据结构的Strace输出的简单例子。
1373231279.242784 write(3, "1���2���3����� A2���3���4�����240A"…, 4096) = 4096 <0.000044>
1373231279.242921 write(3, "11��21��31���240 E21��31��41���@!E"…, 4096) = 4096 <0.000034>
1373231279.243064 write(3, "12��22��32���P240E22��32��42���240240E"…, 4096) = 4096 <0.000034>
1373231279.243188 write(3, "13��23��33���P360E23��33��43���240360E"…, 3712) = 3712 <0.000034>
1373231279.243283 close(3) = 0 <0.000013>
在这个例子中,我使用了“-T -ttt”选项,让Strace来获取每个系统函数的执行时间(最后在<>里面的数字)。
在上面的Strace输出例子中,每行的第一个数字是从标识函数开始时间的时间戳开始的秒数。实际写入的比特数也显示在“=”后面。在“)”前面的数值是被请求写入的数据量,而“=”后面的数值是被实际写入的数据量。
在上面的例子中,4KiB被发送于前三个写入的操作,而3712字节被发送于第四个写入的操作。这是发送给write()系统函数的数据量,后者然后将数据往下发送给操作系统,最终发送给存储媒介。
不过操作系统也有缓冲,并且会试图整合相邻的数据请求来改善整体性能。Strace输出不能搜集到这个信息–它只显示从系统函数到系统的数据。不过重要的一点是Strace可以从应用程序的角度来搜集IO模式信息。
前面Strace输出例子相应的C代码是来自C函数“fwrite”。这个函数会缓冲写入数据量,直到写入数据达到一个特定的量。在这个例子中是4KiB。然后这个函数会执行一个write()系统函数。你可以使用更大的缓冲(这里面有很多可讲的),不过这是开发人员的工作。
通过Strace输出的信息,你可以看到应用程序在每个写入函数上正在向操作系统发送的数据量。如果你喜欢,你可以认为这是从应用程序来的“数据大小”或“写入大小”(同样也适用于读取)。你可以浏览一个完整的Strace输出文件,然后获得应用程序的写入大小分布。实际上,你可以按下图的例子制作一个写入大小的柱状图–按字节范围(0-1KB)。
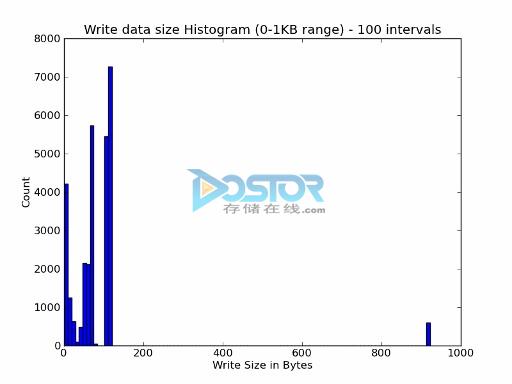
图1:写入大小柱状图例子
在同厂商讨论存储解决方案的时候,这个柱状图会非常有用。你可以跟他们显示这个柱状图并解释应用程序strace的输出信息。然后你可以让他们做同样的事情做至少提供他们运行过的测试/基准测试的同样信息。如果这些模式是类似的,那么他们的测试/基准测试结果可能对你的应用程序是有用的。你不需要去匹配整个柱状图,你可以匹配其中的部分区间。
你还可以分析每个写入函数调用中的数据量,将它们除以完成时间。这可以让你看到函数调用的吞吐率。这也是有用的信息,不过写入或读取调用的合并以及高速缓存可能会影响时间量。不过至少你可以看到一些吞吐率信息(还有一些其他资源可以获取应用程序的吞吐信息,不过这就另话了)。
除了IO系统调用的大小外,IO模式的另一个非常重要的方面就是了解它是顺序的还是随机的数据访问模式(或是两者的组合)。顺序访问意味着你的应用程序访问一个文件中的特定部分数据(读取或写入),同时下一个访问从上一个访问结束的地方开始。从iseek()函数或rewind()函数或类似函数中可以看到数据访问之间没有文件指针的移动。一个简单的例子就是从一个文件中读取4KiB数据并访问文件中的下一个4KiB数据。
随机访问IO模式则访问一个文件中的某个数据,而下一个数据访问不是下一个数据块而是文件中的另一个数据块(随机位置)。一个简单的例子就是从一个文件中读取4KiB,然后将文件指针移动到文件中的18KiB的点并读取下一个4KiB。这个例子的IO操作绕过了4KiB到18KiB中间的数据,而18KiB并不是4KiB的整数倍,这让文件指针位置变得更加随机。如果你在一个看起来随机的模式中进行这样的模式,那么你可以考虑它是一个随机的文件访问IO模式。
你可以用Strace信息来检验数据访问是顺序的还是随机的。你只要在0位置开始浏览strace文件。在读取一个文件中4096字节后,文件指针是在4096(一个read()函数的strace输出结果会告诉你读取了多少字节的数据)。Iseek操作会告诉你最终文件指针的位置(按字节)。对修改现有文件指针的其他函数来说也是如此。然后你就可以为文件指针位置绘制一个时间序列图。
如果这个文件是完全被顺序访问的,那么文件指针的时间序列曲线将是一阶函数曲线。不过,如果文件被关闭和被重新打开的话,文件指针将跳回到原点。一个简单的例子就是从头到尾读取一个文件,这样文件指针散点就是一个不断增长的值。
另一方面,如果文件指针值不是时间的直线函数,那么文件访问IO模式很可能是随机的。不过,你要仔细观察文件指针值,因为有时候一些底层的模式会让这些散点以某种顺序的形式出现。
我觉得你可能会惊讶于你的应用程序的IO模式。你可能会发现你的应用程序做了很多顺序IO。不过,要记住的是,运行许多应用程序的生产系统有可能在同一时间进行IO。因此,存储系统有可能认为它是遇到的是一群随机IO。
IOPS
人们讨论的IO模式的第三个方面就是IOPS(每秒I/O操作)。人们喜欢讨论一个IO操作是什么,但是我个人认为有三个IOPS指标:(1)读取IOPS(每秒read()操作);(2)写入IOPS(每秒write()操作);(3)总IOPS(每秒所有的IO操作)。这第三个指标,总IOPS,统计了读取、写入以及在我看来的任何IO操作。
在测试存储硬件的IOPS的时候,人们经常将一个读取或写入IOPS定义为4KB数据大小,因为这通常是一个操作系统所产生的最小的写入或读取函数大小。它还是Linux glibc(看stdio.h)的缺省缓冲大小。不过4KB大小从任何一方面看都不是一个标准。
你可能会看到一些用0KB大小来进行IOPS测试的厂商–也就是说,实际上磁盘上没有数据被读取或写入。我还看到一些厂商用1字节或1KB大小来测试。
基准测试中常见的另一个误区就是用某种比例的读取和写入来进行基准测试。一个常见的比例是25%的读取和75%的写入。它的目的是为一个同时进行读取和写入的应用程序提供一个单一的IOPS指标。不过,这样做让这个性能指标很难适用于不使用这种比例的IOPS的应用程序。这限制了这些指标的可用性。
Strace提供IOPS模式信息。你可以在给定的秒数间隔下计算特定IO操作的数量来获得这个信息。这样你可以方便地计算出读取IOPS、写入IOPS以及总IOPS。
元数据–它也很重要
IO模式的另一个方面经常被人们所忽略,那就是元数据指标。元数据是有关数据的数据,是存储解决方案性能的非常重要的一面。元数据指标是很重要的,因为一些应用程序可能在执行的时候要进行许多元数据操作。
不过,一个有争议的问题是什么是元数据操作?个人认为元数据操作就是任何影响文件系统中文件的元数据的IO操作。它包含stat()操作、读取或写入数据、文件创建或删除、文件的日期或访问许可修改、readir()信息等。不过典型的元数据率指标是:(1)每秒文件创建数;(2)每秒文件删除数;(3)每秒文件stat()次数。
在这个情况下,strace也可以帮到你。要想获得元数据函数率,你可以浏览strace文件并根据时间单位来计算特定元数据函数的次数。它们可以成为从应用程序角度看的元数据率指标,丰富你的IO模式信息。
对存储设计的影响
如果你能估计出我前面所提到的所有指标,那么你可以编制出下面这张表:
- 进行IO所花的时间;
- 读取/写入函数大小;
- 读取/写入吞吐率;
- 顺序或随机文件访问;
- IOPS(读取、写入、总的)
- 元数据指标(文件创建、文件删除、文件stat());
这么多信息都是有关你的应用程序的IO模式。此外,使用应用程序strace中所有的信息,你还可以计算出每个IO模式元素的大量统计信息。
例如,你可以绘制出一个读取/写入函数大小的柱状图来了解这些函数的分布。你还可以计算出它们的平均值、中位数以及模式来让你理解“典型”的读取/写入大小。此外,你可以计算围绕平均数和中位数的标准差来了解这些函数大小的分布特征。
还有一些其他的统计指标可以让你了解不同指标的分布。基本上,你可以使用上面的这些指标加上统计数据来描绘你的IO模式。不过,关键是要能够理解并应用这些指标来设计或规范一个存储解决方案。
即使有大量的有关应用程序的IO模式的统计信息,你也无法完全科学地设计一个存储解决方案。不过你还是可以遵循一些原则。
你要检查应用程序的高峰IOPS(读取、写入和总的)。如果应用程序看起来花很多时间进行IO而IOPS也比较大,那么你将可能需要大量的硬盘驱动器来满足应用程序的IOPS需求。一个简单的方法就是想到7200转SAS驱动器大致可以进行100次IOPS(实际上可以更高,不过100这个数字可以更方便我们开始)。然后,你可以将高峰IOPS除以100来寻找你所需要的驱动器的数量。在给定的单个驱动器容量下,你可以计算出存储解决方案的总容量(不要忘记RAID要求,它会增加驱动器的数量要求)。
如果总的解决方案容量太大,你还可以选择将硬盘驱动器换成SSD(固态驱动器)。不过,在你选择将SSD作为存储媒介之前,要确定你的应用程序确实要进行许多IO并且它是IOPS驱动型的。同时,要确定你可以获得足够的驱动器容量来满足你的整体的容量要求。我见到过有一个应用程序有非常高的高峰IOPS(超过10万次),导致这名用户开始考虑将SSD作为存储媒介。不过,这个应用程序只有不到3%的运行时间在进行IO。即使SSD有无限的性能,这个应用程序的性能也只会提升3%而已。因此,这种情况下并不适用SSD,至少SSD不是高成本效率的。
整体上,IO模式信息可以帮助厂商了解你的应用程序是怎么进行IO的以及他们需要做什么来更有效地运行应用程序。
厂商影响
厂商们要面对的是许许多多的要进行大量IO的应用程序。基于这一点,他们需要决定哪些应用程序需要被测试或在给定解决方案下进行基准测试,同时可能最重要的是,解决方案的设置看起来应该怎么样(他们无法测试所有设置)。
不幸的是,许多厂商做的就是创建一个病态的设置来获得最好的TPC或SpecSFS分数。这些设置是客户永远也不会用到的,只是一个号称拥有最佳TPC或SpecSFS分数的噱头。因此,这些厂商就是在运行我们所谓的英雄基准测试(无视设置的最好的分数)。他们运行一个英雄基准测试、发布成绩、进行新闻发布,然后没有人购买他们测试过的设置。
我不是真的责怪他们,因为可能的IO模式真的非常多,不过这些厂商做得太过分,他们不是关注用户的应用程序,而是去关注那些与用户应用程序毫无相像之处的基准测试。此外,他们所测试的设置不会被任何人所购买,因为他们测试的设置和应用程序的需求没有多少共通之处。
用户最好将你的IO模式信息交给厂商并指出你想要测试些什么。他们也许有办法使用微型基准测试来在标准测试系统上(不要忘记构建和操作测试系统是需要钱的)模拟你的IO模式。准备好和这些厂商协同工作来获得他们解决方案上最好的测试而不是扔给他们一堆基准测试来看哪个厂商可以完成最多的测试(有些客户经常这么做)。
此外,要确保给厂商足够的时间来运行测试和针对给定测试调整解决方案。这样做不仅帮到厂商,对你也有好处。你可以看到这些厂商提供哪些选项来帮助应用程序改善性能或降低解决方案成本(换句话说–给他们时间并保持开放的心态)。
小结
在本文中,主要的要点可以被轻松的归纳为:IO模式可以帮助到所有人–用户和厂商。IO模式帮助用户了解他们的应用程序是如何“进行”IO的,从而让他们理解哪些地方可能有潜在的瓶颈以及哪些地方有潜在的可能来改善应用程序的性能。IO模式可以帮助到厂商是因为他们可以更清楚地了解用户从他们的解决方案中需要什么,这样就不会去运行愚蠢的毫无意义的基于不会有人购买的设置的噱头型基准测试。
通过简单的工具,比如strace,你可以从应用程序的角度来了解IO模式。抽出有用的信息并不很难,包括IO所花的时间、读取/写入数据大小、顺序或随机文件访问、吞吐率、IOPS以及元数据率。所有这些信息可以帮助你作为一名用户来观察那些可能满足你要求的存储解决方案,而这些信息也可以帮助厂商更关注于真正有用的解决方案和设置。
最后我想指出的一点是许多人没有看到IO模式信息可以帮助开发人员重新设计应用程序的IO模块来改进性能。如果文件访问模式过于随机,那么开发人员可以想一些办法来让文件访问更加顺序化从而利用好存储媒介的吞吐率。如果读取/写入数据大小太小,那么硬盘驱动器的数据流性能可能会受影响。这也可以在应用程序中做出改变从而改善整体性能。
请你好好看看你的应用程序的IO模式–你不会后悔的。
