
本文是针对IBM系统架构师王文杰先生(valen_won@hotmail.com)在其博客园的置顶博文思考EXADATA(链接原文地址: http://www.cnblogs.com/wenjiewang/archive/2012/10/07/2714406.html)中提到的一些关于Exadata观点,从技术角度给出我个人的一些不同的见解,当然本人水平有限,难免出现疏漏甚至错误。
以下简要总结一下文杰先生博文中提到关于Exadata的观点:
1. 数据仓库(Data Warehouse)类型的应用无法充分利用smart scan的特性,尤其是对于数据仓库中常见的星型转换(star transformation), Exadata无法优化;
2. Exadata Bug众多,某些新特性名存实亡,并举例说明其在布隆过滤器的使用过程中遭遇到的bug。
3. Oracle数据库Bug众多,使用Exadata对于业务逻辑复杂,数据正确性非常敏感的金融行业存在很大的风险;
4. 维护成本高,要使用Exadata,DBA需要重新学习大量的主机,存储,网络方面的知识,否则无法胜任一体机管理员的工作;
5. 对于动辄单表上百个字段的数据仓库而言,Exadata 的Storage Index形同鸡肋,因为对于每个表只能自动维护8个列,与杯水车薪无异;
6. Exadata还是RAC, RAC的share everything架构导致存在大量的cache fusion争用,与OLTP应用格格不入。
7. RAC对ERP支持不好,导致很多ERP用户不使用RAC,Exadata只提供RAC的模式。
8. Exadata磁盘容量太大,对于OLTP而言这简直就是浪费;
9. Exadata不提供任何虚拟化技术,不能充分利用其硬件资源,而它的竞争对手确提供非常成熟的虚拟化解决方案;
10. (这年头,要凑不齐十条出门都不好意思跟人打招呼)Exadata的价格十分昂贵,普通的用户根本无法承受。
以下是我个人的回应,不代表Oracle公司的官方立场。Oracle的salary还没到我想做Oracle公司5毛的冲动。 如果您爱看软文,那么您可以请移步Loveunix和AIXchina,因为那里比较多。很多技术细节三言两语很难解释清楚的,限于篇幅,这里力求简介或者一笔带过。
1. 实际上smart scan可谓是Exadata所有技术的核心,离开了smart scan,Exadata就没有了灵魂。而Exadata的smart scan的条件过于苛刻,一直以来备受竞争对手的诟病,这个也是事实。 但是文中提到的 “如果我们的报表如果不是走FULL TABLE SCAN,则无法利用到这一特性。复杂的查询,诸如Joins, sorts, group-bys, aggregation都很可能无法利用到智能扫描。” 这一说法是不准确的。我这里不厌其烦的列举一下目前smart scan的条件:(虽然这是一个错误的“真理”)
· Full scans——Table, Partition, Materialized View, Index (FAST FULL SCAN Only)
· Direct Path Reads
· Exadata Storage
对于较复杂的排序,聚合类的操作,storage index就有它的用武之地了。至于星形转换,作者说的恐怕也不是事实, 这篇文章和这篇文章详细介绍了在data warehouse中, Oracle内部是如何对星型转换进行优化的一些细节。
2. 布隆过滤器是一种处理大量数据的哈希算法, 具体算法可以参考wikipedia条目 Bloom Filter, 或者参考google的吴军先生的《数学之美》一书。当然这里提到的bug也是不准确的, 这里提到的两个bug:9124206和bug: 8361126, 实际上是同一个bug即base bug为8361126。
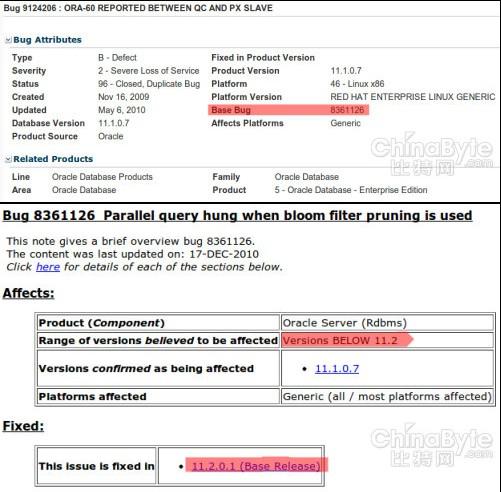
文章中另外提到的bloom filter的bug应该是Bug:12637294了,但是这个bug在11.2.0.3 BP11已经修复。
另外很有意思的是smart scan内部也是使用Bloom Filter的算法进行数据过滤的。
3. Oracle Bug多是众所周知的事实, 从每次的Patchset Release/PSU的bug list可以看出,很多bug的危害也非常大。 甚至作者说的wrong result也完全是事实,但是这并非是无缘无故会出现的,这些bug大都是在一些极端的情况下触发。如果应用经过了充分的测试,那么则很少会遇到 wrong results。 触发wrong results bug比较常见的一些情况是并行, 复杂的表连接等操作。MOS有一篇文档详细的介绍了如何诊断和分析此类问题: Wrong Results Issues – Recommended Actions [ID 150895.1]。顺便说一句: 越来越多金融行业客户把Oracle数据库当作核心了。
4. 维护成本的问题。维护没有作者说的那么严重。主机是PC server,硬件没有什么特殊之处。操作系统是Linux X86_64,很多SA/DBA都已经非常熟悉了。 网络维护也并不需要额外的知识,只需要了解一些常用的infiniband/cisco交换机的操作。 Exadata上的数据库维护与普通的RAC数据库并没有两样。唯一需要重新学习的是存储端的知识, 而这一部分内容很多都能从互联网上获取到。(万一实在无法胜任,Oracle公司推出了一站式白金服务,用户可以将管理“外包”给Oracle公司,笑,请进入自动忽略广告模式)
5. Storage Index每个表只能自动维护8个列这是事实,但是这并非是什么技术上的限制, Storage Index和Netezza的Zone Maps技术原理上是不一样的。Storage Index一个重要的概念就是只对排序字段起作用,对于无序的字段是无法用到它的, 所以Storage Index每个表超过8列对性能上没有多少帮助,因为一个表核心并且需要用于排序的字段并不多。
6. 这个问题实际上还是share disk和share nothing的架构之争,老掉牙的话题了,没有太多实际意义。
7. 目前行在Oracle DB上的SAP ERP远比运行在DB2上的ERP要多,有兴趣可以查看gartner的统计数据。
8. 现在硬盘白菜价了,单块盘就2-3T了,谁还在意这么一点空间? 况且OLTP应用数据量在1T以上的也不在少数。
9. 这一条说的是事实,但是
· vmware这样的虚拟化平台目前没有通过Oracle认证;
· IBM LPAR不属于严格意义上的虚拟化技术;
· Exadata上可以通过像IORM/instance cage/cgroups这样的方式来实现资源隔离;
· 未来应该会考虑使用Oracle自己的OVM。
10. 相比高端主机+高端存储动辄几百上千万, Exadata性价比不算差吧?现在Exadata X3推出了1/8配,开始抢自家小兄弟ODA的饭碗了。。。

