
根据The Social Network工程团队关于解释新发布的开源代码的注释,Facebook的数据仓库“每24小时增长超过0.5PB”。
该注释说明,Facebook的数据仓库执行“随即查询、数据管道、自定义MapReduce作业处理这些原始数据,昼夜不停地产生越来越多有意义的功能和聚合”。
但是Apache Hadoop无法承担这个任务,因此Facebook创建了代号为“Corona(日冕)”的平台,这样就可以应对每天数量庞大的数据。
按照解释,“最初我们采用来自Apache Hadoop的MapReduce作为这种架构的基础,多年来一直运行稳定。但是到了2011年年初,该系统开始接近极限。”
这些限制导致计算集群堵塞,主要归结于MapReduce的调度问题,而资源管理也是Facebook一大严峻需求。
下图显示了Facebook如何描述MapReduce的特点:

相比之下,Corona提供了如下所示的配置:
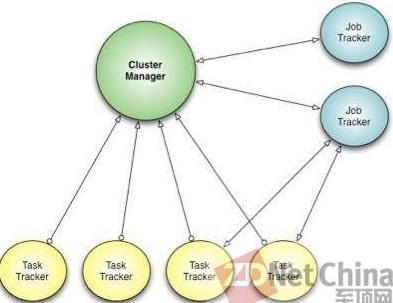
Facebook是这样描述Corona:
“Corona引入了一个集群管理器,它的唯一目的是跟踪集群中的节点和空闲资源的数量。每个作业都有一个专门的跟踪器,并且可以运行在与客户端相 同的进程中(针对小型作业),或者作为集群中一个单独的进行(针对大型作业)。这与之前Hadoop MapReduce部署的最大不同之处,在于Corona采用基于推送、而不是拉取的调度机制。在集群管理器接收到来自作业追踪器的资源请求时,它将资源 推送回作业追踪器。而且,一旦作业追踪器获得资源授予,它就会创建任务,然后将这些任务推送到任务追踪器中运行。在这个调度过程中,没有周期性的心跳,因 此调度延迟被降至最低。”
通过博客,我们还了解到Facebook如何引入这个新工具,以及一些见解,关于Facebook基础设施从500个节点的集群开始获取“来自早期采用者的反馈”。
在该工具引入到Facebook所有服务器中之前,一个1000节点的试验就遇到了第一个扩展问题。
Facebook现在已经启用Corona,采用合适的开源规则,并且相信Corona将是“未来几年内”一个非常重要的工具。
考虑到Facebook的数据仓库“在过去4年中增长了2500倍”,Corona将担负着沉重的数据处理任务。但这仅仅是数据仓库:究竟Facebook有多少数据,并未披露,关于Corona将交付怎样的产品和数据分析,我们也不得而知。



