
在以前的博客中,我预言说“看到了未来的固态存储,并且它是向外扩展(Scale-Out)的”。即使是少数固态硬盘可以提供的纯粹性能,对于一个传统的Scale-up(向上扩展)存储控制器来处理也实在太多。这个问题就变成了:如果存储的未来是向外扩展的,哪一种向外扩展存储架构是最好的?
当然,向外扩展存储架构不只是针对固态(闪存),Scale-out的NAS、对象的存储系统已经解决了十年间的一类或另一类大数据问题。随着时间的推移,我们已经看到厂商推出了几种不同的Scale-out架构,每一个都以自己的方式吸引人注意。
最简单的方法是使用共享磁盘的集群文件系统,如IBM的GPFS或者昆腾的StorNext,像IBM SONAS或赛门铁克FileStore那样建立一个Scale-out的NAS系统。这些系统使用一个中央SAN阵列并由多个NAS头进行数据的管理。系统规模和它们的性能是被共享存储阵列限制的。尽管集群文件系统对于那些需要大型、快速文件仓库的组织是一个很好的解决方案,但他们不是针对固态存储的答案,我们的问题主要是在阵列控制器中,不会比在文件系统中更多。
我们需要的Scale-out闪存是一个“无共享(shared nothing)”的集群,它允许我们将节点添加到系统中,并且没有任何单一的瓶颈点,就像在一个集群文件系统中的共享阵列。正如我们在shared nothing存储系统看到的,全固态和那些基于旋转磁盘的,我们看到了两种完全不同的架构。
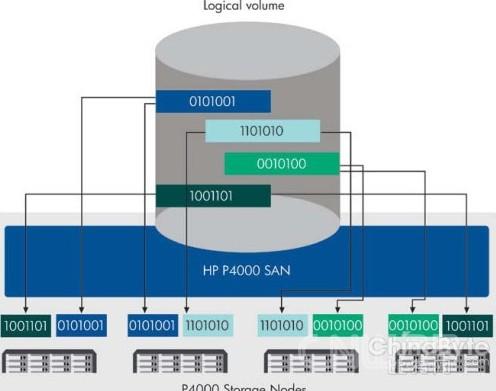
一些厂商,像在全固态市场中的SolidFire、惠普的LeftHand,以及大多数对象存储系统,由独立存储节点建立了他们的存储集群。为了让系统在存储节点丢失时可用,他们在阵列中跨越两个或者更多的节点镜像数据。这种方法保持了节点硬件的简单,通常是使用现成的服务器,但因为所有的数据是跨多个节点镜像的,它们必须存储所有数据的至少两个副本。因此,它们并不十分节省空间。尽管磁盘空间是便宜的,SSD则没有那么好,这可能将固态存储厂商推向twin(孪生)模式。
归档数据的存储系统,可以使用跨节点的RAID或者更好的擦除编码来跨多个节点分布数据,没有镜像的开销,这些方法不适合固态存储系统处理的低延迟、高IOPS应用。EMC的Isilon使用了一种结合镜像随机访问的文件或文件夹,以及针对旧文件和那些将被顺序访问的使用擦除编码,就像媒体文件。
与其使用一个简单的存储节点,像机架式服务器,作为它们的构建块会有自己的单点故障,不如像戴尔/EqualLogic和NetApp使用双控制器系统建立一个集群的成对系统。由于每个存储节点有两个控制器和一个存储块,它可以使用RAID数据保护,保持开销下降。系统设计人员还可以通过添加驱动器架到控制器对建立混合的scale-up/scale-out。
成对系统的缺点是他们在控制器发生故障时的状态。当成对系统中的一个控制器失败,它的“孪生兄弟”必须接管其工作负载,这可能会导致显着的性能损失。大多数对等系统从一个单节点跨越集群中的所有其他节点分发数据的第二副本,因此一个节点故障对性能的影响较小。
全固态系统悬而未决的问题是,厂商如何平衡针对单节点系统的附加SSD容量成本,以及在twin系统中附加控制器的成本。这将变得清晰可见,就像我们看到来自Pure Storage那样的scale-out“孪生”系统。



