HayStack是Fackbook用于存储照片的系统,其存储照片的数量在千亿数量级,本文简要分析HayStack的设计与实现原理。
图片存储的几个关键点:
1. Metadata信息存储。由于图片数量巨大,单机存放不了所有的Metadata信息,假设每个图片文件的Metadata占用100字节,260 billion图片Metadata占用的空间为260G * 100 = 26000GB。
2. 减少图片读取的IO次数。在普通的Linux文件系统中,读取一个文件包括三次磁盘IO:读取目录元数据到内存,把文件的inode节点装载到内存,最后读取实际的文件内容。由于文件数太多,无法将所有目录及文件的inode信息缓存到内存,因此磁盘IO次数很难达到每个图片读取只需要一次磁盘IO的理想状态。
3. 图片缓存。图片写入以后就不再修改,因此,需要对图片进行缓存并且将缓存放到离用户最近的位置,一般会使用CDN技术。
HayStack的主要目标:
1. High throughput and low latency(高吞吐量、低延时):简化元数据结构与存储模式,直接存储文件在物理卷上的位置,减小lookup时间。
2. Fault-tolerant(容错性):在不同的机器上维护多个副本
3. Cost-effective(高效):提高存储空间利用率、提高请求处理效率。
4. Simple(简单):易于实现和维护,部署周期短。
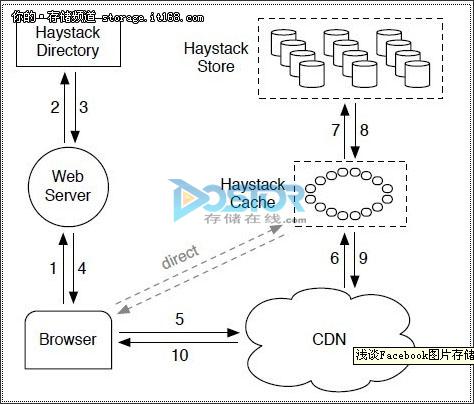
HayStack的总体架构:
Haystack的写请求(图片上传)处理流程为:Web Server首先请求Haystack Directory获取图片的id和可写的逻辑卷轴,接着将数据写入对应的每一个物理卷轴(备份数一般为3)。
Haystack图片读取请求大致流程为:用户访问一个页面时,Web Server请求Haystack Directory构造一个URL:http:// / / / ,后续根据各个部分的信息依次访问CDN,Cache和后端的Haystack Store存储节点。Haystack Directory构造URL时可以省略部分从而使得用户直接请求Haystack Cache而不必经过CDN。Haystack cache收到的请求包含两个部分:用户Browser的请求及CDN的请求,Haystack cache只缓存用户Browser发送的请求且要求请求的Haystack Store存储节点是可写的。一般来说,Haystack Store的存储节点写一段时间以后达到容量上限变为只读,因此,可写节点的图片为最近增加的图片,是热点数据。
Haystack 删除操作比较简单,只是在 Haystack 存储的指针上设置一个已删除标志,已经删除的指针和索引的空间并不回收。可通过定期的对物理卷进行合并,以回收已删除的空间。
Haystack Directory的主要功能如下:
1, 提供逻辑卷轴到物理卷轴的映射,为写请求分配图片id;
2, 提供负载均衡,为写操作选择逻辑卷轴,读操作选择物理卷轴;
3, 屏蔽CDN服务,可以选择某些图片请求直接走HayStack Cache;
4, 标记某些逻辑卷轴为read-only;
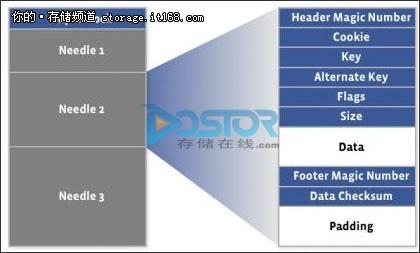
HayStack中的图片顺序的存放在物理卷中,获取图片在物理卷中的偏移即可读取图片,图片的存储结构如下所示(每张图片称为一个needle)。
其中,key为图片的唯一标示,alternate key为尺寸的标示,flag为删除标志,size为数据大小,data为实际的数据。
HayStack为每张图片在内存中维护图片与其位置的映射表,在图片被写入时更新映射关系,每次系统启动时可通过读取物理卷并构造映射表,但这样做很耗时间,但HayStack通过为每张图片构造index file来简化了系统启动时映射表的构建,index file的结构如下所示:(其主要包含key与对应图片位置的映射关系,系统启动时,通过读取index file便能很快的构造映射表。)

HayStack的几点优势:
1. 采用轻量级的HayStack Directory维护逻辑卷到多个物理卷的映射关系,方便的实现了副本技术,以实现系统容错。
2. 简化文件的元数据结构,以追加写的方式往物理卷中存储图片,效率高。同时将图片key与位置的映射关系全部保留在内存中,通过一次lookup即可获取图片的位置。
3. 物理卷中所有的图片都对应有index文件(固定大小,结构简单),从而每次系统重启时,物理卷的映射信息能快速的通过index文件构建。
4. 引入delete flag、compaction、batch upload以及进一步提高存储的效率。