
本文首发于《信息存储》2006年度专辑上,未经许可,谢绝转载。
HPC(高性能计算High Performance Computing,也称超级计算)历来是石油、生物、气象、科研等计算密集型应用中的首要技术问题。早期的HPC系统,主要以IBM、Cray、SGI等厂商的大型机或并行机为硬件系统平台。随着Linux并行集群技术的成熟和普及,目前HPC技术主流已经转向以IA架构为硬件平台,以Linux并行集群为系统平台的廉价系统为主。近年来,这一技术又进一步发展,各厂商目前竞相追捧的网格计算技术,从某种意义上说,就是这一架构的延伸。鉴于Linux并行集群技术在HPC应用中的主流地位及快速发展趋势,本文主要讨论的也是这一架构中的存储系统问题。
当前Linux并行集群的困惑—-遭遇I/O瓶颈
Linux并行集群中的计算资源按其功能角色不同,通常被分为两种:“计算节点”和“I/O节点”。其中计算节点负责运行计算任务,I/O节点负责数据的存储并响应计算节点的存储请求。目前Linux并行集群一般采用单I/O节点服务多计算节点的模式。从硬件角度看,I/O节点和计算节点都是标准的IA架构,没有本质区别。计算所需要的初始数据、计算得出的最终数据以及并行计算平台本身,都存储于I/O节点上。计算节点与I/O节点间一般采用标准NFS协议交换数据。
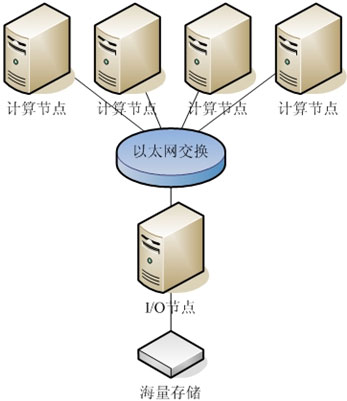
当一个计算任务被加载到集群系统时,各个计算节点首先从I/O节点获取数据,然后进行计算,最后再将计算结果写入I/O节点。在这个过程中,计算的开始阶段和结束阶段I/O节点的负载非常大,而在计算处理过程中,却几乎没有任何负载。
提高各计算节点CPU频率和增加计算节点数量,可以提高集群整体的计算处理能力,进一步缩短处理阶段的时间。在当前的Linux并行集群系统中,集群系统的处理能力越来越强,每秒运算次数在迅速增长,于是集群系统真正用于计算处理的时间越来越短。然而,由于I/O能力改进不大,集群系统工作中的I/O效率没有明显进步,甚至会随着计算节点数的增加而明显降低。
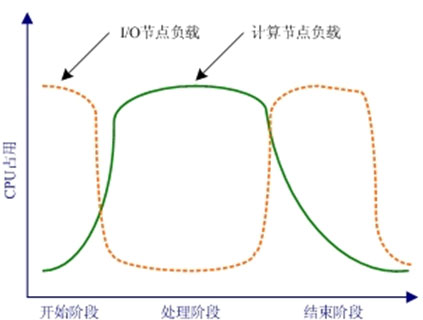
实际监测结果显示,当原始数据量较大时,开始阶段和结束阶段所占用的整体时间已经相当可观,在有些系统中甚至可以占到50%左右。I/O效率的改进,已经成为今天大多数Linux并行集群系统提高效率的首要任务。
解决I/O瓶颈的初步探讨—-瓶颈到底在哪里?
在上面的系统结构图中可以看出,如果把“以太网交换”以下的部分统统看作存储系统的话,那么可能的瓶颈无外乎以下三种:
- 存储设备本身性能,姑且称之为“存储设备瓶颈”
- I/O节点与存储设备间的连接,姑且称之为“存储通道瓶颈”
- 计算节点与I/O节点间的网络交换,姑且称之为“网络交换瓶颈”
目前的存储设备类型丰富,种类繁多。仅中端设备中,容量扩展能力在几十TB,每秒处理数万次I/O,数据吞吐带宽在数百MB/s的设备就有很多种选择。以勘探数据处理系统为例,在一个32计算节点的叠前处理系统中,如果需要使每个计算节点得到15~20MB/s的带宽,那么集群对后端存储的总体带宽(即聚合带宽)要求大约为500~650MB/s。目前的中端磁盘阵列产品基本都可以达到这一性能指标。如果考虑64个或更多计算节点,后端带宽要求需要达到1~1.3GB/s甚至更大,这一性能是目前单一中端磁盘阵列系统难以达到的。然而通过引入多台存储设备,这一问题也不难解决。
目前的存储设备通道技术主要以SCSI和FC为主。目前单条FC通道可保证200MB/s的传输带宽,以4条通道并行工作就可以达到800MB/s的带宽保证。这一指数已经完全可以满足32个计算节点并行工作的带宽要求。此外IB(InfiniBand)技术作为新兴通道技术,更进一步保证了通道带宽。目前已经产品化的IB交换技术已经可以达到10~30Gb/s的带宽,是目前FC技术的5~15倍。在这样的带宽保证下,既便是256或512节点的集群也可以与存储设备从容交换数据。
这样看来,“存储设备瓶颈”和“存储通道瓶颈”似乎都不是难以解决的问题,那么“网络交换瓶颈”的情况又如何呢?
照搬前面的计算方法,如果要为前端32个计算节点提供15~20MB/s的带宽,I/O节点需要提供至少500~650MB/s的网络带宽。这就是说,既便完全不考虑以太网交换的额外损耗,也需要安装6~7片千兆以太网卡。而一般的PC或PC服务器最多只有两个PCI控制器,要想保证这6~7片千兆以太网卡都以最高效率工作,完全是不可能的。更何况一般以太网的效率,只有理论带宽的50%左右。就是说实际上要想达到500~650MB/s的实际带宽,需要13~15片千兆以太网卡,十几个64位PCI插槽!这大概是目前最高端的PC服务器所能提供的PCI插槽数目的二倍。
照此看来,单一I/O节点架构无疑是整个集群系统性能死结。那么考虑多I/O节点的架构会如何呢?笔者的观点是:多I/O节点架构困难重重,但势在必行。
解决I/O瓶颈的途径—-多I/O节点架构
引入多I/O节点架构,涉及到很多存储技术。笔者下面的分析中,主要考虑了FC-SAN,iSCSI-SAN,基于SAN的文件共享以及PVFS(并行虚拟文件系统)等技术手段。
方案一、简单SAN架构下的多I/O节点模式
实现多I/O节点,最容易想到的第一步就是引入SAN架构。那么,我们就先来分析一下简单的SAN架构能否满足Linux并行集群的需求。以两个I/O节点为例,下图是多I/O节点的结构框图:
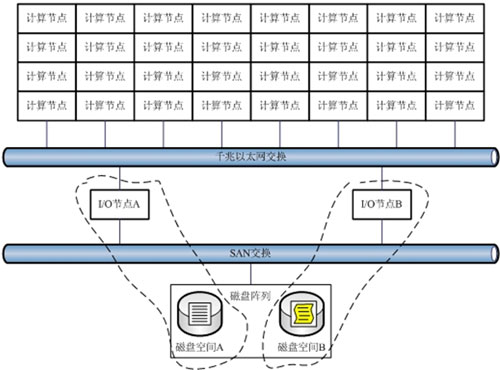
从图中可以看到,由于基本的SAN架构不能提供文件级共享,两个I/O节点还是完全独立的工作。前端的所有计算节点如果同时读取同一个文件的话,还必须经由一个I/O节点完成。由此可见,在单一任务情况下,多I/O节点的结构形同虚设,根本无法负载均衡的为前端计算节点提供服务响应。为了解决这一问题。可以考虑在多I/O节点间需要引入文件级共享的工作机制。
方案二、多I/O节点间文件级共享
在引入文件共享技术的SAN架构下,各个I/O节点可以同时读取同一文件。这为I/O节点间的负载均衡提供了可能。然而SAN架构下的文件共享并没有解决所有问题,其实这一技术仅仅是为解决问题提供了底层的支持而已。
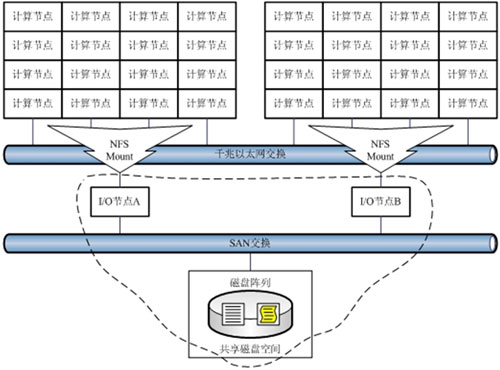
从图中可以看到,所有计算节点被人为划分成两部分,每个I/O节点为其中一个部分提供I/O服务响应。也就是说,在计算节点的层面上,系统是手工负载均衡,而非自动负载均衡。在大多数实际应用环境中,手工负载均衡意味着繁重的管理工作任务。每当增加新的计算任务或者调整参与计算的CPU数量时,几乎所有的NFS共享卷绑定关系必须重新配置。而当多个作业同时运行,尤其是每个作业要求的CPU资源还不尽相同时,配置合理的绑定关系将是系统管理人员的一场噩梦。
造成这一问题的根本原因在于,多I/O节点为系统引入了多个逻辑数据源,而目前主流并行集群系统都是在单一数据源的结构下开发的。既然现有应用不能在短时期内有所改变,能否在提高前端计算节点I/O能力的同时,回归到单一逻辑数据源的结构呢?其实,以目前的技术而言,答案是肯定的。
方案三、单I/O节点蜕化为MDC,计算节点直接接入SAN
目前SAN架构下文件共享的技术已经较为成熟,如果将全部计算节点都接入SAN,而将I/O节点设置为MDC(Meta Data Controller),就可以在提高系统I/O能力的同时,形式上保留原有的单一I/O节点,单一数据源的逻辑结构。
在这一架构下,各个计算节点形式上还是通过NFS共享访问I/O节点,但实际的数据读写路径则通过SAN交换直接到达磁盘阵列。这种模式的可行性已经在现实中被证实。例如,IBM公司的GPFS技术就是以这种方式解决集群的I/O瓶颈问题的。
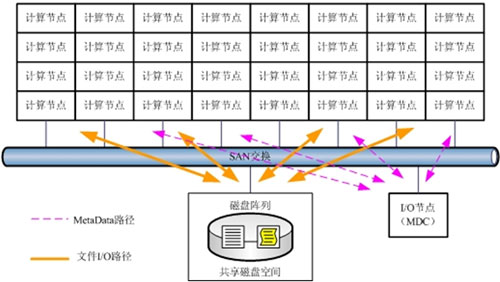
这一架构从技术上看似乎是无懈可击的。它真的一举解决了所有问题的问题吗?非也!当考虑到成本的时候,问题就出现了。即使按照最保守的32个节点计算,在不考虑容错的前提下,整个SAN系统需要至少提供32个端口用于连接主机,另外还至少需要4个端口连接磁盘阵列。要建立如此庞大的SAN网络,其成本将相当可观,这也就失去了Linux并行集群的最大优势—-性能价格比。
FC-SAN的成本昂贵,能否考虑替代技术呢?那么不妨考虑以相对成本较低的iSCSI技术替代FC的解决方案。
方案四、以iSCSI技术取代FC
以iSCSI替代FC技术构建SAN网络的确可以降低一定的成本。按32节点的例子计算,不考虑磁盘阵列部分,FC-SAN的硬件成本约为每端口$2000以上,采用iSCSI技术可以将这个数字降低到$1000以内。性能虽然受到一定影响,但仍会比目前的状况好很多。
然而,iSCSI技术的引入只能降低硬件产品,而对软件成本则没有任何影响。SAN架构文件共享软件的一般价格是每节点$5000~$7000,当硬件成本降低后,这部分软件成本占了SAN成本的大部分,存储系统的总体成本仍然明显高于计算节点的总和。
如此看来,无论采用哪种连接技术,只要试图将所有节点直接连接存储设备,共享软件的成本都是一个无法逾越的障碍,目前只能在其他方向上寻找解决办法。
方案五、多I/O节点间以PVFS实现负载均衡
让我们重新回到多I/O节点的架构下,来尝试解决多逻辑数据源带来的问题。并行文件系统(PVFS)似乎是个不错的选择。
从图中可以看到,以PVFS替代传统的NFS共享之后,多I/O节点被虚拟为一个单一数据源。各个前端计算节点可以面对这个单一的数据源进行读写操作,省去了复杂的管理。而PVFS架构中的管理服务器,将前端的所有I/O请求均衡负载到各个I/O节点,从而实现了系统I/O的自动负载均衡。
需要说明的是,PVFS本身有两个重要版本。其中PVFS1存在严重的单点故障问题,一旦管理服务器宕机,则整个系统都无法正常工作。PVFS2中针对这个隐患做了比较大的修正,不再单独设立管理服务器,而是各个运行IOD进程的节点都可以接管该功能,以此来改善系统的单点故障问题。
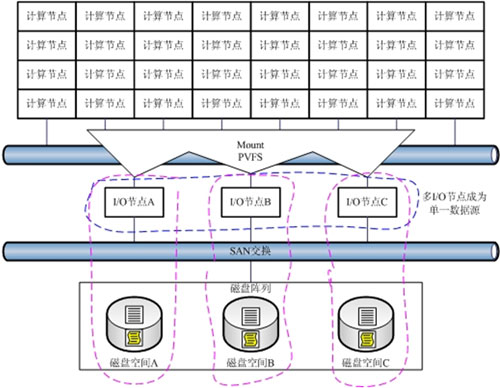
以PVFS构建的系统甚至不再需要SAN系统内文件共享,因为每个原始数据文件在I/O节点一级就被分割为一组小数据块,分散存储。
笔者对这一方案的顾忌在于技术的成熟度和服务保证。PVFS目前还不是由商业公司最终产品化的商品,而是基于GPL开放授权的一种开放技术。虽然免费获取该技术使整体系统成本进一步降低,但由于没有商业公司作为发布方,该技术的后续升级维护等一系列服务,都难以得到保证。
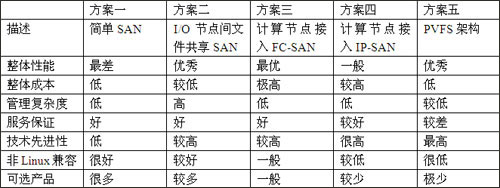
综上所述,笔者认为上述方案各有优势,但问题也同样明显。如果用户可以接受管理维护的复杂性,那么方案二似乎最为经济实惠。如果用户愿意接受基于GPL无原厂商服务支持的自由产品,并在短期内不考虑对非Linux集群系统的整合问题,则可以采用PVFS技术,即采用方案五。方案三虽然是所有方案中性能最好的,但其高昂的成本显然不是每一个用户都愿意接受的。
订阅《信息存储》杂志请 点击此处链接
