
存储在线专栏文章:之前,西瓜哥已经介绍了所有的高端存储产品,包括EMC Symmetrix、HDS VSP、IBM DS8000、IBM XIV、HP 3PAR和富士通DS8700等。今天起我们发表西瓜哥写的关于高端存储的技术原理,首先介绍下《高端存储快照实现原理解读》。
我个人认为对于高端存储来说,RIAD和快照是所有上层应用的基础。前面我在切西瓜刀法中说过,RAID和后面的分层和瘦分配关系很大,有一个好的RAID基础,如采用RAID 2.0块虚拟化技术,上层的动态分层和精简配置应用实现就会更加灵活和高效。同样,快照技术是灾备的基础,在LUN的复制、迁移、数据的本地备份、远程复制等等都需要用到快照技术的支持。因此,陈列的一切增值功能的底层基础都是RAID和快照。
存储快照技术:SNIA(StorageNetworking Industry Association)对快照(Snapshot)的定义是:关于指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的映像。快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。
讲快照实现原理之前,我们先给大家讲业界一个IT人士丁老师给我们讲的一个小故事。丁老师是我非常敬佩的产品销售人员,现在也在销售高端存储产品。一天,丁老师去和客户交流高端存储,在喷了半天讲完产品后,精彩的场景发生了:

笑话听罢,我们来讲讲高端存储快照实现的两种技术。
目前实现快照一般有两种方法,传统的存储快照技术COW(Copy-On-Write)和现在渐渐流行的基于写重定向的存储快照技术ROW(Redirect-On-Write)。
3PAR采用COW技术,我们用它举例来看一下实现原理:

大家看到,快照创建的以后,如果有对原卷的数据修改,修改的数据第一次被修改的时候就把数据COPY到快照卷里,如图中的D。只需要第一次修改的时候复制,因此有些书也把这种技术叫COFW(Copy-On-First-Write)。
而IBM XIV采用完全一种不同的技术ROW(Redirect-On-Write),我们来看一下XIV如何做的:
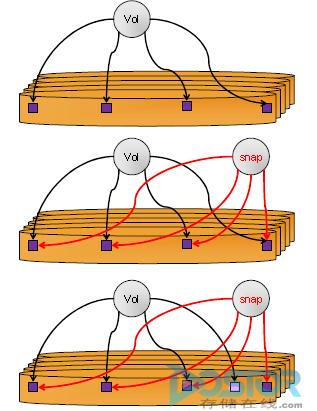
大家可以看到,ROW的不做复制,如果原卷有数据块被修改,重新写到一个新的地方好了,原卷的修改一下数据块指针,这个动作非常快,而快照卷不用做任何改变。
估计你马上会问我,那个技术好,我就知道为这么问,哈哈。
这又是一个艺术的问题,为啥这也是一个艺术问题,别急,听我说。
COW最大的问题是对写性能有影响。第一次修改原卷,需要复制数据,因此需要多一次读写的数据块迁移过程。这个就比较要命,应用需要等待时间比较长。但原卷数据的布局没有任何改变,因此对读性能没有任何影响。
ROW最大的问题是对读性能影响比较大。ROW写的时候性能基本没有损耗,只是修改指针,实现效率很高。但多次读写后,原卷的数据就分散到各个地方,对于连续读写的性能不如COW。
由于这两种实现机制不同,因此性能也不同,一般来说,ROW就像采用电子快门的照相机,拍照的速度快,每分钟得到的快照数就多;而COW就像采用机械快门的传统相机,快门的速度慢,系统支持的快照数一般都比较少。下表是我整理的各个厂商的高端存储性能,大家对比一下就知道差别了。
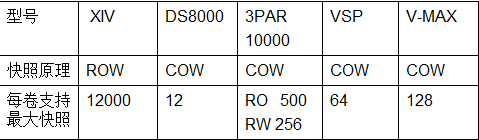
你可能会问,怎么没有HW HVS。我找了很多资料,都没有找到HVS的快照的资料,但我曾经看到一份华为中端存储的资料,说采用的也是COW技术,性能和3PAR一样256。因此,考虑到HVS也采用3PAR一样的RAID 2.0技术,因此,个人估计高端也一样或者比中端高一些。因此,大家理解的时候可以等同3PAR好了。
COW是最传统的实现方法,当然,现在COW也有很多改进,比如采用异步COW,现在的高端存储Cache都很大,如HVS最大支持3TB,因此可以先写到CACHE里面就回复主机写完了,这样应用就不用等待。等落盘的时候再触发快照复制的动作。还有,高端存储一般是数据库的应用,这些应用有一个特点,就是写少读多,一般是1:3到1:10。这个也比较容易理解,你银行存了一笔钱(写),但可能经常查询余额(读),就怕钱少了,哈哈。因此,COW这种方式在还是比较适合这种应用的。
但现在的备份技术发展也对快照提出了更高的要求,用户需要更快更多的快照来满足RTO/RPO的要求。人总是很贪婪的。IBM XIV由于底层采用非常小的1M大小的CHUNK,因此,本来数据就全部打散的非常均匀了,因此高端存储之父深知原来symmetrix的缺点,让XIV直接采用ROW技术,个人感觉是一个亮点。因为ROW的缺点是连续读写比较慢,但XIV的CHUNK比较小,如果是大数据库的读写,可以分散到很多个CHUNK里面,因此,读写性能应该影响不大。但3PAR的CHUNK是1G,太大了些,但设计的时候可以按照extend的粒度来打散,应该问题也不大。估计是10+年前,ROW的技术还没有流行吧。而HW,估计也是由于延续使用了中端存储的快照代码,有了历史的包袱,因此也没有采用ROW技术。当然XIV的ROW实现有一个问题,因为它的数据块是1M大小,上面不在细分了,因此如果比较小的I/O,如每次只写8K,那么8K需要写到新的地方,原来的数据也要COPY过来,ROW的优势就没有了。

从XIV的实现机制看,我感觉不太适合数据库应用,如ORACLE目前缺省的I/O块大小还是8K,这样ROW的优势就发挥不出来了。
个人认为,RAID 2.0和ROW是个绝配,虽然现在3PAR和HW在快照性能这块已经强于很多传统的高端存储厂商,但如果采用ROW将会给用户带来更大的价值。当然,我建议厂商实现的时候能克服XIV的缺陷,可以依据Grain的粒度来做最好,但这样可能管理的开销会变大,这又是一个艺术的问题,还是由厂商去回答吧,我这等屌丝也就是唧歪一下罢了。
总之,个人认为ROW应该是快照的发展方向,据说EMC的中端支持COW的同时也支持ROW了。
最近我重点看了IBM的DS8870的手册,800多页全英文的,看得我头都大了。前面介绍open system的时候有一个错误,这里纠正一下。
IBM说DS8000支持open systems and system z/os。从IBM的描述来看,如果z系列大机安装linux应该算open system。另外,DS8000的FC主机接口支持FCP和FICON协议,不需要单独的FICON口。我 原来以为DS8000分不同的口,发现物理层都一样,只是上面管理员要选择跑FCP协议还是FICON协议,但不能同时支持。因此3PAR和HW HVS这些只支持open system的高端存储,也可以支持大机了,只要和大机做一个兼容性的测试就可以了。以后,大机和open system并不能对立来看,这是我的理解。
上面我们说了快照实现的两种方法COW和ROW。虽然采用同样的技术,但每个厂商实现的细节都 不同,加上底层RAID技术不同,因此空间的利用率方面差距也比较大。大家看到,同样采用COW技术,3PAR和HW由于底层采用RAID 2.0技术,因此实现的效率更高,性能指标也高不少。因为RIAD 2.0具备完全块虚拟化能力,存储空间是在写时完成分配,而且具备非常灵活的扩展能力。
1、在创建快照的时候,不用为快照匹配资源池。按照COW原理,当快照需要额外空间保存数据时,RAID 2.0会自动从存储池中分配空闲空间给快照。
2、当存储池空闲存储空间不足时,只需要简单给存储池扩容即可。
3、因为业务LUN和快照共享存储池,所以不会出现资源池浪费或不足等存储空间管理问题。
但采用传统RAID的高端存储,如EMC V-MAX,在最新的Enginuity version 5876才加入TimeFinder VP Snap功能,只有针对thin LUN做快照具有上面的部分优点,一般LUN的快照系统需要保留20%-30%左右的预留快照空间才行。
快照另外一个非常重要的特性是快照一致性组(Consistency Group)。我们今天重点来介绍这个功能对于高端存储的意义。

这个功能就是支持多个LUN或者叫卷volume同时做快照,保证数据的一致性。我们举一个生活的照集体照的例子来说明这个这个功能的用处。
我的大情人在银行工作,她曾经告诉我,她们银行很NB,每次部门合影,别人一般只会喊“茄子”,她们都是这样喊的:
摄影师:大家别动,马上要拍照了。
摄影师:我们银行什么最多?
众人:钱!(啪,第一张快照)
摄影师:钱多怎么办?
众人:花!(啪,第二张快照)
摄影师:花完怎么办?
众人:抢!(啪,第三张快照)
你看,是否是很有气势。以后你们照合影都可以这么学,把银行改成你们部门就好了。不过现在银行银根缺紧,应该没这么牛气了吧。
为什么要大家统一喊“钱”、“花”、“抢”?意思这个口型类似“茄子”,说起来像笑的样子,关键是同时笑,这张集体照才完美。

看这样的毕业照多美,是吧。为什么一般集体照要多照几张,就是怕有些人脸长,笑容爬得慢,不同步。你看这个小伙就不老实,需要重拍。

快照一致性组就是解决这个问题。我说一个ORACLE数据库的例子,10多年前我还是一个认证的ORACLE DBA(当时中国认证的人很少,我们封闭学了一个月,考了5门课才拿到证书。据说当时如果直接技术移民加拿大都没有问题,和CCIE有一拼。不过现在好像 掉下个椰子都会砸着两,哎),我们建数据库的时候一般采用多个裸设备(LUN),不同的LUN用来放不同的数据。如果采用阵列的快照来做数据库的备份,必 须所有的LUN都是一个时间点的才行,这样数据库恢复的时候才能起来,否则数据库必须回滚到某一个一致的时间点,意味数据的丢失。比较完美的做法就是在主 机安装一个快照的agent,最好是多路径软件具备这个功能(据说华为已经整合在一起了),在高端存储要做快照的时候,对主机的快照agent说,别动, 要照相了。主机agent接受到摄影师的命令后,把ORACEL主机缓存的内容flush一下到陈列来,然后hold住,阵列也尽快把cache的内容 flush到硬盘里,ORACLE用到的所有硬盘一块喊”茄子“,摄像师一按快门,一幅完美的快照就产生了。
一致性组除了保证照相的时候一致性外,还有恢复的时候要一致性恢复。这块的实现的重要性就不如照相的时候重要,可以人工选择同一时间的LUN快照恢复就可以了。最重要的是照相的时候必须要一致,而且这个人工干不了。
高端存储手册里面的KiB,MiB,GiB是啥意思?
接下来随便聊一个我过去不太注意的小细节。也就是在我看使用的厂商手册里面,经常出现KiB,MiB,GiB这些术语,我详细里面有很多童鞋了解它的意思,我也相信很多童鞋不太了解。
这个原因只要是KiB,MiB,GiB是采用2进制来,而我们常见的KB,MB,GB都是采用10进制来表示的单位。
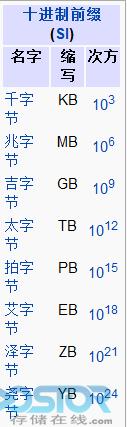
这是十进制的单位:
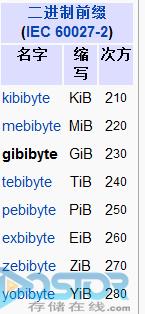
这是采用二进制的单位:
造成这种原因主要是计算机操作系统都是采用二进制来表示的,而一般硬盘厂商都喜欢采用十进制来表示容量(估计这样容量就可以大一些?),害得我们经常需要在这两种容量中算来算去。
在 购买硬盘之后,细心的人会发现,在操作系统当中硬盘的容量与官方标称的容量不符,都要少于标称容量,容量越大则这个差异越大。标称40GB的硬盘,在操作 系统中显示只有38GB;80GB的硬盘只有75GB;而120GB的硬盘则只有114GB。这并不是厂商或经销商以次充好欺骗消费者,而是硬盘厂商对容 量的计算方法和操作系统的计算方法有不同而造成的,不同的单位转换关系造成的。
众所周知,在计算机中是采用二进制,在电脑世界里,以2的次 方数为“批量”处理Byte会方便一些,整齐一些。每1024Byte为1KB,每1024KB为1MB,每1024MB为1GB,每1024GB为 1TB,而在国际单位制中TB、GB、MB、KB是“1000进制”的数,为此国际电工协会(IEC)拟定了"KiB"、“MiB”、“GiB"的二进制单位,专用来标示“1024进位”的数据大小;而 硬盘厂商在计算容量方面是以每1000为一进制的,每1000字节为1KB,每1000KB为1MB,每1000MB为1GB,每1000GB为1TB, 在操作系统中对容量的计算是以1024为进位的,并且并未改为"KiB"、“MiB”、“GiB"的二进制单位,这差异造成了硬盘容量“缩水”。
还有,硬盘需要分区和格式化,操作系统之间存在着差异,再加上安装操作系统时的复制文件的行为,硬盘会被占用更多空间,所以在操作系统中显示的硬盘容量和标称容量会存在差异,而硬盘的两类容量差值在5%-10%左右应该是正常的。
大家了解了这些知识后,希望以后看到带“i"的单位就知道是啥意思了,不要以为是厂商创造的新术语哦。
不过,我看到很多国产的产品手册,好像从来不区分这两个单位,因此,我感觉严谨性不够。比如,IBM DS8870的Extent大小,写得很清楚是1GiB,XIV的手册也很严谨,MB和MiB区别得很清楚。我们中国人需要学习这种严谨的写法(啊,又扔 臭鸡蛋,我错了,行吗,我前面的文章所有的单位都应该带i,除了表示硬盘容量的单位外。看来讲别人容易,自己改起来难啊)。
好的,今天我们先聊到这里。希望大家积极反馈你的意见和建议,微信扫描如下二维码,关注微信公众号“高端存储知识”,与作者微信互动。






