
存储在线专栏文章:今天,西瓜哥来谈谈高端存储的一股势力,RAID 2.0,最近被华为HVS搞得风生水起,神奇的让人摸不着头脑。我还是从一个高端存储的江湖说起吧。
据说很久很久以前(别扔臭鸡蛋,讲故事都是这样的…),L国王有个美丽的D公主(代表数据库DB),特别喜欢吃西瓜果盘(代表主机看到的LUN),饭量惊人,一次可以吃2个。D公主吃水果有一个懒习惯,就如泰国人一样,水果都是切成小块(Extend)后拼成果盘(LUN),用牙签吃。D公主还有一个小脾气,这个果盘如果有一小块是坏的,就整个果盘扔掉(代表数据丢失)。L国王特别宠爱D公主,找了EMC/IBM/HDS来做长工,专门负责做果盘。瓜地和宫殿有一段距离,他们每天都摘3个西瓜,2个用来吃,1个用来备份,万一那个瓜坏了就补上(代表RAID 5)。就这样,他们每天辛苦在宫殿和瓜地奔波,碰到坏瓜还得回去瓜地拿备瓜(重构),非常辛苦。D公主一天天长大了,饭量也越来越大,瓜也越来越大。但问题来了,每次碰到坏瓜,他们去搬备瓜需要10个小时,因为西瓜太沉了,路上走不快。D公主后来受不来了,让L国王把他们撤了,换成了3PAR和HW,3PAR和HW比较聪明,他们想,为什么我到宫殿再切瓜呢,我可以每个瓜切成20大块(Chunk),找20个人搬到宫殿后再切小块(Extend)后拼成果盘(LUN)不就可以了吗?到宫殿后如果发现瓜坏了,派人回来拿1小块换上不就可以了吗?这样需要搬的瓜只有原来的1/20,瓜轻了,路上可以跑,因此就算瓜坏了,半小时也就换回来了。D公主很满意,日子相安无事,直到有一天HW加班病倒了,而3PAR正好和HP谈恋爱请假了,无奈找了个年轻人叫XIV做临时监工,这家伙比较浪费,每次都挑4个瓜,在瓜地全部切成小块(Extend),找一群小孩直接送给宫殿。对于D公主当然好了,但每次也只能吃一半,另外一半就倒掉了,很是可惜。后来XIV由于长得漂亮,被IBM包养,这是后话。
好来,故事讲完了,大家知道RAID 2.0是怎么回事了吧?还扔臭鸡蛋,别,我来好好给大家讲一讲,刚才是讲故事呢。
大家知道,传统的RAID 5过程是这样的:
选几个硬盘—》做成RAID 5—》根据容量创建LUN—》映射给主机(为了方便,我们称这个为RAID 1.0吧)
话说当时主流的高端厂商,EMC/IBM/HDS全是这个方案。这种方式就是如果有盘坏了,只能这个磁盘组的硬盘参与重构。当时的硬盘一般都是几十G,而且全部是FC磁盘,问题并不严重。
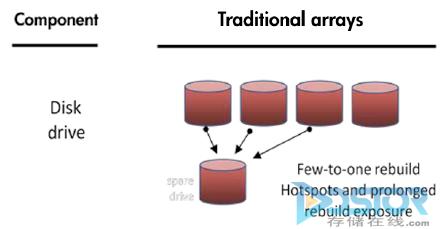
但是现在高端都引入了SATA磁盘,现在的西瓜,不对,是硬盘越来越大,因此,当一块硬盘坏了,只有这几块硬盘参与重构,重构的时间1TB需要10小时,如果是4TB的SATA盘,更加不可想象。
除了重构时间外,RAID 1.0还有一个大问题,就是性能。一个LUN的读写只能在一个磁盘组进行,让后面加入的SSD等新的介质发挥不了作用。但EMC/IBM/HDS在RAID 1.0已经积累了十几二十年,RAID又是所有软件的基础,他们轻易不敢重写代码。怎么办?
有了,可以把多个RAID组再组成一个池,再切一次(条带化):
选几个硬盘—》做成RAID 5—》选多个RAID 5组成一个池—》切分为相等的小块Extend—》选择Extend组成LUN,映射给主机(为了方便,我们称这个为RAID 1.5吧)
RAID 1.5很好地解决了性能的问题,因为一个LUN的读写同时跨越了很多的硬盘,而且这个LUN里面可以包含多个RAID组,也就可以有多种磁盘介质,可以做到自动分层存储。但是,由于RAID组还是基于硬盘的,这块硬盘坏了,只有一个RAID组的几个硬盘参与重构,因此重构速度依然和RAID 1.0一样。
3PAR和华为,历史包袱不大,因此采用块的虚拟化技术RAID 2.0来解决这个问题(3PAR内部叫FAST RAID)。RAID 2.0的思路就是,在做RAID前先切几刀,把西瓜(别打了,玩游戏玩多了不行吗),哦,是硬盘切成很多的相等大块(Chuck),然后以Chunk为单位来做RAID 5(形成CKG),然后再把CKG切成更小的小块(Extent),随机或者按照一定规则抽取很多的Extend组成LUN,映射给主机。
选所有个硬盘—》全部切成做大块Chuck—》以Chuck为单位做成RAID 5(CKG)—》把CKG切分为相等的小块Extend—》选择Extend组成LUN,映射给主机(这个就是RAID 2.0)

RAID 2.0由于RIAD的单位是大块Chunk,因此当一个硬盘故障,和这个硬盘相关的MINI RAID组(CKG)牵涉的硬盘都参与重组,同样的数据量,干活的人多了,肯定就快了。
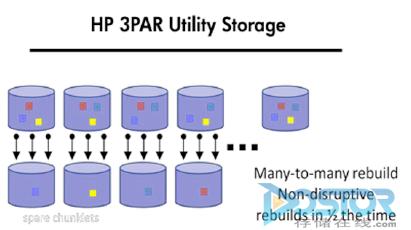
这就是RAID 2.0的本质。
一句话,如果基于硬盘来做RAID,就是RAID 1.0,如果基于硬盘的大块Chunk来做RAID,就是RAID 2.0。
至于IBM XIV,他不做RAID,把所有硬盘全部切为1MB大小,利用伪随机算法在不同的节点间保留2个拷贝(有点像RAID 10),因此硬盘故障恢复时间和性能和RAID 2.0是一样的,只是容量利用率最多只有50%,因此我们就称为"RAID 2.0-"把。至于华为为什么叫"RAID 2.0+",据说是基于RAID 2.0上有很多增值的功能,也不知道我的解释是否正确。当然,华为的RAID 2.0比3PAR的切的硬盘大块Chunk更小,因此灵活性和随机分布性更好些。
不知道我这么一说,大家了解Raid 2.0没有,了解了就转发给其他需要了解的人吧。
化腐朽为神奇,千言万语道不尽RAID 2.0
继续分享RAID 2.0细节的东西
块虚拟化和和LUN虚拟化:这两个术语大家可能听说过,一般来说,块虚拟化就是指RAID 2.0这样的技术,而LUN虚拟化就是指昨天我们说的传统厂商的RAID 1.5改良技术;
和上层应用的相关性:RAID技术其实和目前流行的自动分层存储和自动精简配置关系最大。我们来看一下HW HVS的RAID 2.0实现:
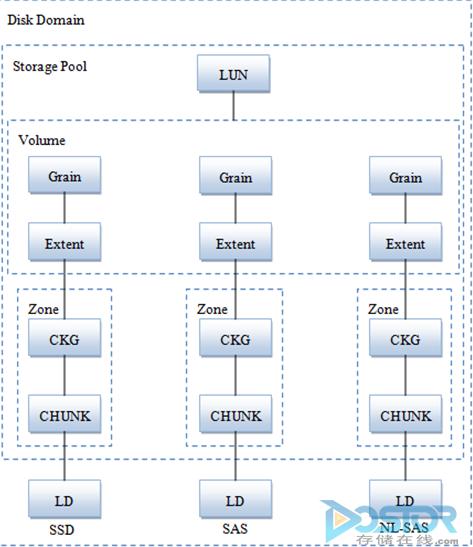
这是华为HVS实现的RAID 2.0全景图。大家发现没有,比我们昨天说的RAID 2.0又多切了一刀Grain(谷粒),这个我们不妨叫为微刀Grain。经过我对比分析总结,我发现RAID 2.0是硬盘拿到后,先用大刀切成CHUNK,HW HVS是64M,而3PAR 10000是1G,这个CHUNK就是构成RAID的基础;第二步就是用小刀切成小块EXTEND,HW HVS最小可以做到256K,而3PAR 10000只能做到128M,这个EXTEND是分层存储检测和迁移的单位;最后要切一刀就是用匕首切成Grain(谷粒一样细),HW HVS最小可以做到8K,而3PAR 10000是16K,这个是精简配置分配的单位。当然,不是每个LUN都需要做自动精简配置,因此如果是THICK LUN,也有叫FAT LUN,这一刀就不用挨了。从这个分析大家就可以看出,RAID 2.0确实是软件功能基础的基础,有了这个基础,上面的各种软件功能才能更加高效和快速。类似EMC/IBM/HDS在传统RAID基础上改进的RAID 1.5,虽然能够实现类似的功能,但在资源的利用率和效率、灵活性等等就差很多。有些功能就不能在THIN LUN上面做或者只能在THIN LUN上面做,THIN的时候必须预留空间,不能像RAID 2.0一样按需实时分配。
华为HVS对3PAR 10000的改进:这两天很多人问这个问题,我也说一下我的理解。华为居然敢叫RAID 2.0+,这个”+“可不是白加上去的。
首先是更细的粒度。上面的分析大家也看到了,华为的3刀切的粒度都比3PAR的小。CHUNK粒度小的好处是重构的数据量比较少,因为分配数据的时候可以知道那个CHUNK没有数据,不用重构,粒度小总数据量就少,比如只有64M数据的时候,华为只需要重构一个64M的CHUNK,但3PAR需要重构一个1G的CHUNK,数据差别还是比较大的。EXTEND粒度小在做热点数据监测和迁移的时候更加准确和高效,EXTEND过大可能把冷数据也迁移到SSD了,浪费容量。GRAIN粒度过大和过小都不合适,要和应用匹配效率最高。但大家知道ORACLE常用8K作为I/O单位,因此HW针对ORACLE这种场景应该比3PAR有更好的THIN效率和性能;
第二是华为的块标签技术,这个好像3PAR没有。华为RAID 2.0能够把盘切为片后,再把每个片打上一个标签(TAG),标签标明此片的容量、性能、成本等QoS属性,据此也就自然而然地使得HVS具备了面向不同业务、不同主机、不同应用提供不同SLA响应等级的能力。这才是RAID 2.0+中”+“的含义,这也是昨天HW的一位高人微信回复我才知道的。
从我的分享大家可能发现,RIAD 2.0还是很神奇的,特别是RAID 2.0+,学起来真是一个头八个大。希望我这两个的分享让你成为RAID 2.0高手。但我昨天总结的一句话还是对的:针对物理磁盘做RAID就是传统的RAID 1.0,针对硬盘切片CHUNK做RAID就是RAID 2.0。
觉得我写到不错就分享给其他人吧,让大家一块成为RAID 2.0高手。
总的来说,大家都认可区分RAID 2.0和RAID 1.0的区别,也就是说,基于硬盘切片CHUNK来创建RAID,这个就是RAID 2.0;基于物理硬盘来创建RAID组,这个就是传统的RAID。这个区别可能不是根本的,但可以帮助大家理解和辨别。
还有很多人混淆CHUNK,Extent,Grain的关系,不知道后面再切几刀有啥用。我分析3PAR和HW的实现,这里再给大家解释一下。
CHUNK是创建RAID的单位,它的主要作用就是用来创建RAID组(CKG)。CKG是有属性的,可以是RAID 5,RAID 1,RAID 6啦。我查阅各种文档,3PAR高端的CHUNK(它叫CHUNKLET)粒度是1GB,而中端的粒度是256MB(今天微信公众号“高端存储知识”的订阅量也是这个数,哈)。而HW HVS是64MB。3PAR没有看到说可以用户可以调整这个数值,HW的我不清楚。按照我的理解,这个CHUNK和应用关系不大,一般都无需调整(估计厂商要调整也是底层命令行来做,用户应该轻易不会去调整这个值的),就像切瓜器,每台阵列选好了一个切瓜器,规格就定下来了,所有的西瓜,哦不对是硬盘都切成一样的大小。当然,CHUNK也是硬盘失效重构的最小单位。

至于Extent,这个一个可变的值。也就是用户要在上面创建LUN,映射给某个主机。主机不同的应用可能有不同的要求,如ORACLE,这个块可以小些,如对视频数据,这个块可以大些。我们以后说的分层存储都是基于这个粒度,系统会检查每个Extent的I/O情况,然后把热数据迁移到SSD上,提升性能。

而Grain,这就不是必须的。如果这个LUN是Thin LUN,这一刀一般就是要挨的。挨着一刀就是和应用每次I/O平均分配的数据量有关,如果匹配,那么分配的效率是最高的。我详细分析了3PAR的文档,它系统后端设计的每个I/O是16K,因此,它理论上最小只能到16K了。
总结一下切西瓜刀法:切瓜器是随高端阵列赠送的,因此规格就固定了。但用户自己要想吃西瓜,估计还得拿把西瓜刀再切分成Extent,男同胞嘴大,喜欢切大块吃,向我这样的樱桃小口(喂,又别扔臭鸡蛋,再扔,我一口一个臭鸡蛋….),我喜欢切小一些。如果家有BB,比较瘦小(thin),那么还需要用匕首再切成颗粒状Grain,用牙签去喂他。当然,不同的BB要求而已不同。
哎,不说了,口水都流了一地了。我们再来回答大家的几个问题:
CHUNKExtentGrain的粒度越小越好吗?这个有技术门槛吗?
答:不是的。前面的分析也可以看到,后面两刀的粒度和应用密切相关,也是用户创建LUN的时候可以选择调整的,而CHUNK主要和RAID的管理和重构有关联,小的好处我昨天也提了。但我想事务总是有两面性的,太小,管理的开销必然大,我个人设想3PAR把高端的CHUNK定义得比中端大,就是由于高端要支持的硬盘更多,但3PAR目前高端的CPU还是老一代的CPU,中端的CPU已经更新了。还有就是3PAR的内存比HW HVS要少。这是我的猜想。这些粒度都没有太多的技术门槛,应该是每个厂商根据自己的硬件资源和软件的算法选择的一个最优值而已;
华为HVS真的比3PAR好?3PAR真的不支持每个块打标签吗?
答:这个昨天我收到最多鸡蛋的地方,大家都说我有倾向。老实说,我也不知道3PAR是否支持块打标签,但3PAR有元数据,也会记录这些块的属性,这是必须的,因为后面你要做RAID,要做分层,你必须知道这些块是SSD,还是SATA,在那个框里等等。只是HW做网络出身的,而且是后做的,是否把MPLS那套思路拿来,标签的属性更加丰富,说不定还可以嵌套,哈哈。总的来说,光从RAID 2.0的对比看,HW HVS毕竟是后来者,因此在粒度方面做得更灵活(至于实际的用处有多大,就是仁者见仁智者见智的事情了),而3PAR的优势应该在ASIC上,它的RAID用ASIC做的,理论上速度会更快(因此也叫Fast RAID),3PAR曾经和ORACLE以前做过一个测试,它的FAST RAID 5的性能可以做到基本和RAID 10持平(91%),3PAR经常用来告诉用户,用RAID 5就可以了,性能差不多,还省空间。但HW HVS虽然没有ASIC做RAID加速,但毕竟是后发布的产品,可以利用更新的平台和更快的CPU,因此整体上性能如何我暂时没有拿到对比结果。至于应用层的功能差别,以后我们再谈。
HVS到底是啥缩写?
有知情人士告诉我,HVS缩写是hyper virtual storage,不再是荣耀。很抱歉,百度上搜索hyper virtual storage,看不到和HVS相关的结果。再次说明华为的宣传是不够的。还有RAID 2.0+这个名字,感觉有点俗气,主要是搜索不好搜,这个小数点和+号一般都被搜索引擎过滤掉了,反正相关的文章也不多,如果叫UltraRAID,这种专业名称就比较容易宣传了。
RAID 2.0提升了性能和效率,可靠性如何?重构速度真的比传统RAID快20倍?
这个问题比较复杂,包括重构时间,我搜集了很多的数据和资料,明天打算作为一个专题和大家分享。也是,我一个LUN的数据你给我打散到100块盘上去了,万一坏了两块盘,我的数据不是完了吗?要知道RAID 2.0(包括fast RAID)如何解决这个问题,请看下一页分解。
通过上述大家应该基本掌握了RAID 2.0的原理。今天我们就来聊聊RAID 2.0的可靠性问题。
可靠性是一个非常复杂的问题,我不是这方面的专家,我只是从我收集的资料整理一下分享给大家。
可靠性和性能也经常是矛盾的,作为用户,有时需要平衡,这个是一个艺术问题,哈,你别不信,看完我今天的分析,估计你也有同感。
我们先从理论上分析一下RAID 2.0的可靠性。
大家知道,系统的可靠性=MTBF / ( MTBF + MTTR ) * 100%
RAID 2.0(3PAR叫FAST RAID),通过把数据分散到更多的磁盘,重构时间缩短,MTTR应该大大缩小了。但有一个问题,就是针对某一个LUN来说,由于数据分散到更多的盘,因此数据丢失的风险大大提高,即MTBF变大了。比如我采用传统的RAID 5(3+1),4个盘同时坏两个的概率是很小的,但如果用RAID 2.0, 假设这些数据分散到100个盘上,100个盘同时坏2个盘的概率大多了。虽然重构速度很快,但双盘失效的概率也提高了。那么到底重构减低的风险是否能够平衡掉双盘失效带来的风险呢?(什么,你一直想问这个问题,说明你入道了,很多童鞋是问不出这个问题来的。对RAID不了解的可以找度娘补习一下。老实说,我刚学习RAID 2.0的时候第一个问题就是这个,问了很多人,今天还未能完全解决)。
Markov模型是经典的可靠性预计模型,采用Markov模型可以根据系统当前状态及转移条件,来预计系统的可靠性指标。
马尔科夫是俄罗斯著名的数学家,计算公式复杂(我很佩服数学家,这么复杂的计算怎么算出来的),我想大家和我一样都是俗人,不会自己去算了,对吧。好,我从非官方渠道拿到一份可靠性技术的白皮书,在这里第一时间分享给大家计算结果:
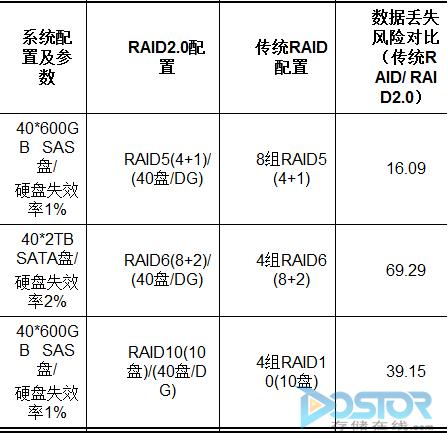
我来解读一下这个结果。这个结果说明,从理论上来说,RAID 2.0系统比RAID 1.0系统丢失数据的风险要小很多。但是别急,这个是对整个系统来说的。也就是说,针对这个高端阵列的管理员,他觉得不错,整个系统的可靠性提高了。但针对这个高端阵列的某个最终用户(比如ERP系统这个应用的IT人员帅锅小L)来说,好像不是这么回事。小L只关心ERP的数据,原来采用RAID 1.0,数据存放在5块盘上,同时坏两块盘的概率比地震都小,现在你把小L的数据均衡分布到100块盘上了,小L他晚上能睡着吗?
我也在寻求这个答案,谷歌和度娘都找不到答案。有可靠性专家和我说,其实,这种情况下RAID 2.0的可靠性并不比RAID 1.0有优势,对于传统RAID和RAID2.0,发生数据丢失的概率和丢失的数据量均近似有“随着系统盘数和硬盘容量的增加而成比例增大”(因此,性能够用就好,西瓜池也不要搞太大了)。虽然出现故障丢失的数据量要比RAID 1.0少,这对文件系统和归档来说问题不大,但对于数据库来说,丢一点都不行。因此,重构速度虽然快了,半小时搞定,但万一半小时内再坏第二块盘怎么办?用RAID 10或者RAID 6,或者做容灾。对头,可靠性要匹配你的需求,这个世界上没有完全可靠的东西,包括爱情,哈。
注意:上面的分析没有考虑RAID 1.0重构负载重可能导致的加快硬盘过劳死的风险,因为这个没法算。
RAID 10和RAID 6哪个更可靠?
大家知道,RAID 6最多可以坏任意两块盘数据不丢失,RAID 10可能坏一半的盘数据也可能不会丢失。那个的可靠性高?我估计80%以上的人认为是RAID 10可靠,如果你也是这么认为的,请马上回复微信告诉我,我看看我的判断对不对。其实我也和你们一样,我一直认为RAID 10更可靠,直到某天一个可靠性专家给我一份材料,IBM的红皮书,圣经啊。在IBM的一本DS5000的红皮书里,IBM经过计算,结论就是RAID 6的可靠性最高,其次才是RAID 10,最差是RAID 5。
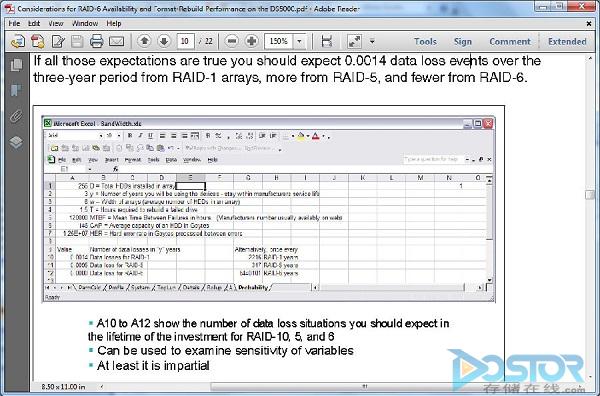
但你知道为什么现在无数的数据库都推荐用RAID 10了吗?因为性能。RAID 10的读写性能好很多。我说性能和可靠性的平衡是一个艺术,这回你相信了吧?
网上一直有传说说IBM XIV容易丢数据,我一直不信,现在想想,信了。为什么呢?它全部用SATA盘(现在它也叫SAS盘,其实是假的,是NL-SAS,也就是SAS接口,SATA的盘体),采用伪随机算法把数据以1M大小的CHUNK平均分布到所有的磁盘上。SATA盘的可靠性本来就比较差,你分布到180块盘,就算你重构速度块,同时坏2块盘必然会造成数据丢失(因为肯定有某1个CHUNK就在这两块盘上)。
对于RAID 2.0来说,已经好多了,RAID可以选择RAID 6。对于传统的高端阵列厂商IBM DS8000/EMC/HDS,他们由于历史原因,底层代码不能变,还是用传统的RAID,但为了实现自动分层和性能不变,必须要直接切第二刀Extend,对不对? 但在这种RAID 1.5的改良对可靠性更加是个噩梦,我们来欣赏一下IBM DS8000的红皮书里面的描述:
看到没有,由于DS8000的第二到必须在存储池里面切,而这个存储池底层是由多个传统的RAID组(RANK)组成,因此,如果一个RAID组失效,一个池的数据都丢失了。因此,你害怕丢失,请容灾。为了控制这个,我记得DS8000一个pool下最多放4个RAID组,而HDS直接建议用RAID 6。你看看,RAID 1.5限制是否很多,RAID 2.0真正从底层解决这些问题就好多了。再一次说明,可靠性和性能功能的平衡,真是一个艺术活。
最后,我们再谈一下重构时间。
先说一下我收集到的各个厂商宣传的数据:
HW:1TB重构时间30分钟,比传统RAID需要10个小时快20倍;
IBM XIV:1TB重构时间30分钟;
3PAR:在老的胶片上写的是重构速度快2倍;
我喜欢刨根问底,我们来分析一下:大家知道,7200RPM的SATA盘写的带宽大约115MB/s,因此,如果采用RAID 1.0,理论上需要2.5小时写1TB的数据。因为重构的时候只能写一个热备盘,这是瓶颈。但一般的系统都是有负载的,重构的优先级一般都是最低的,因为用户要保证业务的运行,因此,一般的重构时间基本都是理论时间的2-5倍。因此,如果RAID 2.0参与的盘很多,那个30分钟是可以达到的。而如果传统的RAID 1.0有较高的负载,重构需要10个小时也是正常的。因此,HW的宣传虽然稍微有点夸大,但基本属实。最关键就是RAID 2.0重构的时候对业务基本没有影响,因为没有热点盘。而RAID 1.0重构,对业务的影响是巨大的,反过来也影响到重构的速度。
为了验证我的想法,我再从互联网上找一下3PAR的用户发布的重构数据。
http://storagemojo.com/2010/02/27/does-raid-6-stops-working-in-2019/
这个用户分享了采用3PAR的fast RAID,SATA盘重构时间只化了4分钟(这个发挥了RAID 2.0的最大好处,只重构用过的CHUNK,而不用整盘重构,估计数据量比较小),而原来采用老的阵列,重构时间是24小时(SATA盘)和4-6小时(FC盘)。我也看到另外一个用户说说他采用3PAR的阵列,重构750GB的数据用了3个小时(业务负载特别重),不过对业务性能没有任何影响(怪不到3PAR宣称它是唯一一个可以在业务期间换盘的高端存储厂商,不过现在HW HVS把它的唯一去掉了,呵呵)。这说明重构时间也是一个艺术活,和数据量和业务负载,硬件特性等等都有关系。
最后分享一个我想了很长时间才想明白的事情,为什么RAID 2.0的重构的总数据量少?RAID 1.0也不是全盘重构的啊?(我估计你们肯定也想不明白)。后来在我上周苦练切西瓜刀法后恍然大悟,RAID 1.0能够感知的是LUN,也就是说,从一个RAID组里划分出LUN后,虽然主机还没有写任何东西,但是系统不知道,因此重构的时候都重构了,一般阵列初始化的时候,肯定把LUN都划了,因此相当于整盘重构了。但RAID 2.0划分为CHUNK,每个CHUNK上都有标签,没有分配的CHUNK,或者分配了没有被写过的CHUNK系统都清楚,当然只会重构有数据的CHUNK了,而不是整个LUN。
最后问大家一个问题,采用哪种RAID级别,RAID 2.0相比RAID 1.0重构时间提升最大?哈哈,RAID 10。假设不考虑做奇偶校验的时间,所有的RAID 1.0的重构时间是一样的,因为只能同时写1块热备盘,瓶颈在热备盘上。但采用RAID 2.0后,瓶颈不在写盘上了,RAID 5和RAID 6多了很多读数据的动作,而RAID 10就不用了,因此重构的速度提升是最明显的。
通过这些分析,大家估计得出的结论和我一样,RAID 2.0确实是一个颠覆性的技术,优点很多,而且有出色的性能和不逊于传统RAID的可靠性(带来业务的灵活性我们后面还会谈到),并且业界采用了十几年(3PAR 1999年就用了),应该是一个经过市场检验的RAID方法,应该也是高端存储以后的发展方向。
希望大家积极反馈你的意见和建议,微信扫描如下二维码,关注微信公众号“高端存储知识”,与作者微信互动。





