NVIDIAНшжњNetAppДцДЂДђдьДДаТМЦЫуГЁ
Pethuraj Perumal ЗЂБэгкЃК14Фъ04дТ14Ше 14:00 [злЪі] ДцДЂдкЯп
зїепЃКNVIDIA Corporation IT ДцДЂОРэЃЌPethuraj Perumal
NVIDIAШчКЮНшжњNetAppДцДЂЪЕЯжЙЄГЬМЦЫуШнСПЗБЖЃЌВЂМгПьДДаТВНЗЅвдПЊБйаТЪаГЁ
ВЛаИЕФДДаТвдМАНЋаТДІРэЦїЩшМЦПьЫйЭЦЯђЪаГЁЕФФмСІЪЧNVIDIAзпЯђГЩЙІЕФЭЦЖЏСІЃЌЭЌЪБвВЪЧОіЖЈNVIDIA ГЩАмЕФЙиМќЁЃзїЮЊЪгОѕМЦЫуСьгђЙЋШЯЕФСьЕМепЃЌЮвУЧСІЧѓВњЦЗЖрдЊЛЏВЂбИЫйДђШыаТЕФЪаГЁЁЃ
ЮвУЧЕФЭМаЮДІРэЕЅдЊЃЈGPUЃЉММЪѕе§дкЭЦЖЏзХвНСЦБЃНЁЁЂПЦММЁЂНЛЭЈЁЂгщРжЕШСьгђЕФЗЂеЙКЭНјВНЃЌЭЌЪБвВЮЊ NVIDIA ДјРДДѓСПаТЕФЛњгіЁЃЮвУЧЕФЙЄГЬМЦЫуГЁЕФадФмКЭПЩППадЮовЩЪЧNVIDIAТЪЯШЯђЪаГЁЭЦГіаТПюаОЦЌЩшМЦЁЂзюжедіМгДДЪеВЂЮЊЮвУЧЕФКЯзїЛяАщКЭПЭЛЇЬсЙЉМлжЕЕФЙиМќЁЃвЊЪЕЯжЮвУЧЕБЧАМАЮДРДЕФвЕЮёФПБъЃЌЮвУЧБиаыгЕгавЛИіИпадФмЕФДцДЂЦНЬЈЁЃ
жЇГжЪРНчМЖЕФбаЗЂ
NVIDIAЙЄГЬЪІЩшМЦСЫвЛЯЕСаЕФДІРэЦїЃЌДгЮЊжЧФмЪжЛњКЭЦНАхЕчФдЬсЙЉДІРэЖЏСІЕФЮЂаОЦЌЕНАќКЌ70вкИіОЇЬхЙмЕФОоаЭГЌМЖМЦЫуДІРэЦїЃЌвЛгІОуШЋЁЃЩшМЦКЭФЃФтетаЉаОЦЌЪЧвЛЯюШевцЗБжиЧвОпгаММЪѕЬєеНадЕФШЮЮёЁЃЮвУЧВЛЖЯЕиЩњГЩЮФМўЃЌЮФМўЪ§СПдНРДдНЖрЧвЮФМўдНРДдНДѓЁЃдкЙ§ШЅЕФОХИідТРяЃЌЮвУЧЕФЙЄГЬЪІДДНЈ24вкЗнЮФМў — ЯрЕБгкУПЬьНЋНќ1000ЭђЗнЮФМўЁЃЮвУЧвбЛ§РлГЌЙ§15 PBЕФЙЄГЬЪ§ОнЃЌЧвЪ§ОнСПМИКѕЪЧУПСНФъЗвЛБЖЁЃдкдЄЫуЮЌГжВЛБфЖјашЧѓШДГжајдіГЄЕФЧщПіЯТЃЌвЊгІЖдетбљЕФЪ§ОндіГЄЫЎЦНМЋОпЬєеНЁЃ
ЮвУЧВЛЯЃЭћВњЦЗЙЄГЬЭХЖгдкВтЪдЩшМЦЕФЭЌЪБЛЙвЊЗжЩёШЅПМТЧДцДЂЮЪЬтЃЌЮвУЧЕБШЛвВВЛЯЃЭћДцДЂГЩЮЊбаЗЂ ЃЈR&DЃЉ ЙЄзїСїГЬжаЕФЦПОБЁЃдкШЮКЮЧщПіЯТЃЌЮвУЧЕФЕчзгЩшМЦздЖЏЛЏЃЈEDAЃЉЙЄзїСїЖМВЛФмБЛбгЮѓЛђжаЖЯЁЃМЦЫузївЕвЛЕЉЭЃжЙЃЌОЭБиаыДгЭЗПЊЪМжиаТдЫааЃЌПЩФмЛсгАЯьећИіВтЪджмЦкВЂЭЦГйЩЯЪаЪБМфЁЃЫљавЕФЪЧЃЌЮвУЧЛљгкNetApp®ДцДЂЕФМЦЫуЙЄГЇФмНєИњЮвУЧЪ§ЧЇУћЙЄГЬЪІЕФДДаТВНЗЅЃЌАяжњЫћУЧПьЫйПЩППЕиЭъГЩаОЦЌЩшМЦЁЂФЃФтКЭТпМбщжЄЁЃ
ЮЊЪЙЮвУЧЙЄГЬЪІЕФДДаТЙЄзїВЛГіЯжжаЖЯЛђбгЮѓЃЌITБиаыЮЊЫћУЧЬсЙЉОпгазюИпадФмЕФПЩгУДцДЂЦНЬЈЃЌзЈУХгУРДЮЊЮФМўЧ§ЖЏЪНI/OУмМЏаЭЙЄГЬЙЄзїСїЬсЙЉ“днДцПеМф”КЭЪ§ОнОэЁЃЫцзХЪ§ОнЕФдіГЄЃЌЮвУЧЭХЖгЕФжївЊФПБъжЎвЛЪЧзюДѓЯоЖШЕиЬсИп“CPUЪБМфгыЪЕМЪЪБМф”ЕФБШТЪЃЌЦфжаЪЕМЪЪБМфБэЪОДІРэМЦЫузївЕЫљашЕФзмЪБМфЃЌЖј CPUЪБМфМЦЫуЕФЪЧCPUжїЖЏДІРэШЮЮёЫљЛЈЕФЪБМфЁЃБШТЪдНИпЃЌЮвУЧМЦЫуЙЄГЇЕФаЇТЪОЭдНИпЃЛВЛЙ§ЃЌЬсИпДЫБШТЪашвЊвЛИіI/OЫйЖШМЋПьЕФДцДЂЦНЬЈЁЃCPUЕШД§ДцДЂЯьгІЫљЛЈЗбЕФЪБМфЪєгкПеЯаЪБМфЃЌЛсНЕЕЭЮвУЧЕФећЬхаЇТЪЁЃ
ЖдДцДЂВуЕФММЪѕвЊЧѓ
МИФъЧАЃЌЮвУЧдјГЂЪдЪЙгУЦфЫћЙЉгІЩЬЕФДцДЂММЪѕЃЌМДНЋЫљгаДХХЬГЪДјзДЗжВМЕНвЛИіИќДѓЕФеѓСажаШЅЃЌжТЪЙЮвУЧдтгіСЫвдЯТШ§ИіЮЪЬтЃК
ЯЕЭГЮоЗЈЬсЙЉЮвУЧЫљашЕФЯпададФмЁЃ
аЁЮФМўЫцЛњI/OГЩЮЊЦПОБЁЃ
ЮШЖЈадКЭПЩППадВЛЙЛЁЃДцДЂПижЦЦїЙЪеЯПЩФмЛсЕМжТбгГйЩЯЪаЃЛЙЄзїСїжаЕФЫљгаЛюЖЏзївЕПЩФмвЊДгЭЗПЊЪМдйРДвЛБщЁЃ
дкЦРЙРЮЪЬтНтОіЗНЗЈЕФЭЌЪБЃЌЬцЛЛЕБЧАЕФЯЕЭГГЩЮЊУїжЧжЎОйЁЃМјгквдЯТдвђЃЌЮвУЧЕФЭХЖгбЁдёСЫNetAppзїЮЊЮвУЧбаЗЂМЦЫуВйзїЕФжЇГжКѓЖмЃК
адФмЁЃЮвУЧЕФбаЗЂМЦЫуВйзїОпгаКмИпЕФВЂЗЂадЃЌЭЌЪБЛсгаГЌЙ§5000ИіМЦЫуНкЕуЗУЮЪДцДЂЃЌвђДЫадФмИпЕЭдкКмДѓГЬЖШЩЯШЁОігкДцДЂПижЦЦїЁЃЮвУЧЪМжеЯЃЭћДцДЂПижЦЦїФмгУЩЯзюПьЕФДІРэЦїЃЌетбљДцДЂПижЦЦїОЭФмвдзюЖрЕФВЂааЭјТчЯпГЬРДДІРэI/OЧыЧѓЁЃЮвУЧЛЙашвЊИпаЇДІРэаЁЮФМўЫцЛњI/OВйзїЕФФмСІЃЌвђЮЊетвВЪЧгАЯьЮвУЧЙЄзїИКдиадФмЕФжївЊОіЖЈвђЫиЁЃ
ПЩРЉеЙадЁЃNetAppПЩШУЮвУЧвдФЃПщЛЏЗНЪНЬэМгИќЖрЕФПижЦЦїЃЌДгЖјдкЪ§ОндіГЄЕФЭЌЪБШЗБЃзюМбадФмЁЃЮвУЧПЩвдЫЎЦНРЉеЙДцДЂЃЌетжжФЃЪНЖдЮвУЧРДЫЕЗЧГЃгааЇЁЃЭЌЪБЛЙЛсНЕЕЭЗчЯеЃЌвђЮЊЮвУЧВЛЛсЪмЕЅЕуЙЪеЯЕФгАЯьЁЃ
ПЩППадЁЃЮвУЧашвЊРрЫЦNetApp Data ONTAPетбљЕФГЩЪьПЩППЕФЪ§ОнЙмРэЦНЬЈЁЃЪЙгУИпПЩгУадЖджаЕФNetAppДцДЂПижЦЦїМЏШКПЩЪЙЮвУЧдкГіЯжгВМўЙЪеЯЕФЧщПіЯТЬсЙЉЮоЗьЙЪеЯзЊвЦВЂжДааИќаТЃЌЖјВЛЛсЖдМЦЫуЙЄГЇжае§дкдЫааЕФзївЕдьГЩШЮКЮжаЖЯЁЃМДЪЙФГИігђЗЂЩњЙЪеЯЃЌвВВЛЛсШУећИіМЏШКБРРЃЁЃ
аЇТЪЁЃЮвУЧВЛЖЯХЌСІПижЦећЬхФмКФКЭгВМўеМгУПеМфЃЌВЂОЁПЩФмЕиЬсИпУмЖШЁЃNetAppЬсЙЉаэЖрФмЪЕЯжаЇТЪзюДѓЛЏЕФММЪѕЃЌАќРЈгыеМгУзюЩйДцДЂПеМфЕФЪБМфЕу SnapshotИББОБЃГжЪ§ОнвЛжТадЕФЙІФмЁЃФЌШЯЧщПіЯТЃЌNetAppОэвбОЙ§ОЋМђХфжУЃЌФмМѕЩйГѕЪМДцДЂПеМфЪЙгУСПЁЃ
ОЋМђадЁЃФмЗёСщЛюЪЙгУЭјТчЮФМўЯЕЭГЃЈNFSЃЉКЭЭЈгУ InternetЮФМўЯЕЭГЃЈCIFSЃЉПьЫйХфжУДцДЂВЂЖдЙЄГЬЮФМўЬсЙЉЙВЯэЗУЮЪЗЧГЃживЊЁЃЦОНшNetAppЭГвЛДцДЂМмЙЙжаЕФЖравщжЇГжЃЌЮвУЧПЩвдЪЙгУвдЯТСНжжавщЃЈМћЭМ 1ЃЉЁЃ
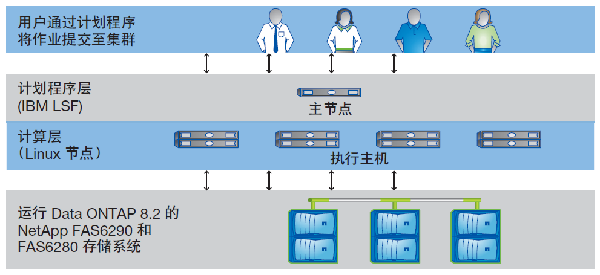
ЭМ 1ЃЉNVIDIAЙЄГЬМЦЫуЙЄГЇВЩгУNetApp Data ONTAP 8.2ЁЃЭЈЙ§NFSКЭCIFSЗУЮЪЯрЭЌЕФЮФМўЯЕЭГЪБЃЌData ONTAPЭъШЋБЃГжСЫЪ§ОнЕФЭъећадЁЃ
ШчКЮНшжњNetAppДцДЂЪЙШнСПЗБЖ
НижС2012ФъЃЌвдNetAppДцДЂЮЊКѓЖмЃЌЮвУЧЕФЙЄГЬМЦЫуЛљДЁМмЙЙЛљБОФмЙЛТњзуашЧѓЁЃЮЊСЫБЃжЄДДаТЙЄзїгаЬѕВЛЮЩЃЌЮвУЧашвЊжЇГжИќЖрЕФВЂЗЂЙЄзїСїВЂЬсИпМЦЫузївЕЕФадФмЁЃ
ЮЊНтОіетвЛФбЬтЃЌЮвУЧВПЪ№СЫВЩгУжЧФмЛКДцММЪѕЕФNetApp FAS6280КЭFAS6290ДцДЂЯЕЭГвдЬсИпЭЬЭТСПЃЌВЂНЋЖрИіЖРСЂЯЕЭГећКЯЮЊИпПЩгУадЖдЁЃЭЌЪБЃЌЮвУЧЩ§МЖЕНСЫData ONTAPЕФИќаТАцБОЃЌЫќЬсЙЉСЫИќЖрЕФВЂааЭјТчЯпГЬРДДІРэI/OЧыЧѓЃЌЖјЧвЪЙCPUдкЫљгаКЫаФМфЕФРћгУТЪИќМгЦНКтЁЃДЫЭтЃЌЮвУЧЛЙгыNetAppЙЄГЬВПеЙПЊУмЧаКЯзїЃЌСЊЪжНјааЛљзМВтЪдВЂеыЖдЮвУЧЬиЖЈЕФEDAЙЄОпНјааДцДЂгХЛЏЃЌетВЂЮДИФБфЛђгАЯьЮвУЧЙЄГЬЭХЖгЕФЕзВуЙЄзїСїЁЃ
НшжњЦфЫћNetApp ДцДЂЯЕЭГЁЂЛКДцКЭгХЛЏВйзїЃЌзюжеЮвУЧМЦЫуЙЄГЇЕФећЬхДІРэаЇТЪЬсИпСЫвЛБЖЖрЃЌУПЬьЕФМЦЫузївЕСПДг200ЭђдіМгЕН450ЭђЁЃЮвУЧПЩвддкШЮКЮжИЖЈЪБМфЭЌЪБжДаа60,000ЯюМЦЫузївЕЁЃCPUЪБМфгыЪЕМЪЪБМфЕФећЬхБШТЪвВгаЫљЬсЩ§ — ЮвУЧЗЂЯжЪЕМЪБрвыадФмЬсИпЖрДя 19% ЧвФЃФтдЫааДЮЪ§діМгЖрДя25%ЁЃ
ИпаЇДцДЂЮЊВњЦЗЩЯЪаЬсЫй
NetApp ММЪѕЖдЮвУЧМЦЫуЙЄГЇЕФадФмЁЂаЇТЪКЭПЩППадЗЂЛгзХживЊзїгУЃЌгажњгкЮвУЧЪЙгУЯрЭЌЕФДцДЂЦНЬЈгХЛЏЫГађЙЄзїИКдиКЭЫцЛњЙЄзїИКдиЃЌ НјЖјМгПьЩЯЪаЫйЖШЁЃ
ЬсЩ§аЁЮФМўЫцЛњ I/O адФм
NetAppФмГіЩЋЕиДІРэЭЈЙ§NFSДЋШыЕФI/OЧыЧѓЃЌвЛВПЗжЪЧвђЮЊ WAFLЃЈШЮвтЮЛжУаДШыЮФМўВМОжЃЉЃЌетЪЧзюСюЮвгЁЯѓЩюПЬЕФNetAppЙІФмжЎвЛЁЃWAFLЪЙгУСйЪБЪ§ОнВМОжЭЌЪБаДШыдЊЪ§ОнКЭгУЛЇЪ§ОнЃЌвдОЁСПМѕЩйНЋЪ§ОнЬсНЛЕНДцДЂЫљашЕФДХХЬВйзїДЮЪ§ЃЌЖјВЛЪЧНЋЪ§ОнКЭдЊЪ§ОнДцДЂЕНДХХЬЩЯЕФдЄЖЈЮЛжУЁЃНЋЗЧГЃаЁЕФЮФМўЃЈаЁгк64зжНкЃЉДцДЂЕНЮФМўЯЕЭГФкЕФЫїв§НкЕуЪ§ОнНсЙЙжаЃЌЖјЗЧДХХЬПщжаЃЛвђДЫЃЌЮоашЗУЮЪДХХЬЃЈЪЁЯТСЫВщевЪБМфЃЉЃЌЬсЩ§СЫадФмЁЃ
НшжњжЧФмЛКДцНкЪЁПеМфКЭФмКФЕФЭЌЪБгХЛЏЖСШЁадФм
ЮвУЧНшжњNetApp Flash CacheРДЬсЩ§ОіЖЈзХДѓВПЗжЙЄзїИКдиЫйЖШЕФЖСШЁадФмЁЃЭЈЙ§дкСЌНгЕНПижЦЦїЕФ PCIeПЈЩЯЛКДцзюНќЖСШЁЕФЪ§ОнКЭдЊЪ§ОнЃЌFlash CacheдкPCI змЯпжаГфЕБWAFLРЉеЙЛКГхЧјЃЌДгЖјАяжњЮвУЧШнФЩЗЧГЃДѓЕФЪ§ОнМЏЁЃЮвУЧгы NetApp НєУмКЯзїЃЌЙВЭЌШЗЖЈЙЄзїИКдиЫљашЕФFlash CacheЪ§СПВЂОіЖЈЪЙгУ512 GBКЭ1 TB PCIeПЈЁЃетбљвЛРДЃЌЛКДцЪЙгУТЪОЭЪМжеИпгк90%ЁЃ
НшжњFlash CacheЃЌЮвУЧПЩвдЪЙгУЛьКЯДцДЂФЃЪНЃЌвдБузюДѓЯоЖШЕиМѕЩйДцДЂеМгУПеМфВЂПижЦГЩБОЁЃдкИУФЃЪНЯТЃЌЮвУЧЪЙгУСЫОпгаНЯИпУмЖШЕФИпадФмДЎааСЌНгSCSIЃЈSASЃЉЧ§ЖЏЦїКЭГЩБОНЯЕЭЕФДЎаа ATAЃЈSATAЃЉЧ§ЖЏЦїЁЃШєВЛВЩгУFlash CacheЃЌвЊДяЕНЮвУЧФПЧАЕФадФмЫЎЦНЃЌЮвУЧашвЊЕФДХХЬМмЪ§СПвдМАЯргІЕФФмКФКЭЩЂШШзЪдДПЩФмвЊдіМгШ§БЖЖрЃЛЖјЧвЃЌШєВЛВЩгУ Flash CacheЃЌЮвУЧПЩФмЮоЗЈдкЯжгаЛЗОГЯТЪЙгУИпШнСП SATA ДХХЬЃЌЧвКмФбРЉеЙМЦЫуЙЄГЇЕФШнСПЁЃЮвУЧЕФЪ§ОнжааФПЩФмвбВЛПАИКжиЁЃЪТЪЕЩЯЃЌдкЮвУЧЖдМЦЫуЙЄГЇНјааШнСПРЉеЙжЎКѓЃЌНшжњаТNetAppДцДЂЯЕЭГЕФФмаЇЃЌЮвУЧвбДгЕчСІЙЋЫОгЎЕУСЫ200,000УРдЊЕФЗЕРћЁЃ
НЕЕЭЗчЯеЃЌЭЌЪББЃГжЪ§ОнвЛжТад
NetAppДцДЂСэвЛИіМЋОпЮќв§СІЕФЙІФмЪЧSnapshotИББОЃЌЫќУЧЪЧЛюЖЏЮФМўЯЕЭГЛљгкжИеыЕФжЛЖСИББОЁЃWAFLРћгУаДЪБИДжЦММЪѕзюДѓЯоЖШЕиМѕЩйSnapshotИББОеМгУЕФДХХЬПеМфЃЌетбљЮвУЧОЭПЩвддкБЃСєЪ§ОнМЏЕФЪБМфЕуИББОЪБЃЌМШЮоашеМгУДцДЂПеМфЃЌгжВЛЛсгАЯьадФмЁЃSnapshotИББОПЩАяжњЮвУЧБЃГжЪ§ОнвЛжТадЃЌетдкЙЄГЬЛЗОГжажСЙиживЊЃЌЖјЧвгажњгкБмУтЪ§ОнЖЊЪЇЕФЗчЯеЁЃМЦЫузївЕЭъГЩКѓЃЌЮвУЧПЩвдЪЙгУ Snapshot ИББОСйЪББЃЛЄЮоашБЃСєЕФЪ§ОнЃЌБмУтвђжиИДДцДЂЖјВњЩњЗбгУЃЌетвЛЗНЗЈЪЎЗжМђБуЁЃSnapshot ИББОПЩвддкЮвУЧетжжЮФМўЪ§СПОоДѓЕФЛЗОГжаЬсЙЉПьЫйЛжИДЃЌжЛашЗзЊЮФМўЯЕЭГжИеыМДПЩ — ШчЙћЪЕбщЙ§ГЬжаГіДэЃЌЮвУЧПЩвдЪЙгУSnapshotИББОжаЕФЪ§ОнИББОПьЫйЛжИДЕНвбжЊзДЬЌЁЃNVIDIAФПЧАЪЙгУNetApp SnapVault®НјааБИЗнВЂЪЙгУ NetApp SnapMirrorНЋЪ§ОнИДжЦЕНЮЛгкШјПЫРУХЭаЕФджФбЛжИДеОЕуЁЃ
ЮвУЧЛЙЪЙгУ NetApp жиИДЪ§ОнЩОГ§РДЯћГ§ФГаЉОэФкЕФШпгрЪ§ОнПщЃЌВЂвђДЫЖјЛёвцЁЃжиИДЪ§ОнЩОГ§ММЪѕЛсевЕНЯрЭЌЕФЪ§ОнПщЃЌВЂвдв§гУЕЅИіЙВЯэЪ§ОнПщЕФЗНЪННЋЦфЬцЛЛЁЃетжжЗНЗЈЬиБ№ЪЪКЯЮвУЧБЃСєСЫЖрИіИББОЕФ Perforce ШэМўХфжУЙмРэЯЕЭГЃЌвђЮЊетаЉИББОжагаДѓСПЕФжиИДЪ§ОнЁЃЮвУЧНЋетаЉОэЕФШнСПвЊЧѓНЕЕЭСЫ 30%ЁЃ
гУИќЩйЕФШЫЪжЙмРэИќЖрЕФДцДЂ
ОЁЙмЮвУЧМЦЫуЙЄГЇЕФДцДЂШнСПвбДѓЗљЬсЩ§ЃЌЕЋЮвУЧЮДЙЭгУИќЖрЕФЛљДЁМмЙЙШЫдБЃЌЧвЮвУЧЕФдЄЫугыЭљФъГжЦНЁЃЪЕМЪЩЯЃЌЩйвЛИіШЋжАдБЙЄЮвУЧвВПЩвде§ГЃдЫааЁЃе§ЪЧвђЮЊNetAppШУЮвУЧФмЙЛЧсЫЩМђЕЅЕиЙмРэ15 PBЕФЪ§ОнеМгУПеМфЃЌВХШУетГЩЮЊПЩФмЁЃ
НшжњNetApp OnCommand Unified ManagerЙмРэШэМўЃЌЮвУЧПЩвдПьЫйСЫНтадФмжИБъКЭРћгУТЪЭГМЦаХЯЂЁЃЮЊСЫОЁдчЗЂЯжДцДЂЛљДЁМмЙЙжаЕФЮЪЬтвдУтЖдМЦЫузївЕдьГЩгАЯьЃЌЮвУЧбЁдёЪЙгУNetApp AutoSupportЃЌЫќПЩдкГіЯжДХХЬЙЪеЯЛђЦфЫћЧБдкЮЪЬтЪБбИЫйзіГіЯьгІВЂЯђЮвУЧЗЂГіОЏБЈЁЃ
вЕЮёгАЯьЃКМгПьNVIDIAМАПЭЛЇЕФЩЯЪаЫйЖШ
ЖдNVIDIAЖјбдЃЌМЦЫуЙЄГЇЕФаЇТЪЬсЩ§25%втЮЖзХПЩвддкИќЖЬЕФЪБМфФкВтЪдЁЂбщжЄаОЦЌЩшМЦВЂНЋЦфЭЦЯђЪаГЁЁЃNetAppАяжњЮвУЧЬсЩ§СЫCPUЪБМфгыЪЕМЪЪБМфЕФБШТЪЃЌетЖдЮвУЧЕФЩЯЪаЪБМфжСЙиживЊЁЃЫцзХадФмКЭШнСПЕФЬсЩ§ЃЌЮвУЧУПЬьПЩвджЇГжЕФзївЕСПНЋЪЧжЎЧАЕФСНБЖЖрЃЌЗДЙ§РДетНЋДйЪЙЮвУЧЭЦГіИќЖрЕФЩшМЦЁЃЮвУЧВЛдйЪмЭЃЛњЪБМфЕФгАЯьЃЌНшжњNetAppЯЕЭГЃЌЮвУЧЪЕЯжСЫИпгк99.99%ЕФПЩгУадЁЃЮвУЧВЛдйЙизЂДцДЂе§ГЃдЫааЪБМфЃЌвђЮЊЮвУЧЕФNetApp ДцДЂЫцЪБПЩЙЉЙЄГЬЪІУЧЪЙгУЁЃ
ЫѕЖЬЗЂВМжмЦквВНЋЮЊЮвУЧЕФПЭЛЇДјРДОоДѓЕФЩЬвЕМлжЕЃЌетВЛНіФмЙЛЙЎЙЬЮвУЧЕФеНТдвЕЮёКЯзїЛяАщЕиЮЛЃЌЖјЧвгажњгкПЭЛЇЭЦГіЛљгкNVIDIAММЪѕЕФЭЛЦЦадВњЦЗЁЃ
ЮДРДЙцЛЎ
НшжњNetApp Flash CacheКЭЦфЫћДцДЂаЇТЪЃЌNVIDIAЪЕЯжСЫR&DМЦЫузЊаЭВЂГЩЙІДђдьСЫвЛИіжЇГжВЛЖЯДДаТЕФМЦЫуЙЄГЇЁЃдкРЉДѓКЭЭъЩЦМЦЫуЙЄГЇЕФЙ§ГЬжаЃЌЮвУЧНЋМЬајаХРЕгыNetAppжЎМфЕФКЯзїЃЌЮвУЧЛЙЦкЭћНшжњаТвЛДњNetApp FAS6000ДцДЂЯЕЭГЬсИпадФмВЂдкФмКФКЭЩЂШШЗНУцЛёЕУИќЖргХЪЦЁЃЭЌЪБЃЌЮвУЧЛЙНЋРЉДѓNetAppДцДЂдкЦфЫћвЕЮёСьгђЕФгІгУЃЌАќРЈЙЋЫОITКЭЮвУЧЕФVMware vSphere®ащФтЗўЮёЦїЛЗОГЁЃ
дкВЛОУЕФНЋРДЃЌЮвУЧМЦЛЎНЋМЦЫуЙЄГЇЧЈвЦЕНNetAppМЏШКФЃЪНData ONTAPВйзїЯЕЭГЃЌФПЧАЮвУЧе§ДІгкВтЪдНзЖЮЁЃЭЈЙ§НЋЮвУЧЯжгаЕФNetAppДцДЂЯЕЭГКЯВЂЕНМЏШКФЃЪНData ONTAPЯТЕФЕЅИіШЋОжУќУћПеМфЃЌЮвУЧНЋДгЮоЗьКсЯђРЉеЙЁЂМђвзИКдиЦНКтвдМАећИіЩњУќжмЦкФкБЃГжСЊЛњЕФаОЦЌЩшМЦЪ§ОнжаЛёвцЁЃ



