Cloudera 将Spark加入Hadoop
袁绍龙 发表于:14年02月07日 10:35 [原创] 存储在线
Spark作为一个通用的并行计算框架,已经成为继Hadoop之后又一大热门开元项目,逐渐获得很多企业的支持。近日,Cloudera正式宣布开始商业支持Apache Spark 机器学习和数据流处理环境。
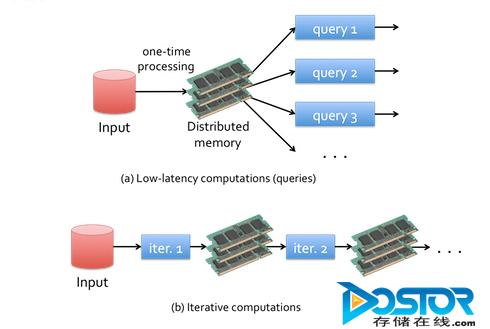
Spark内存计算框架适合各种迭代算法和交互式数据分析,能够提升大数据处理的实时性和准确性。而MapReduce处理框架则擅长复杂的批处理操作、登陆过滤、ETL(数据抽取、转换、加载)、网页索引等应用,MapReduce在低延迟业务上一直被人所诟病。
图一:Spark内存计算框架。
“Spark记录着数据产生的每一个操作,能够可靠地将这些数据存储在内存之中,这使得它非常适用于第掩饰的计算和有效的迭代算法。”Cloudera表示。
据悉,Cloudera Enterprise Data Hub版本提供多种先进的组件的无限支持,如交互式SQL分析的Impala、交互式搜索、导航数据管理以及Hbase NoSQL。Enterprise Flex版本则提供可选择组件版本,Enterprise Basic版本则是仅仅提供Hadoop基础核心组件。
根据Cloudera介绍,Cloudera将会在两个版本中安装支持Spark组件。用户可以利用它作为Enterprise Flex版本中一个可选组件,或者作为Enterprise Data Hub版本中包含的组件。

图二:Spark On YARN
据悉,该产品采用了Spark 0.9.0,Spark独立模式已经在Cloudera Enterprise Data Hub4.4.0中测试过。在不久的将来,Cloudera表示Enterprise 5.0和YARN中也将支持Spark。



