ЧГЮіI/OДІРэЙ§ГЬгыДцДЂадФмЕФЙиЯЕ
ЗуСж ЗЂБэгкЃК13Фъ10дТ29Ше 10:28 [дДД] ДцДЂдкЯп
“адФм”етИіДЪПЩвдЫЕАщЫцзХећИіITаавЕЕФЗЂеЙЃЌУПДЮаТЕФММЪѕГіЯжЃЌДггВМўЕНШэМўДѓЖрЪ§ЧщПіЯТЖМЮЇШЦзХадФмЬсЩ§ЖјеЙПЊЁЃ“ФІЖћЖЈРэ”жИГіCPUЕФДІРэЫйЖШУП18ИідТЛсЗвЛЗЌЃЌЕЋЪЧНјШы21ЪРМЭЕФЕкЖўИіЪЎФъРДЃЌЫЦКѕЫќЕФЫйЖШТ§СЫЯТРДЁЃЕЋЪЧITаавЕЕФИїИіаавЕСьЕМепУЧЃЌЛЙЪЧВЛЖЯдкМЦЫуЛњЕФадФмбАЧѓЭЛЦЦЃЌМЬајЬєеНЮяРэМЋЯоЁЃЯИПДДцДЂаавЕЃЌУППюаТЕФДцДЂВњЦЗЕФЭЦГіЃЌвВЮЇШЦзХШчКЮИќПьЁЂИќКУЕФЗўЮёЧАЖЫЗўЮёЦїЕФI/OЧыЧѓЮЊжааФЁЃБОЮФДгI/OЃЈBlockЃЉЕФСїЯђНщЩмЃЌЪдЭМНтЖСећИіI/OСїгыДцДЂадФмжЎМфЕФаЉаэСЊЯЕЁЃБОЮФзїЮЊвЛЦЊДцДЂЛљДЁЕФНщЩмЮФеТЃЌАяжњЖСепСЫНтПДЫЦМђЕЅЕФЪ§ОнЖСаДжаЕФИќЖрЯИНкЁЃ
ДцДЂI/OСїгыДцДЂадФм:
ДцДЂI/OЃЈКѓЮФМђГЦI/OЃЉЕФДІРэЙ§ГЬОЭЪЧМЦЫуЛњдкДцДЂЦїЩЯЖСШЁЪ§ОнКЭаДШыЪ§ОнЕФЙ§ГЬЁЃетжжДцДЂЦїПЩвдЪЧЗЧГжОУадДцДЂЃЈRAMЃЉЃЌвВПЩвдЪЧРрЫЦгВХЬЕФГжОУадДцДЂЁЃвЛИіЭъећЕФI/OПЩвдРэНтЮЊвЛИіЪ§ОнЕЅдЊЭъГЩДгЗЂЦ№ЖЫЕННгЪеЖЫЕФЫЋЯђЕФЙ§ГЬЁЃдкЦѓвЕМЖЕФДцДЂЛЗОГжаЃЌдкетИіЙ§ГЬЛсОЙ§ЖрИіНкЕуЃЌЖјУПИіНкЕужаЖМЛсЪЙгУВЛЭЌЕФЪ§ОнДЋЪфавщЁЃвЛИіЭъећЕФI/OдкУПИіВЛЭЌНкЕуМфЕФДЋЪфЃЌПЩФмЛсБЛВ№ЗжГЩЖрИіI/OЃЌШЛКѓДгвЛИіНкЕуДЋЪфЕНСэЭтвЛИіНкЕуЃЌзюКѓдйОРњЯрЭЌЕФЙ§ГЬЗЕЛидДЖЫЁЃ
ЯТЭМбнЪОСЫвЛИіЮФМўдкОЙ§ећИіI/OТЗОЖжаУПИіНкЕуЫљНјааЕФБфЛЏЃЈвдEMC SymmetrixДцДЂеѓСаЮЊР§ЃЉЃК
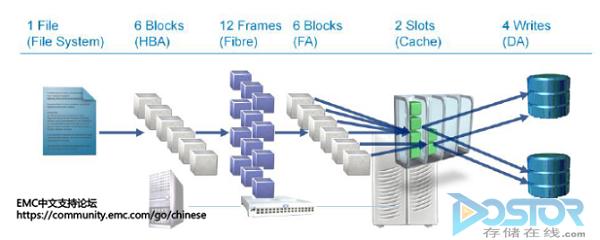
ећИіI/OСїОРњвЛЯТМИИіНкЕуЃК
File System – ЮФМўЯЕЭГЛсИљОнЮФМўгыBlockЕФгГЩфЙиЯЕЃЌЭЈЙ§File System ManagerНЋЮФМўЛЎЗжЮЊЖрИіBlockЃЌЧыЧѓЗЂЫЭИјHBAЁЃ
HBA – HBAжДааЖдетвЛЯЕСаЕФИќаЁЕФЙЄзїЕЅдЊНјааВйзїЃЌНЋетВПЗжI/OзЊЛЛЮЊFibre ChannelавщЃЌАќзАГЩВЛГЌЙ§2KBЕФFrameДЋЪфЕНЯТвЛИіСЌНгНкЕуFC SwitchЁЃ
FC Switch – FC SwitchЛсЭЈЙ§FC FabricЭјТчНЋетаЉFrameЗЂЫЭЕНДцДЂЯЕЭГЕФЧАЖЫПкЃЈFront AdapterЃЉЁЃ
Storage FA – ДцДЂЧАЖЫПкЛсНЋетаЉFC ЕФFrameжиаТЗтзАГЩКЭHBAГѕЪМЗЂЫЭI/OвЛжТЃЌШЛКѓFAЛсНЋЪ§ОнДЋЪфЕНеѓСаЛКДцЃЈStorage Array CacheЃЉ
Storage Array Cache – еѓСаЛКДцДІРэI/OЭЈГЃгаСНжжЧщПіЃК1.жБНгЗЕЛиЪ§ОнвбОаДШыЕФбЖКХИјHBAЃЌетжжНазїЛиаДЃЌвВЪЧДѓЖрЪ§ДцДЂеѓСаДІРэЕФЗНЪНЁЃ2. Ъ§ОнаДШыЛКДцШЛКѓдйЫЂаТЕНЮяРэДХХЬЃЌНазіаДЭИЁЃI/OДцЗХдкЛКДцжавдКѓЃЌНЛгЩКѓЖЫПижЦЦїЃЈDisk AdapterЃЉМЬајДІРэЃЌЭъГЩКѓдйЗЕЛиЪ§ОнвбОаДШыЕФбЖКХИјHBAЁЃ
Disk Adapter – ЩЯЪіСНжжЗНЪНЃЌзюКѓЖМЛсНЋI/OзюКѓаДШыЕНЮяРэДХХЬжаЁЃетИіЙ§ГЬгЩКѓЖЫDisk AdapterПижЦЃЌИљОнКѓЖЫЮяРэДХХЬЕФRAIDМЖБ№ЕФВЛЭЌЃЌвЛИіI/OЛсБфГЩСНИіЛђепЖрИіЪЕМЪЕФI/OЁЃ
ИљОнЩЯЪіЕФI/OСїЯђЕФРДПДЃЌвЛИіЭъећЕФI/OДЋЪфЃЌОЙ§ЕФЛсЯћКФЪБМфЕФНкЕуПЩвдИХРЈЮЊвдЯТМИИіЃК
CPU – RAMЃЌ ЭъГЩжїЛњЮФМўЯЕЭГЕНHBAЕФВйзїЁЃ
HBA – FAЃЌЭъГЩдкЙтЯЫЭјТчжаЕФДЋЪфЙ§ГЬЁЃ
FA – CacheЃЌДцДЂЧАЖЫПЈНЋЪ§ОнаДШыЕНЛКДцЕФЪБМфЁЃ
DA – DriveЃЌДцДЂКѓЖЫПЈНЋЪ§ОнДгЛКДцаДШыЕНЮяРэДХХЬЕФЪБМфЁЃ
ЯТУцЕФБэжаИљОнВЛЭЌНзЖЮЕФЪ§ОнЗУЮЪЪБМфзіСЫвЛИіБШНЯЃЌвЛИі8KBЕФI/OЭъГЩећИіI/OСїЯђЕФДѓИХКФЪБЁЃЃЈБэжаЕФКФЪБИљОнУПУыЕФДЋЪфЪ§ОнећГ§ЛёЕУЃЌР§ШчHBAЕНFAЕФЫйЖШга102,400KB/УыГ§вд8KBЕУЕН78 μsЃЉЁЃИљОнБэжаЕФЪ§ОнЯдЖјвзМћЃЌI/OДгжїЛњЕФЮФМўЯЕЭГПЊЪМДЋЪфЕНДцДЂеѓСаЕФЛКДцдкећИіетИіI/OеМБШКмаЁЃЌгЩгкЛњаЕгВХЬЕФЯожЦЃЌзюДѓЕФКФЪБЛЙЪЧдкDAЕНЮяРэДХХЬЕФЪБМфЁЃШчЙћЪЙгУЩСДцХЬЃЌФЧетИіЪ§ОнЛсДѓЗљЫѕаЁЃЌЕЋЪЧгыЦфЫћМИИіНкЕуЕФДЋЪфЪБМфЯрБШЃЌеМБШЛЙЪЧБШНЯДѓЕФЁЃ
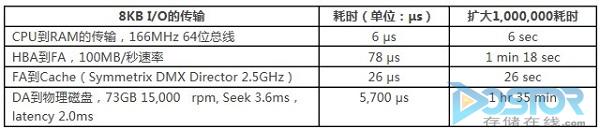
ПЩвдПДЕНЃЌДцДЂеѓСаЕФЛКДцдкећИіI/OСїжаЫљЦ№ЕНЕФзїгУЪЧжСЙиживЊЁЃЛКДцЕФДІРэаЇТЪгыДѓаЁЃЌжБНггАЯьЕНI/OДІРэЕФЫйЖШЁЃЖјШЛЃЌдкЪЕМЪЕФЛЗОГжаЃЌМДЪЙДцДЂеѓСаЕФЛКДцЙЄзїЕУЕБЃЌжїЛњЕФI/OвВВЛЛсДяЕН100 μsвВОЭЪЧ0.1msЕФЫЎЦНЃЌЭЈГЃдк1-3msзѓгвЃЌОЭЛсШЯЮЊI/OДІРэДІгкБШНЯИпадФмЕФФЃЪНЁЃдвђОЭЪЧвђЮЊСэЭтСНИівђЫи“Ъ§ОнЭЗДІРэ”КЭ“ВЂЗЂ”ЁЃ
1. “Ъ§ОнЭЗДІРэ“гЩгкI/OСїжаУПИіI/OЕФЪ§ОнзщГЩВЂВЛЪЧжЛАќКЌЪ§ОнЃЌШчЯТЭМЫљЪОЃЌвЛИіI/OГ§СЫЪ§ОнвдЭтЛЙАќКЌСЫNegotiationЃЌAcknowledgementгУРДИКд№дкI/OСїжаЕФУПИіНкЕуДЋЪфКЭНјааЙмРэЕФЁЃЦфжаАќКЌКЭTCP/IPвЛбљЕФ“Handshaking“аХЯЂвдМАСїПижЦЕФаХЯЂЃЌБШШчГѕЪМЛЏДЋЪфЃЌНсЪјЭЈбЖЕШЕШЁЃHeaderжадђЛсЖЈвхвЛаЉР§ШчCRCаЃбщЕФаХЯЂЃЌБЃжЄЪ§ОнЕФвЛжТадЁЃЫљгаетаЉЪ§ОнЕФДІРэЖМЛсКФЗбвЛЖЈЕФДІРэзЪдДЃЌдіМгI/OСїЕФКФЪБЁЃ

2.“ВЂЗЂ“ЁЃгЩгкI/OСїећИіЙ§ГЬжаВЛПЩФмжЛЭЌЪБДІРэвЛИіI/OЃЌЫљгаЕФI/OдкHBAЃЌFCЃЌFAКЭDAДІРэЕФЙ§ГЬжаЖМЪЧвбДѓСПВЂЗЂЕФЧщПіЯТНјааЁЃЖјжївЊЕФКФЪБШЁОігкI/OЖгСаЕФЕШД§ЃЌЫфШЛДцДЂеѓСаЛсдкВЂЗЂЩЯНјаагХЛЏЁЃЭЌвЛИіДІРэSliceЕФДІРэЛЙЪЧЛсвЛЖгСааЮЪННјааЁЃШыЯТЭМЫљЪОЃЌЕБДцДЂЭЌЪБУцЖдЖрИіI/OЕФДІРэЕФЧщПіЃЌзмЛсгаФГИіI/OЛсдкећИіСїЕФзюКѓГіРДЃЌЖјдіМгI/OЕФКФЪБЁЃЫљвдЫЕЃЌдкI/OСїЕФУПИіНкЕуГіЯжЦПОБЃЌЛђепЖЬАхЕФЪБКђЁЃI/OЕФКФЪБОЭЛсдіМгЁЃ
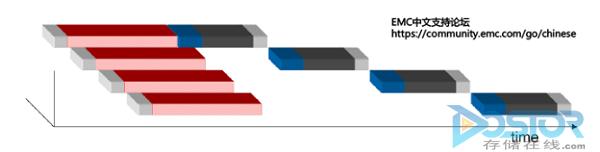
злЩЯЫљЪіЃЌI/OСїгыДцДЂадФмЕФЙиЯЕПЩвдзмНсЮЊвдЯТМИЕуЃК
ЭъГЩвЛИіI/OСїжївЊОРњЙ§ЕФНкЕугаHBAЃЌFCЭјТчЃЌДцДЂЧАЖЫПкFAЃЌДцДЂЛКДцЁЂДцДЂКѓЖЫПкЃЌЮяРэДХХЬЁЃЖјКмИіЙ§ГЬжазюКФЪБЕФЪЧЮяРэДХХЬЁЃ
ДцДЂеѓСаЕФЛКДцЕФДѓаЁКЭДІРэЗНЪНжБНггАЯьЕНI/OСїЕФадФмЃЌвВЪЧЖЈвхвЛИіДцДЂеѓСагХСгЕФживЊжИБъжЎвЛЁЃ
I/OЕФДІРэЫйЖШЭЈГЃЛсдЖРыРэТлжЕЃЌдвђЖрИіВЂЗЂСПНЯДѓЖјдьГЩЕФЖгСабгГйЁЃ
гХЛЏI/OЕФЗНЪНПЩвдДгЖрИіНкЕуШыЪжЃЌЖјзюЯджјЕФаЇЙћЪЧЬсЩ§ЮяРэДХХЬЕФЫйЖШЁЃвђЮЊДцДЂеѓСаЛсАбОЁПЩФмЖрЕФЪ§ОнЗХШыЛКДцЃЌЖјЕБЛКДцгУТњвдКѓЕФЪ§ОнНЛЛЛдђЭъШЋШЁОігкЮяРэДХХЬЕФЫйЖШЁЃ
ЪЪЕБбЁгУКЯЪЪЕФRAIDМЖБ№ЃЌвђЮЊВЛЭЌЕФRAIDМЖБ№ЕФЖСаДБШР§ДѓВЛЯрЭЌЃЌПЩФмЪЙЕУЮяРэДХХЬДІРэКФЪБМИБЖдіМгЁЃВЮПМЃКЧГЬИRAIDаДГЭЗЃЃЈWrite PenaltyЃЉгыIOPSМЦЫу
БОЮФзїепЮЊEMCжаЮФММЪѕЩчЧјЃЈhttps://community.emc.com/go/chineseЃЉММЪѕАцжїЁЃШчЙћФњЖдБОЮФгаШЮКЮвЩЮЪКЭВЛЭЌМћНтЃЌвВЛЖгЕНEMCжаЮФжЇГжТлЬГВЮгыЬжТлЁЃ



