жкжОКЭДяЃКжиИДЪ§ОнЩОГ§ММЪѕНтЮі
жкжОКЭДя ЗЂБэгкЃК13Фъ03дТ19Ше 14:47 [РДИх] ДцДЂдкЯп
ОнЪаГЁЗжЮіЙЋЫОIDCЕФбаОПНсЙћБэУїЃЌ2011ФъДДдьЕФаХЯЂЪ§СПДяЕН1800EBЃЌУПФъВњЩњЕФЪ§зжаХЯЂСПЛЙдквд60%ЕФЫйЖШИпЫйдіГЄЃЌЕН2020ФъЃЌШЋЧђУПФъВњЩњЕФЪ§зжаХЯЂНЋДяЕН35ZBЁЃбИЫйдіГЄЕФЪ§ОнСПЭЛЯдСЫжиИДЪ§ОнЩОГ§ММЪѕ(De-duplication)ЕФживЊадЃЌЫќВЛНіФмЙЛМѕЩйСЫаХЯЂдкЮяРэДцДЂПеМфЕФбЙСІЃЌЖјЧвДѓЗљНЕЕЭСЫЪ§ОнДЋЪфЕФЭјТчДјПэеМгУЁЃ
дкУцЖдДѓЪ§ОнЪБДњЕФНёЬьЃЌжиИДЪ§ОнЩОГ§ММЪѕдйДЮГЩЮЊШШвщЕФЛАЬтЁЃЪзЯШЃЌдЪМЪ§ОнНЋБЛДђЩЂЮЊЪ§ОнПщЃЌВЂНјааЕЅвЛЪЕР§ДцДЂЁЃШчКЮБЃжЄЪ§ОнПщгыжИеые§ШЗЃЌВЛдьГЩЪ§ОнЖЊЪЇЛђЮѓЩОГ§ЃЌЯдЕУЗЧГЃживЊЃЌШЮКЮЪ§ОнПщЕФЖЊЪЇЖМвтЮЖзХКмДѓвЛВПЗжЪ§ОнНЋЮоЗЈевЛиЁЃЦфДЮЃЌШчКЮБЃжЄжиИДЪ§ОнЩОГ§ЕФадФмЃЌЙ§аЁЕФЪ§ОнПщЪЙЕУжиЩОБШТЪЛсдНИпЃЌЕЋКЃСПЕФЪ§ОнПщБШЖдЛсгАЯьдЫЫуадФм;Ъ§ОнЙмРэШЫдБашвЊдкСНепжЎМфевЕНКЯЪЪЕФЦНКтЕуЃЌЭЌбљЪЧвЛГЁВЉоФЃЌМШвЊБЃжЄжиИДЪ§ОнФмЙЛДѓСПЩОГ§ЃЌгжвЊбЁдёФмЙЛНгЪмЕФдЫЫуадФмЁЃ
жкжОКЭДя(гЂЮФSOUL)ЃЌЪЧжаЙњаХЯЂДцДЂЁЂЪ§ОнАВШЋгыгІгУСьгђСьЯШЕФНтОіЗНАИгыЗўЮёЬсЙЉЩЬЃЌгЕгаГЌЙ§15ФъЕФжаЙњБОЭСЪаГЁОбщКЭ3000ЖрМвзюжегУЛЇЁЃ
SOULвдТњзудЦМЦЫуЁЂДѓЪ§ОнЪБДњЦѓвЕПЭЛЇашЧѓЮЊФПБъЃЌМсГжзджїДДаТЃЌгЕгаЛљгкзджїжЊЪЖВњШЈЕФSoC(Storage-on-ChipаОЦЌМЖДцДЂ)ММЪѕЁЂSureSaveжЧФмЛЏДцДЂгыБЃЛЄЙмРэЁЂЗжВМЪНДцДЂгыМЦЫуЙмРэЕШКЫаФММЪѕЃЌЬсЙЉКЃСПЪ§ОнЕФДцДЂЁЂБЃЛЄгыдЦМЦЫуЁЂДѓЪ§ОнЕШгІгУНтОіЗНАИЃЌЮЊЯжДњITгІгУЬсЙЉИпЫйЁЂАВШЋЁЂПЩППЁЂЕЏадЕФЛљДЁМмЙЙЃЌНЋЪ§ОнгыМЦЫуЕФМлжЕГфЗжЗЂЛгЁЃ
ПщМЖБфГЄЫуЗЈЕФИпЫѕМѕБШ
SOULПЊЗЂЕФжиИДЪ§ОнЩОГ§ММЪѕЛљгкПщМЖЁЂБфГЄФЃЪНЃЌВЩгУвЕНчСїааЕФHASHЫуЗЈЃЌвдIn-LineЗНЪНЪЕЯжСЫдкДцДЂЙ§ГЬжаЪЕЯжжиИДЪ§ОнЩОГ§ЙІФмЁЃЮЊЗРжЙжиИДЪ§ОнЩОГ§дЫЫуНЕЕЭзмЬхI/OадФмЃЌЫљгажиИДЪ§ОнЩОГ§дЫЫуОљВЩгУгВМўЪЕЯжЁЃ
ЛљгкПщМЖШЅжиЕФЗНЪНЃК
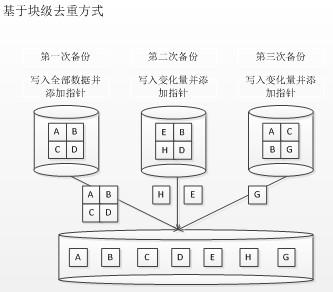
ЭМвЛЃКЛљгкПщМЖШЅжиЗНЪН
ШчЭМвЛЫљЪОЃЌЭМжаЕквЛДЮБИЗнЮЊШЋБИЗнЃЌвдКѓУПДЮжЛБИЗнБфЛЏСПЃЌВЂИјУПИіЪ§ОнПщЬэМгЯргІЕФжИеыЁЃДгаЮЪНЩЯПДЃЌПщМЖШЅжигыЮФМўМЖШЅжидРэЛљБОвЛжТЃЌЕЋЮФМўМЖШЅжиБШЖдЕФЪЧВЛЭЌЮФМўЃЌШчЙћЮФМўФкШнгаБфЛЏЃЌдђБЛЪгЮЊБфЛЏСПНјааБЃДц;ЖјЛљгкЪ§ОнПщШЅжиФЃЪНЮоТлЮФМўЪЧЗёБфЛЏЃЌжЛМЧТМБфЛЏЪ§ОнПщЃЌЖјЮФМўФкШнБфЛЏКѓЃЌЦфБфЛЏЪ§ОнПщВПЗжБЛБЃДцЁЃ
ЛљгкБфГЄШЅжиЕФЗНЪНЃК
дкШЅжиаЇЙћЩЯПДЃЌПщМЖШЅжидЖИпгкЮФМўМЖШЅжиЃЌЖјПщМЖШЅжидђНјвЛВНЩцМАЕНБфГЄгыЖЈГЄЕФЮЪЬтЁЃ
ЖЈГЄЪЧжИЪ§ОнПщДѓаЁЪЧЙЬЖЈЕФЃЌвЛАуЙЬЖЈжЕЮЊ12K—256KВЛЕШЃЌЖдгкЖЈГЄЖјбдЃЌЪ§ОнПщдНаЁЃЌШЅжиТЪдНИпЁЃЖјБфГЄЕФЪ§ОнЧаИюЗНЪНЭЈЙ§ЯргІЕФПщЕФГЄЖШЃЌдйМгЩЯЯргІЕФзжФИЫГађЃЌЭЈЙ§вЛИіШ§ЮЌЕФЫуЗЈНјааЧаИюЁЃ
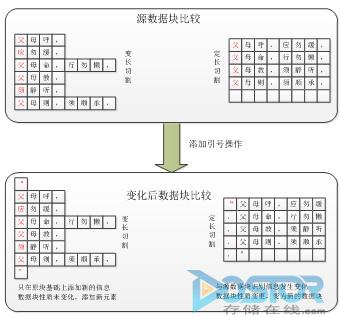
ЭМЖўЃКБфГЄЧаИюгыЖЈГЄЧаИюЕФЖдБШ
ШчЭМЖўЫљЪОЃЌШчЙћЮФМўНјааИФБфЃЌБШШчВхвЛИі“”дкЪ§ОнПщжаЃЌБфГЄЧаИюФЃЪНОЭБфГЩ4ЁЂ4ЁЂ7Ш§аавЛзщЃЌЪЃЯТЕФгжАДее“ИИ”ЪЧгаКЌвхЕФвЛИізжЃЌЧаИюЗНЗЈУЛгаБфЁЃзюКѓЩЈУшЯТРДЃЌжЛгаЪзФЉааЪЧБфЛЏЕФЃЌашвЊБИЗнЪзФЉааетвЛаЁаЁЕФБфЛЏСПЃЌМДЭъГЩСЫБфИќЃЌЖјЪ§ОнСПдіМгЕФНіНіЪЧв§КХЁЃ
ШчЙћЪЧЖЈГЄдђЪзааУЛгаШЮКЮЙцТЩПЩбдЃЌЭъШЋАДееЙЬЖЈДѓаЁНјааЪ§ОнЧаЗжЃЌЕБЬэМгв§КХЪБв§Ц№ећИіЪ§ОнПщБфЖЏЃЌДгЖјЩњГЩСЫаТЕФЪ§ОнПщЁЃДгШЅжиаЇЙћЩЯПДЃЌБфГЄЕФШЅжиТЪвЊИпгкЖЈГЄЁЃ
ЖржиаЃбщЕФИпПЩППад
жиИДЪ§ОнЩОГ§ММЪѕЕФЙиМќдкгкПЩППадЃЌгЩгкЪ§ОнДцДЂЪБКђБЛЧаПщВЂЖдУПИіПщНјааЕЅвЛЪЕР§ДцДЂЃЌФЧУДШЮКЮвЛИіЪ§ОнПщЖЊЪЇЃЌЛђепжИеыДэЮѓЖМЛсдьГЩвЛДѓВПЗжЪ§ОнгРОУЮоЗЈевЛиЁЃЖдгкПЭЛЇЖјбдЃЌЪЧдьГЩВЛПЩЙРМЦЕФЫ№ЪЇЃЌвђДЫШчКЮБЃжЄжиИДЪ§ОнЩОГ§ЕФПЩППадЯдЕУжСЙиживЊЁЃ
SOULЕФжиИДЪ§ОнЩОГ§ММЪѕдкУПвЛВНhashЖдБШЙ§ГЬжаЖМгаCRCаЃбщЃЌБЃжЄСЫУПвЛВНЖдБШжаЪ§ОнЕФе§ШЗад;ЖјУПвЛВНЖдБШЙ§ГЬЖМЛсЖЈЪБгыlogНјааЭЌВНЁЃШчЙћГіЯжВЛЭЌВНЯжЯѓЃЌдђИУВНжшНЋЧхПеМЧТМВЂжиаТв§гУlogаХЯЂЃЌдйДЮжДааБШЖдЙЄзї;ЖјlogдђЖЈЪБгыЕзВуЪ§ОнПтЭЌВНЃЌБЃжЄСЫЪ§ОнгыhashkeyЕФОјЖдвЛжТадЁЃЮЊСЫЗРжЙЗЧЗЈЙиЛњдьГЩЕФЪ§ОнВЛЭЌВНЃЌSOULдкhashЖдБШЕФЕквЛВуЩшжУСЫЦєЖЏЭЌВНЃЌЮоТлЪЧЗёЗЧЗЈЙиЛњЃЌЩшБИдкЦєЖЏКѓЖМЛсНјааздМьЃЌВЂгыlogНјааЭЌВНЃЌНјвЛВНШЗБЃСЫЪ§ОнзМШЗадЁЃ
ЩГТЉЪНЖдБШЛњжЦЕФИпаЇТЪ
жиИДЪ§ОнЩОГ§ММЪѕЪМжеЪЧдкШЅжиБШР§гыадФмжЎМфевЦНКтЃЌШЅжиБШР§дНИпдђБиШЛадФмЫЅМѕдНДѓЃЌЦфдвђдкгкЪ§ОнПщдкЧаПщЪБКђПщдНаЁЃЌГіЯжжиИДЪ§ОнПщЕФМИТЪЛсдНИп;ЖјПщдНаЁдђвтЮЖзХЯрЭЌДѓаЁЕФЪ§ОнБЛЧаИюКѓЃЌВњЩњЕФЪ§ОнПщЕФЪ§СПдНДѓЃЌЖјЪ§ОнПщЪ§СПдНДѓдкhashkeyЖдБШЙ§ГЬжаКФЪБдНГЄЃЌЪЙЕУадФмЫЅМѕдНДѓЁЃвђДЫМДБуВЩгУЕШЭЌЕФБфГЄЗЈдђЧаПщКѓЃЌhashЖдБШЙ§ГЬвВЭЌбљОіЖЈзХадФмЫ№КФЕФГЬЖШЁЃ
SOULЕФжиИДЪ§ОнЩОГ§ММЪѕдкhashЖдБШЙ§ГЬжаВЩгУСЫЩГТЉЪНЕФЖдБШЛњжЦЃЌИУЛњжЦЛсдкЛКДцжаж№МЖЩИбЁжиИДЪ§ОнЁЃзюЩЯВуЛњжЦзізюМђЕЅЕФДжТдХаЖЈЃЌЖЊЕєОјДѓВПЗжжиИДЪ§ОнЃЌНЋПЩФмВЛжиИДЕФЪ§ОнДЋЕнЕНЕкЖўВуМЖ;ЕкЖўВузіЯрЖдЖдБШЃЌХаЖЈhashЪЧЗёвбОАќКЌгкФГИіhashЖЮзщжаЃЌДЫЪБвбОга99%ЕФЪ§ОнНјааСЫdedupeЃЌЖјЪЃЯТЕФ1%ЕФЪ§ОнНЋДЋЕнЕНЕкШ§Ву;ЕкШ§ВуНЋЧАУцУЛгаХаЖЈНсЙћЕФhashгыЯЕЭГШЋВПБЛЪЙгУЙ§ЕФhashНјааЖдБШЃЌДЫДІВХПЊЪМеце§ЖдБШhashЃЌвВОЭЪЧЪЧЯИНкЖдБШЃЌЕкШ§ВуНЋЙ§ТЫЕєЪЃЯТЪ§ОнжаЕФ99.99999%ЃЌзюКѓЪЃЯТШдШЛЮоЗЈХаЖЈЕФдђЛсдкhashПтжаж№вЛВщевНјааЖдБШЁЃ
ЫфШЛЖдБШЙ§ГЬБфГЩСЫ4ВНЃЌЕЋШЅжиаЇТЪШДДѓЗљЬсЩ§ЁЃЭЈЙ§ЪЕМЪШЅжиВтЪдЃЌдкДђПЊжиИДЪ§ОнЩОГ§жЎКѓЃЌДХХЬI/OЪЧЮДПЊЦєжиИДЪ§ОнЩОГ§ЕФ1.06%ЁЃДХХЬI/OОіЖЈСЫвЛИіЯЕЭГЕФадФмЃЌИќЕЭЕФI/OВЛНігааЇЬсИпШЅжиаЇТЪЃЌвВЬсЩ§СЫДХХЬЕФЪЙгУЪйУќЁЃдкВЩгУЖржиЖдБШКѓЃЌЦфЪ§ОнЫѕМѕБШвВДѓЗљЬсЩ§ЃЌЪЕМЪВтЪдЪ§ОнЫѕМѕБШПЩвдГЌЙ§30ЃК1ЁЃ
ФмЙЛНЋДХХЬI/OНЕЕЭЕНвдЩЯГЬЖШжївЊЪЧвђЮЊУПвЛВНдЫЫуЪЧдкФкДцжаНјааЃЌВЂЧвЖМВЩгУдЄЖСШЁЛњжЦЃЌЖјУПвЛВНЖМНЋжЛХаЖЈздМКПЩвдХаЖЈЕФhashЃЌШЮКЮЮоЗЈХаЖЈЕФhashЖМНЛИјКѓУцДІРэЃЌетбљУПвЛВуЪ§ОнЩИбЁЕФаЇТЪНЋДѓЗљЬсЩ§ЃЌДгЖјЬсЩ§ећЬхаЇТЪЁЃ
злЩЯЖјбдЃЌSOULВЩгУЖржжгХЛЏЛњжЦЃЌНтОіСЫИпШЅжиБШР§ЯТадФмЫЅМѕЕФЮЪЬтЃЌЪЕВтдкЯЕЭГадФмЫЅМѕВЛзу5%ЕФЧщПіЯТЪЕЯжСЫГЌЙ§30ЃК1ЕФЪ§ОнЫѕМѕБШЁЃЭЌЪБИпаЇЁЂЖржиЕФаЃбщЛњжЦвВГЙЕзДђЯћПЭЛЇЖджиИДЪ§ОнЩОГ§ПЩППадЕФЕЃаФЁЃ
SOULЮЊДѓЪ§ОнЪБДњДђдьСЫАВШЋПЩППЁЂИпаЇСщЛюЕФЪ§ОнЙмРэгыМЦЫуНтОіЗНАИЃЌвджЧФмЛЏЁЂПЩЭиеЙЕФПЊЗХЪНЯЕЭГЩшМЦЃЌИЈжњгУЛЇЪЕЯжДгДЋЭГITгІгУЯђдЦМЦЫуЁЂДѓЪ§ОнгІгУЕФЦНЛЌЧЈвЦЃЌДгЖјИќМгПьЫйПЊеЙЪ§ОнзЪВњЕФЗжЮіЁЂЭкОђЁЂЙмРэЃЌВЂДгжаЛёШЁЩЬвЕЛњЛсгыОКељгХЪЦЁЃ



