ММЪѕНЧЖШЃКЁЖЫМПМExadataЁЗЮвжЎМћ
IBMЯЕЭГМмЙЙЪІЭѕЮФНм ЗЂБэгкЃК13Фъ03дТ18Ше 14:00 [зЊди] DOIT.com.cn
БОЮФЪЧеыЖдIBMЯЕЭГМмЙЙЪІЭѕЮФНмЯШЩњ(valen_won@hotmail.com)дкЦфВЉПЭдАЕФжУЖЅВЉЮФЫМПМEXADATA(СДНгдЮФЕижЗЃК http://www.cnblogs.com/wenjiewang/archive/2012/10/07/2714406.html)жаЬсЕНЕФвЛаЉЙигкExadataЙлЕуЃЌДгММЪѕНЧЖШИјГіЮвИіШЫЕФвЛаЉВЛЭЌЕФМћНтЃЌЕБШЛБОШЫЫЎЦНгаЯоЃЌФбУтГіЯжЪшТЉЩѕжСДэЮѓЁЃ
вдЯТМђвЊзмНсвЛЯТЮФНмЯШЩњВЉЮФжаЬсЕНЙигкExadataЕФЙлЕуЃК
1. Ъ§ОнВжПт(Data Warehouse)РраЭЕФгІгУЮоЗЈГфЗжРћгУsmart scanЕФЬиадЃЌгШЦфЪЧЖдгкЪ§ОнВжПтжаГЃМћЕФаЧаЭзЊЛЛ(star transformation)ЃЌ ExadataЮоЗЈгХЛЏ;
2. Exadata BugжкЖрЃЌФГаЉаТЬиадУћДцЪЕЭіЃЌВЂОйР§ЫЕУїЦфдкВМТЁЙ§ТЫЦїЕФЪЙгУЙ§ГЬжадтгіЕНЕФbugЁЃ
3. OracleЪ§ОнПтBugжкЖрЃЌЪЙгУExadataЖдгквЕЮёТпМИДдгЃЌЪ§Оне§ШЗадЗЧГЃУєИаЕФН№ШкаавЕДцдкКмДѓЕФЗчЯе;
4. ЮЌЛЄГЩБОИпЃЌвЊЪЙгУExadataЃЌDBAашвЊжиаТбЇЯАДѓСПЕФжїЛњЃЌДцДЂЃЌЭјТчЗНУцЕФжЊЪЖЃЌЗёдђЮоЗЈЪЄШЮвЛЬхЛњЙмРэдБЕФЙЄзї;
5. ЖдгкЖЏщќЕЅБэЩЯАйИізжЖЮЕФЪ§ОнВжПтЖјбдЃЌExadata ЕФStorage IndexаЮЭЌМІРпЃЌвђЮЊЖдгкУПИіБэжЛФмздЖЏЮЌЛЄ8ИіСаЃЌгыБЫЎГЕаНЮовь;
6. ExadataЛЙЪЧRACЃЌ RACЕФshare everythingМмЙЙЕМжТДцдкДѓСПЕФcache fusionељгУЃЌгыOLTPгІгУИёИёВЛШыЁЃ
7. RACЖдERPжЇГжВЛКУЃЌЕМжТКмЖрERPгУЛЇВЛЪЙгУRACЃЌExadataжЛЬсЙЉRACЕФФЃЪНЁЃ
8. ExadataДХХЬШнСПЬЋДѓЃЌЖдгкOLTPЖјбдетМђжБОЭЪЧРЫЗб;
9. ExadataВЛЬсЙЉШЮКЮащФтЛЏММЪѕЃЌВЛФмГфЗжРћгУЦфгВМўзЪдДЃЌЖјЫќЕФОКељЖдЪжШЗЬсЙЉЗЧГЃГЩЪьЕФащФтЛЏНтОіЗНАИ;
10. (етФъЭЗЃЌвЊДеВЛЦыЪЎЬѕГіУХЖМВЛКУвтЫМИњШЫДђеаКє)ExadataЕФМлИёЪЎЗжАКЙѓЃЌЦеЭЈЕФгУЛЇИљБОЮоЗЈГаЪмЁЃ
вдЯТЪЧЮвИіШЫЕФЛигІЃЌВЛДњБэOracleЙЋЫОЕФЙйЗНСЂГЁЁЃOracleЕФsalaryЛЙУЛЕНЮвЯызіOracleЙЋЫО5УЋЕФГхЖЏЁЃ ШчЙћФњАЎПДШэЮФЃЌФЧУДФњПЩвдЧывЦВНLoveunixКЭAIXchinaЃЌвђЮЊФЧРяБШНЯЖрЁЃКмЖрММЪѕЯИНкШ§бдСНгяКмФбНтЪЭЧхГўЕФЃЌЯогкЦЊЗљЃЌетРяСІЧѓМђНщЛђепвЛБЪДјЙ§ЁЃ
1. ЪЕМЪЩЯsmart scanПЩЮНЪЧExadataЫљгаММЪѕЕФКЫаФЃЌРыПЊСЫsmart scanЃЌExadataОЭУЛгаСЫСщЛъЁЃЖјExadataЕФsmart scanЕФЬѕМўЙ§гкПСПЬЃЌвЛжБвдРДБИЪмОКељЖдЪжЕФкИВЁЃЌетИівВЪЧЪТЪЕЁЃ ЕЋЪЧЮФжаЬсЕНЕФ “ШчЙћЮвУЧЕФБЈБэШчЙћВЛЪЧзпFULL TABLE SCANЃЌдђЮоЗЈРћгУЕНетвЛЬиадЁЃИДдгЕФВщбЏЃЌжюШчJoins, sorts, group-bys, aggregationЖМКмПЩФмЮоЗЈРћгУЕНжЧФмЩЈУшЁЃ” етвЛЫЕЗЈЪЧВЛзМШЗЕФЁЃЮветРяВЛбсЦфЗГЕФСаОйвЛЯТФПЧАsmart scanЕФЬѕМўЃК(ЫфШЛетЪЧвЛИіДэЮѓЕФ“ецРэ”)
· Full scans——Table, Partition, Materialized View, Index (FAST FULL SCAN Only)
· Direct Path Reads
· Exadata Storage
ЖдгкНЯИДдгЕФХХађЃЌОлКЯРрЕФВйзїЃЌstorage indexОЭгаЫќЕФгУЮфжЎЕиСЫЁЃжСгкаЧаЮзЊЛЛЃЌзїепЫЕЕФПжХТвВВЛЪЧЪТЪЕЃЌ етЦЊЮФеТКЭетЦЊЮФеТЯъЯИНщЩмСЫдкdata warehouseжа, OracleФкВПЪЧШчКЮЖдаЧаЭзЊЛЛНјаагХЛЏЕФвЛаЉЯИНкЁЃ
2. ВМТЁЙ§ТЫЦїЪЧвЛжжДІРэДѓСПЪ§ОнЕФЙўЯЃЫуЗЈЃЌ ОпЬхЫуЗЈПЩвдВЮПМwikipediaЬѕФП Bloom FilterЃЌ ЛђепВЮПМgoogleЕФЮтОќЯШЩњЕФЁЖЪ§бЇжЎУРЁЗвЛЪщЁЃЕБШЛетРяЬсЕНЕФbugвВЪЧВЛзМШЗЕФЃЌ етРяЬсЕНЕФСНИіbugЃК9124206КЭbug: 8361126ЃЌ ЪЕМЪЩЯЪЧЭЌвЛИіbugМДbase bugЮЊ8361126ЁЃ
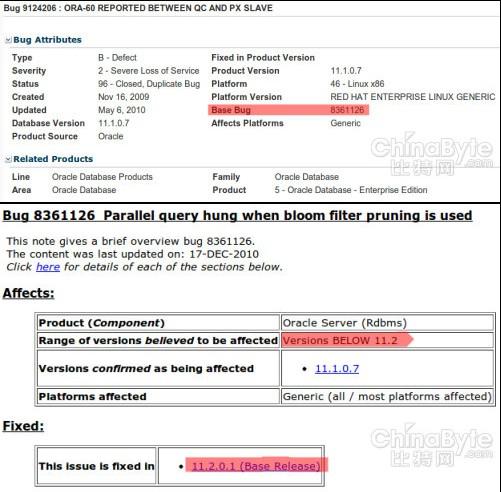
ЮФеТжаСэЭтЬсЕНЕФbloom filterЕФbugгІИУЪЧBug:12637294СЫЃЌЕЋЪЧетИіbugдк11.2.0.3 BP11вбОаоИДЁЃ
СэЭтКмгавтЫМЕФЪЧsmart scanФкВПвВЪЧЪЙгУBloom FilterЕФЫуЗЈНјааЪ§ОнЙ§ТЫЕФЁЃ
3. Oracle BugЖрЪЧжкЫљжмжЊЕФЪТЪЕЃЌ ДгУПДЮЕФPatchset Release/PSUЕФbug listПЩвдПДГіЃЌКмЖрbugЕФЮЃКІвВЗЧГЃДѓЁЃ ЩѕжСзїепЫЕЕФwrong resultвВЭъШЋЪЧЪТЪЕЃЌЕЋЪЧетВЂЗЧЪЧЮодЕЮоЙЪЛсГіЯжЕФЃЌетаЉbugДѓЖМЪЧдквЛаЉМЋЖЫЕФЧщПіЯТДЅЗЂЁЃШчЙћгІгУОЙ§СЫГфЗжЕФВтЪдЃЌФЧУДдђКмЩйЛсгіЕН wrong resultsЁЃ ДЅЗЂwrong results bugБШНЯГЃМћЕФвЛаЉЧщПіЪЧВЂааЃЌ ИДдгЕФБэСЌНгЕШВйзїЁЃMOSгавЛЦЊЮФЕЕЯъЯИЕФНщЩмСЫШчКЮеяЖЯКЭЗжЮіДЫРрЮЪЬтЃК Wrong Results Issues – Recommended Actions [ID 150895.1]ЁЃЫГБуЫЕвЛОфЃК дНРДдНЖрН№ШкаавЕПЭЛЇАбOracleЪ§ОнПтЕБзїКЫаФСЫЁЃ
4. ЮЌЛЄГЩБОЕФЮЪЬтЁЃЮЌЛЄУЛгазїепЫЕЕФФЧУДбЯжиЁЃжїЛњЪЧPC serverЃЌгВМўУЛгаЪВУДЬиЪтжЎДІЁЃВйзїЯЕЭГЪЧLinux X86_64ЃЌКмЖрSA/DBAЖМвбОЗЧГЃЪьЯЄСЫЁЃ ЭјТчЮЌЛЄвВВЂВЛашвЊЖюЭтЕФжЊЪЖЃЌжЛашвЊСЫНтвЛаЉГЃгУЕФinfiniband/ciscoНЛЛЛЛњЕФВйзїЁЃ ExadataЩЯЕФЪ§ОнПтЮЌЛЄгыЦеЭЈЕФRACЪ§ОнПтВЂУЛгаСНбљЁЃЮЈвЛашвЊжиаТбЇЯАЕФЪЧДцДЂЖЫЕФжЊЪЖЃЌ ЖјетвЛВПЗжФкШнКмЖрЖМФмДгЛЅСЊЭјЩЯЛёШЁЕНЁЃ(ЭђвЛЪЕдкЮоЗЈЪЄШЮЃЌOracleЙЋЫОЭЦГіСЫвЛеОЪНАзН№ЗўЮёЃЌгУЛЇПЩвдНЋЙмРэ“ЭтАќ”ИјOracleЙЋЫОЃЌаІЃЌЧыНјШыздЖЏКіТдЙуИцФЃЪН)
5. Storage IndexУПИіБэжЛФмздЖЏЮЌЛЄ8ИіСаетЪЧЪТЪЕЃЌЕЋЪЧетВЂЗЧЪЧЪВУДММЪѕЩЯЕФЯожЦЃЌ Storage IndexКЭNetezzaЕФZone MapsММЪѕдРэЩЯЪЧВЛвЛбљЕФЁЃStorage IndexвЛИіживЊЕФИХФюОЭЪЧжЛЖдХХађзжЖЮЦ№зїгУЃЌЖдгкЮоађЕФзжЖЮЪЧЮоЗЈгУЕНЫќЕФЃЌ ЫљвдStorage IndexУПИіБэГЌЙ§8СаЖдадФмЩЯУЛгаЖрЩйАяжњЃЌвђЮЊвЛИіБэКЫаФВЂЧвашвЊгУгкХХађЕФзжЖЮВЂВЛЖрЁЃ
6. етИіЮЪЬтЪЕМЪЩЯЛЙЪЧshare diskКЭshare nothingЕФМмЙЙжЎељЃЌРЯЕєбРЕФЛАЬтСЫЃЌУЛгаЬЋЖрЪЕМЪвтвхЁЃ
7. ФПЧАаадкOracle DBЩЯЕФSAP ERPдЖБШдЫаадкDB2ЩЯЕФERPвЊЖрЃЌгааЫШЄПЩвдВщПДgartnerЕФЭГМЦЪ§ОнЁЃ
8. ЯждкгВХЬАзВЫМлСЫЃЌЕЅПщХЬОЭ2-3TСЫЃЌЫЛЙдквтетУДвЛЕуПеМф? ПіЧвOLTPгІгУЪ§ОнСПдк1TвдЩЯЕФвВВЛдкЩйЪ§ЁЃ
9. етвЛЬѕЫЕЕФЪЧЪТЪЕЃЌЕЋЪЧ
· vmwareетбљЕФащФтЛЏЦНЬЈФПЧАУЛгаЭЈЙ§OracleШЯжЄ;
· IBM LPARВЛЪєгкбЯИёвтвхЩЯЕФащФтЛЏММЪѕ;
· ExadataЩЯПЩвдЭЈЙ§ЯёIORM/instance cage/cgroupsетбљЕФЗНЪНРДЪЕЯжзЪдДИєРы;
· ЮДРДгІИУЛсПМТЧЪЙгУOracleздМКЕФOVMЁЃ
10. ЯрБШИпЖЫжїЛњ+ИпЖЫДцДЂЖЏщќМИАйЩЯЧЇЭђЃЌ ExadataадМлБШВЛЫуВюАЩ?ЯждкExadata X3ЭЦГіСЫ1/8ХфЃЌПЊЪМЧРздМваЁажЕмODAЕФЗЙЭыСЫЁЃЁЃЁЃ



